 NEWSLETTER
NEWSLETTER
As democratization of foundation models (FMs) becomes more prevalent and demand for ai-augmented services increases, software as a service (SaaS) providers are looking to use machine learning (ML) platforms that support multiple tenants—for data scientists internal to their organization and external customers. More and more companies are realizing the value of using FMs to generate highly personalized and effective content for their customers. Fine-tuning FMs on your own data can significantly boost model accuracy for your specific use case, whether it be sales email generation using page visit context, generating search answers tailored to a company’s services, or automating customer support by training on historical conversations.
Providing generative ai model hosting as a service enables any organization to easily integrate, pilot test, and deploy FMs at scale in a cost-effective manner, without needing in-house ai expertise. This allows companies to experiment with ai use cases like hyper-personalized sales and marketing content, intelligent search, and customized customer service workflows. By using hosted generative models fine-tuned on trusted customer data, businesses can deliver the next level of personalized and effective ai applications to better engage and serve their customers.
Amazon SageMaker offers different ML inference options, including real-time, asynchronous, and batch transform. This post focuses on providing prescriptive guidance on hosting FMs cost-effectively at scale. Specifically, we discuss the quick and responsive world of real-time inference, exploring different options for real-time inference for FMs.
For inference, multi-tenant ai/ML architectures need to consider the requirements for data and models, as well as the compute resources that are required to perform inference from these models. It’s important to consider how multi-tenant ai/ML models are deployed—ideally, in order to optimally utilize CPUs and GPUs, you have to be able to architect an inferencing solution that can enhance serving throughput and reduce cost by ensuring that models are distributed across the compute infrastructure in an efficient manner. In addition, customers are looking for solutions that help them deploy a best-practice inferencing architecture without needing to build everything from scratch.
SageMaker Inference is a fully managed ML hosting service. It supports building generative ai applications while meeting regulatory standards like FedRAMP. SageMaker enables cost-efficient scaling for high-throughput inference workloads. It supports diverse workloads including real-time, asynchronous, and batch inferences on hardware like AWS Inferentia, AWS Graviton, NVIDIA GPUs, and Intel CPUs. SageMaker gives you full control over optimizations, workload isolation, and containerization. It enables you to build generative ai as a service solution at scale with support for multi-model and multi-container deployments.
Challenges of hosting foundation models at scale
The following are some of the challenges in hosting FMs for inference at scale:
- Large memory footprint – FMs with tens or hundreds of billions of model parameters often exceed the memory capacity of a single accelerator chip.
- Transformers are slow – Autoregressive decoding in FMs, especially with long input and output sequences, exacerbates memory I/O operations. This culminates in unacceptable latency periods, adversely affecting real-time inference.
- Cost – FMs necessitate ML accelerators that provide both high memory and high computational power. Achieving high throughput and low latency without sacrificing either is a specialized task, requiring a deep understanding of hardware-software acceleration co-optimization.
- Longer time-to-market – Optimal performance from FMs demands rigorous tuning. This specialized tuning process, coupled with the complexities of infrastructure management, results in elongated time-to-market cycles.
- Workload isolation – Hosting FMs at scale introduces challenges in minimizing the blast-radius and handling noisy neighbors. The ability to scale each FM in response to model-specific traffic patterns requires heavy lifting.
- Scaling to hundreds of FMs – Operating hundreds of FMs simultaneously introduces substantial operational overhead. Effective endpoint management, appropriate slicing and accelerator allocation, and model-specific scaling are tasks that compound in complexity as more models are deployed.
Fitness functions
Deciding on the right hosting option is important because it impacts the end-users rendered by your applications. For this purpose, we’re borrowing the concept of fitness functions, which was coined by Neal Ford and his colleagues from AWS Partner Thought Works in their work Building Evolutionary Architectures. Fitness functions provide a prescriptive assessment of various hosting options based on your objectives. Fitness functions help you obtain the necessary data to allow for the planned evolution of your architecture. They set measurable values to assess how close your solution is to achieving your set goals. Fitness functions can and should be adapted as the architecture evolves to guide a desired change process. This provides architects with a tool to guide their teams while maintaining team autonomy.
