
Large Language Models (LLM) have quickly become a critical component of today's consumer and enterprise applications. However, the need for rapid token generation remains a persistent challenge, often becoming a bottleneck in emerging applications. For example, the recent trend of inference time scaling uses much longer results to perform searches and other complex algorithms, while multi-agent and pipelined LLM systems aim to improve accuracy and reliability, but both often suffer from long lead times. response due to waiting. for multiple processing stages. Addressing this need for accelerated token generation is crucial to the continued advancement and widespread adoption of LLM-powered applications.
Existing model-based speculative decoding methods have limitations that hinder their ability to effectively address the challenge of accelerating token generation in LLMs. First, these methods are highly dependent on the size and quality of the draft model, which may not always be available, requiring expensive training or adjustments to create a suitable model. Second, integrating scratch models and LLM on GPUs can introduce complications and inefficiencies, such as conflicts between the scratch model's memory usage and the LLM's key-value cache. To address these issues, recent work has explored incorporating additional decoding heads directly within the LLM to perform speculative decoding. However, these approaches still face similar challenges, as the additional heads require tuning for each LLM and consume a significant amount of GPU memory. Overcoming these limitations is crucial to developing more robust and efficient techniques to accelerate LLM inference.
Researchers from Snowflake ai Research and Carnegie Mellon University present SuffixDecodinga robust model-free approach that avoids the need for preliminary models or additional decoding heads. Instead of relying on separate models, SuffixDecoding uses efficient suffix tree indexes created from previous result generations and the current inference request in progress. The process begins by tokenizing each question-answer pair using the LLM vocabulary, extracting all possible suffixes (subsequences from any position to the end) to build the suffix tree structure. Each node in the tree represents a token and the path from the root to any node corresponds to a subsequence that appeared in the training data. This model-free approach eliminates the complications and GPU overhead associated with integrating draft models or additional decoding heads, presenting a more efficient alternative for accelerating LLM inference.
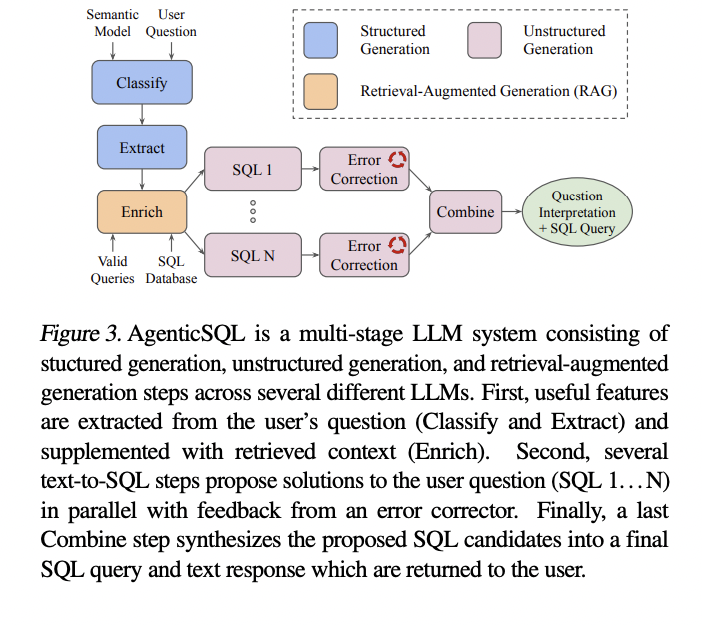
For each new inference request, SuffixDecoding constructs a separate per-request suffix tree from the current request tokens. This design is crucial for tasks where the LLM output is expected to reference or reuse the content of the input message, such as document summarization, question answering, multi-turn chat conversations, and code editing. . The suffix tree maintains frequency counts at each node to track how frequently different sequences of tokens occur, allowing for efficient pattern matching. Given any sequence of recent tokens from the current generation, SuffixDecoding can quickly traverse the tree to find all possible continuations that appeared in the message or in previous outputs. At each inference step, SuffixDecoding selects the best continuation token subtrees based on frequency statistics and empirical probability. These speculated tokens are then passed to the LLM for verification, which is carried out in a single forward step thanks to a tree attention operator with a topology-aware causal mask.
Similar to previous work such as LLMA and Prompt Lookup Decoding, SuffixDecoding is a model-free approach that obtains candidate sequences from a reference corpus. However, unlike previous methods that only considered small reference texts, such as a handful of fragments or simply the current message, SuffixDecoding is designed to use a much larger scale corpus, consisting of hundreds or even thousands of generated results. previously.
