 NEWSLETTER
NEWSLETTER
Large language models (LLM) They develop specifically for mathematics, programming and general autonomous agents and require an improvement in the reasoning in trial time. Several approaches include producing reasoning steps in response to some notice or using sampling and training models to generate the same step. Reinforcement learning is more likely to propose self -exploration and the ability to learn from feedback; However, its impact on complex reasoning has remained limited. Escalation LLMS Test time remains a problem because the greatest computational efforts are not necessarily translated into better models. Deep reasoning and longer responses can improve performance, but it has been a challenge to achieve this effectively.
Current methods to improve the reasoning of the language model focus on imitation learning, where models replicate the reasoning steps generated using indications or sampling of rejection. The pre -retreat in data related to reasoning and fine adjustment with reinforcement learning helps improve understanding, but does not scale well for complex reasoning. The techniques subsequent to training, such as generating response-response pairs, and adding verifiers improve precision, but depend largely on external supervision. The scale of the language models through more data and models larger improves performance, but the scale -based scale and the inference of trial time remain ineffective. Repeated sampling increases computational costs without improving reasoning capacity, which makes current techniques inefficient for deeper reasoning and responses long.
To address these problems, Researchers at the University of Tsinghua and ZHIPU ai proposed the T1 method. Improves reinforcement learning by expanding the scope of exploration and improving the inference scale. T1 Start with the training of the language model based on thought chain data with test and error and self -verification. This normally refuses during the training phase by existing methods. Therefore, the model finds the correct answers and includes the steps taken to reach them. Unlike the previous approaches focused on obtaining the correct solutions, T1 fosters various reasoning routes by producing multiple responses to each notice and analyzing errors before reinforcement learning. This framework improves RL training in two ways: first, through overmore, which increases the diversity of response, and second, regulating the stability of training through an auxiliary loss based on entropy. Instead of maintaining a fixed reference model, T1 dynamically updates the reference model using exponential mobile averages so that training cannot become rigid. T1 punishes redundant, too long or low quality responses with a negative reward, maintaining the model on the road to significant reasoning.
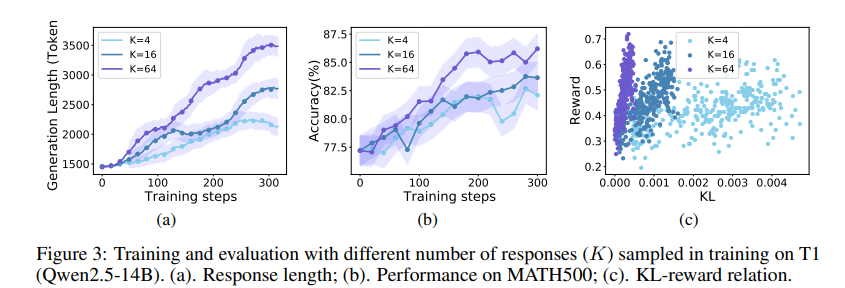
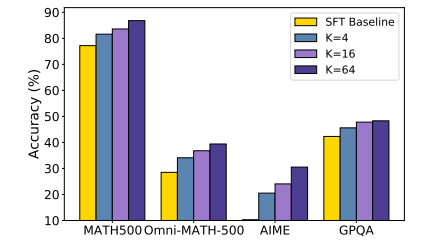
The researchers built T1 using open models such as GLM-4-9b and QWen2.5-14b/32bfocusing on mathematical reasoning through reinforcement learning (RL). Math-Train and Numinamath training data derived, healing 30,000 instances extracting answers and filtering noise data. He Supervised fine (SFT) adjustment Coseno decomposition programming was used, and RL training included policy gradient decrease with correction -based rewards. After evaluation, T1 surpassed its reference models at mathematics reference points, with Qwen2.5-32b showing a 10-20% Improvement of him SFT version. Increase in the number of improved responses (K) improved and generalization, especially for GPQU. A sampling temperature 1.2 Stabilized training, while excessively high or low values led to performance problems. Sanctions were applied during RL training to control the length of the response and improve consistency. The results demonstrated significant performance profits with an inference scale, where more computational resources led to better results.
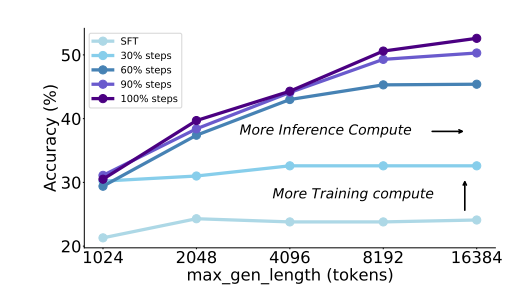
In conclusion, the proposed method T1 Improved Large Language Models Through learning scaled reinforcement with exploration and stability. The sanctions and overmone could soften the influence of bottleneck samples. It showed strong performance and promising scale behavior. The focus to measure the inference scale showed that RL training more improved the precision of reasoning and scale trends. T1 It exceeds avant -garde models at challenging reference points, overcoming weaknesses in current reasoning approaches. This work can be a starting point for greater research, offering a framework to advance reasoning capabilities and climbing large language models.
Verify he Paper and Github page. All credit for this investigation goes to the researchers of this project. Besides, don't forget to follow us <a target="_blank" href="https://x.com/intent/follow?screen_name=marktechpost” target=”_blank” rel=”noreferrer noopener”>twitter and join our Telegram channel and LINKEDIN GRsplash. Do not forget to join our 75K+ ml of submen.
Know Intellagent: A framework of multiple open source agents to evaluate a complex conversational system (Promoted)
Divyesh is a consulting intern in Marktechpost. He is looking for a BTECH in agricultural and food engineering of the Indian Institute of technology, Kharagpur. He is a data science enthusiast and automatic learning that wants to integrate these leading technologies in the agricultural domain and solve challenges.






{kind=link}