We propose considering the following fitness functions when it comes to selecting the right FM inference option at scale and cost-effectively:
- Foundation model size – FMs are based on transformers. Transformers are slow and memory-hungry on generating long text sequences due to the sheer size of the models. Large language models (LLMs) are a type of FM that, when used to generate text sequences, need immense amounts of computing power and have difficulty accessing the available high bandwidth memory (HBM) and compute capacity. This is because a large portion of the available memory bandwidth is consumed by loading the model’s parameters and by the auto-regressive decoding process. As a result, even with massive amounts of compute power, FMs are limited by memory I/O and computation limits. Therefore, model size determines a lot of decisions, such as whether the model will fit on a single accelerator or require multiple ML accelerators using model sharding on the instance to run the inference at a higher throughput. Models with more than 3 billion parameters will generally start requiring multiple ML accelerators because the model might not fit into a single accelerator device.
- Performance and FM inference latency – Many ML models and applications are latency critical, in which the inference latency must be within the bounds specified by a service-level objective. FM inference latency depends on a multitude of factors, including:
- FM model size – Model size, including quantization at runtime.
- Hardware – Compute (TFLOPS), HBM size and bandwidth, network bandwidth, intra-instance interconnect speed, and storage bandwidth.
- Software environment – Model server, model parallel library, model optimization engine, collective communication performance, model network architecture, quantization, and ML framework.
- Prompt – Input and output length and hyperparameters.
- Scaling latency – Time to scale in response to traffic.
- Cold start latency – Features like pre-warming the model load can reduce the cold start latency in loading the FM.
- Workload isolation – This refers to workload isolation requirements from a regulatory and compliance perspective, including protecting confidentiality and integrity of ai models and algorithms, confidentiality of data during ai inference, and protecting ai intellectual property (IP) from unauthorized access or from a risk management perspective. For example, you can reduce the impact of a security event by purposefully reducing the blast-radius or by preventing noisy neighbors.
- Cost-efficiency – To deploy and maintain an FM model and ML application on a scalable framework is a critical business process, and the costs may vary greatly depending on choices made about model hosting infrastructure, hosting option, ML frameworks, ML model characteristics, optimizations, scaling policy, and more. The workloads must utilize the hardware infrastructure optimally to ensure that the cost remains in check. This fitness function specifically refers to the infrastructure cost, which is part of the overall total cost of ownership (TCO). The infrastructure costs are the combined costs for storage, network, and compute. It’s also critical to understand other components of TCO, including operational costs and security and compliance costs. Operational costs are the combined costs of operating, monitoring, and maintaining the ML infrastructure. The operational costs are calculated as the number of engineers required based on each scenario and the annual salary of engineers, aggregated over a specific period. They automatically scale to zero per model when there’s no traffic to save costs.
- Scalability – This includes:
- Operational overhead in managing hundreds of FMs for inference in a multi-tenant platform.
- The ability to pack multiple FMs in a single endpoint and scale per model.
- Enabling instance-level and model container-level scaling based on workload patterns.
- Support for scaling to hundreds of FMs per endpoint.
- Support for the initial placement of the models in the fleet and handling insufficient accelerators.
Representing the dimensions in fitness functions
We use a spider chart, also sometimes called a radar chart, to represent the dimensions in the fitness functions. A spider chart is often used when you want to display data across several unique dimensions. These dimensions are usually quantitative, and typically range from zero to a maximum value. Each dimension’s range is normalized to one another, so that when we draw our spider chart, the length of a line from zero to a dimension’s maximum value will be the same for every dimension.
The following chart illustrates the decision-making process involved when choosing your architecture on SageMaker. Each radius on the spider chart is one of the fitness functions that you will prioritize when you build your inference solution.
Ideally, you’d like a shape that is equilateral across all sides (a pentagon). That shows that you are able to optimize across all fitness functions. But the reality is that it will be challenging to achieve that shape—as you prioritize one fitness function, it will affect the lines for the other radius. This means there will always be trade-offs depending on what is most important for your generative ai application, and you’ll have a graph that will be skewed towards a specific radius. This is the criteria that you may be willing to de-prioritize in favor of the others depending on how you view each function. In our chart, each fitness function’s metric weight is defined as such—the lower the value, the less optimal it is for that fitness function (with the exception of model size, in which case the higher the value, the larger the size of the model).
For example, let’s take a use case where you would like to use a large summarization model (such as Anthropic Claude) to create work summaries of service cases and customer engagements based on case data and customer history. We have the following spider chart.