By operating on this larger reference corpus, SuffixDecoding can use frequency statistics in a more principled way to select potential candidate sequences. To enable rapid production of these candidate sequences, SuffixDecoding builds a suffix tree on top of its reference corpus. The root node of the tree represents the beginning of a suffix of any document in the corpus, where a document is the result of a previous inference or the message and the result of the current inference in progress. The path from the root to each node represents a subsequence that appears in the reference corpus, and each child node represents a possible continuation of the token.
SuffixDecoding uses this suffix tree structure to perform efficient pattern matching. Given the message plus the tokens generated from the current inference, it identifies a pattern sequence and traverses the suffix tree to find all possible continuations that appeared in the reference corpus. While this can produce a large set of candidate sequences, SuffixDecoding employs a greedy scoring and expansion procedure to construct a smaller, more likely speculation tree, which is then used in the final tree-based speculative decoding step.
The end-to-end experimental results demonstrate the strengths of the SuffixDecoding approach. On the AgenticSQL dataset, which represents a complex, multi-stage LLM pipeline, SuffixDecoding achieves up to 2.9x higher output throughput and up to 3x lower time-per-token (TPOT) latency compared to the baseline by SpecInfer. For more open tasks, such as chat and code generation, SuffixDecoding still offers solid performance, with up to 1.4x higher throughput and 1.1x lower TPOT latency than SpecInfer.
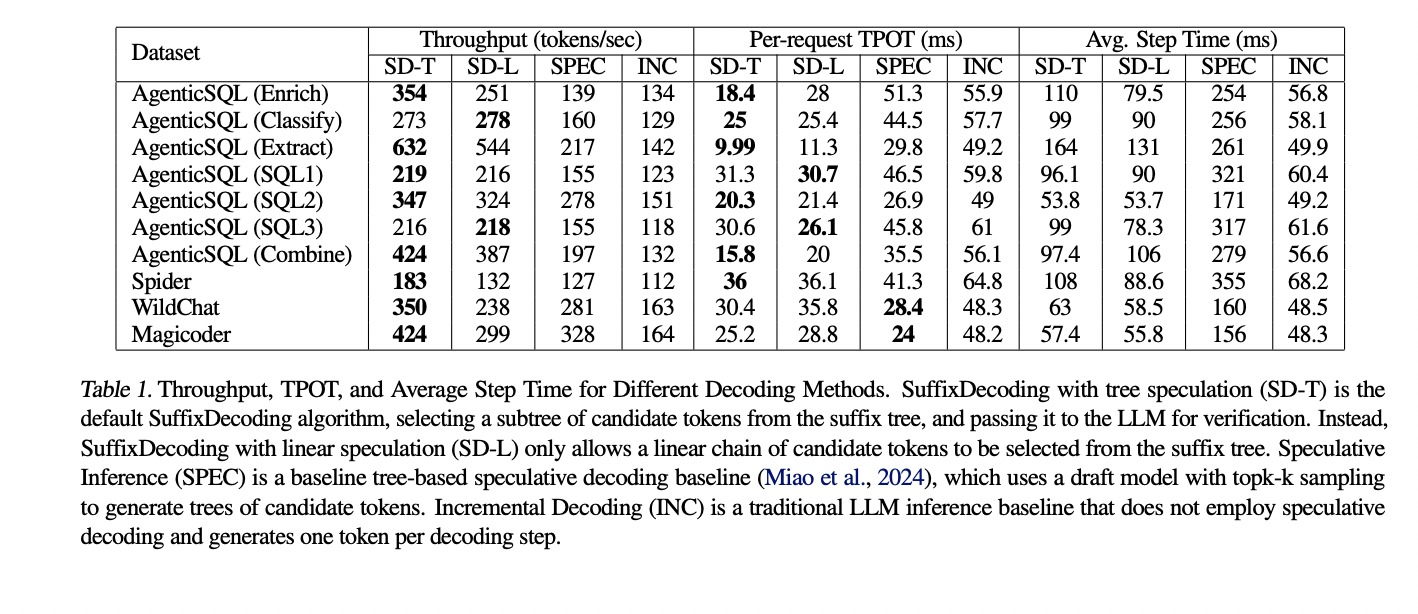
The evaluation also examines the effectiveness of SuffixDecoding's speculative decoding capabilities. SuffixDecoding can achieve a significantly higher average number of accepted specular tokens per verification step compared to the draft model-based SpecInfer approach. This indicates that SuffixDecoding's model-free suffix tree structure allows for more accurate and reliable speculative token generation, maximizing the potential speedup of speculative decoding without the overhead of maintaining a separate scratch model.
