
KV-Runahead: Scalable Causal LLM Inference Using Parallel Key-Value Cache Generation
The large language model or LLM inference has two phases, the request (or preload) phase to generate the first token ...

The large language model or LLM inference has two phases, the request (or preload) phase to generate the first token ...
The reproducibility and transparency of large language models are crucial to promote open research, ensure the reliability of results, and ...
On-device machine learning (ML) moves cloud computing to personal devices, protecting user privacy and enabling intelligent user experiences. However, tailoring ...
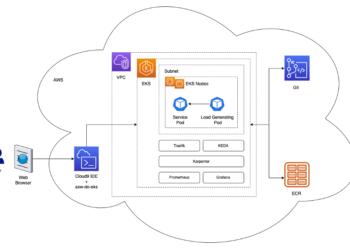
This is a guest post co-written with the leadership team of Iambic Therapeutics. ai/" target="_blank" rel="noopener">Iambic Therapeutics is a drug ...

We are pleased to announce a new release of amazon SageMaker for Kubernetes operators using the AWS Drivers for Kubernetes ...

In January 2024, amazon SageMaker launched a new version (0.26.0) of Large Model Inference (LMI) Deep Learning Containers (DLCs). This ...

Meta, hell-bent on catching up to its rivals in the generative ai space, is spending ai-investment-priority-150500360.html">thousands of millions in their ...

ai/">OctoAI (formerly known as OctoML), today announced the launch of OctoStack, its new end-to-end solution for deploying generative ai models ...

ai-microservices-for-developers" target="_blank" rel="noopener">Nvidia ai-microservices-for-developers" target="_blank" rel="noopener">NIM ai-microservices-for-developers" target="_blank" rel="noopener">meterai-microservices-for-developers" target="_blank" rel="noopener">microservices now integrate with Amazon SageMaker, allowing you to deploy ...

This post is co-written with Justin Miles, Liv d’Aliberti, and Joe Kovba from Leidos. Leidos is a Fortune 500 science and ...