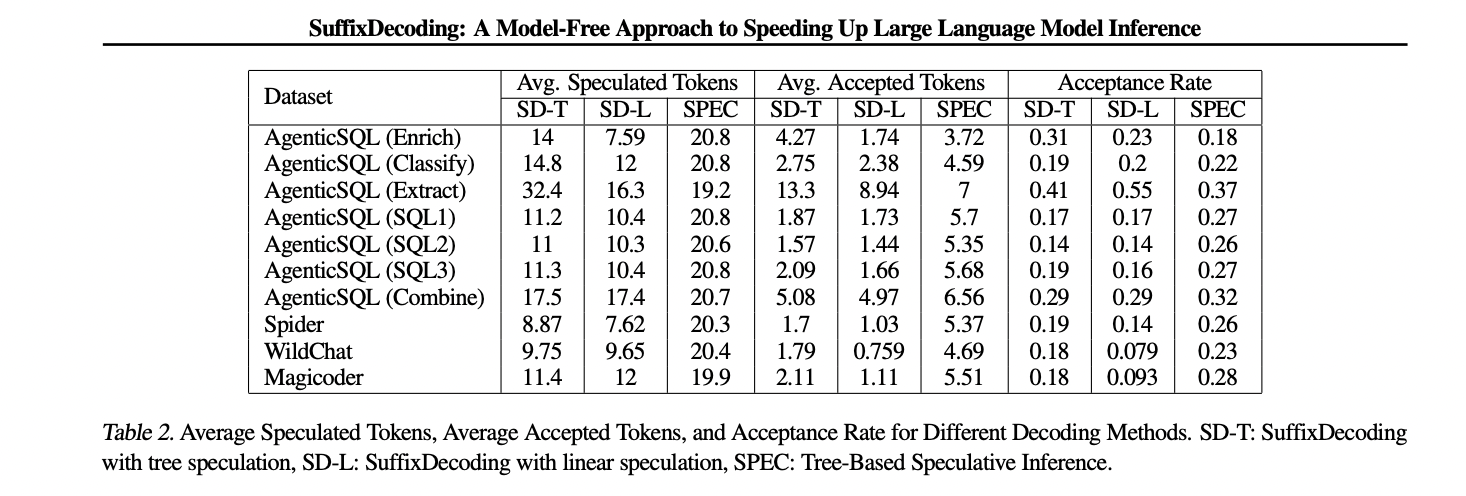
This work presents SuffixDecodinga model-free approach to speed up LLM inference by using suffix trees built from previous results. SuffixDecoding achieves competitive speedups over existing model-based speculative decoding methods in various workloads while being particularly suitable for complex, multi-stage LLM processes. By scaling the reference corpus rather than relying on preliminary models, SuffixDecoding demonstrates a strong direction for improving the efficiency of speculative decoding and unlocking the full potential of large language models in real-world applications.
look at the Details here. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on <a target="_blank" href="https://twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. If you like our work, you will love our information sheet.. Don't forget to join our SubReddit over 55,000ml.
(<a target="_blank" href="https://landing.deepset.ai/webinar-implementing-idp-with-genai-in-financial-services?utm_campaign=2411%20-%20webinar%20-%20credX%20-%20IDP%20with%20GenAI%20in%20Financial%20Services&utm_source=marktechpost&utm_medium=newsletter” target=”_blank” rel=”noreferrer noopener”>FREE WEBINAR on ai) <a target="_blank" href="https://landing.deepset.ai/webinar-implementing-idp-with-genai-in-financial-services?utm_campaign=2411%20-%20webinar%20-%20credX%20-%20IDP%20with%20GenAI%20in%20Financial%20Services&utm_source=marktechpost&utm_medium=newsletter” target=”_blank” rel=”noreferrer noopener”>Implementation of intelligent document processing with GenAI in financial services and real estate transactions
Asjad is an internal consultant at Marktechpost. He is pursuing B.tech in Mechanical Engineering from Indian Institute of technology, Kharagpur. Asjad is a machine learning and deep learning enthusiast who is always researching applications of machine learning in healthcare.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}