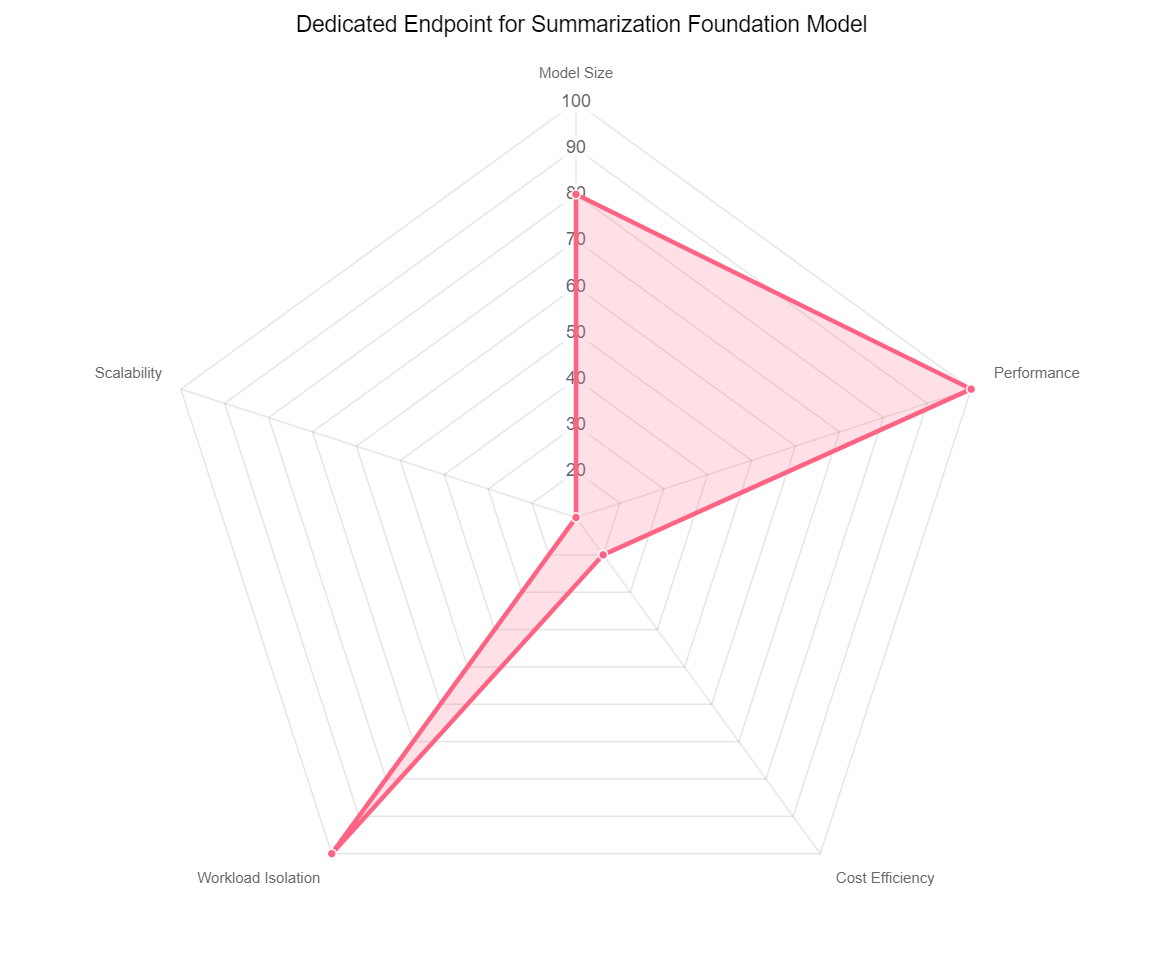
Because this may involve sensitive customer data, you’re choosing to isolate this workload from other models and host it on a single-model endpoint, which can make it challenging to scale because you have to spin up and manage separate endpoints for each FM. The generative ai application you’re using the model with is being used by service agents in real time, so latency and throughput are a priority, hence the need to use larger instance types, such as a P4De. In this situation, the cost may have to be higher because the priority is isolation, latency, and throughput.
Another use case would be a service organization building a Q&A chatbot application that is customized for a large number of customers. The following spider chart reflects their priorities.
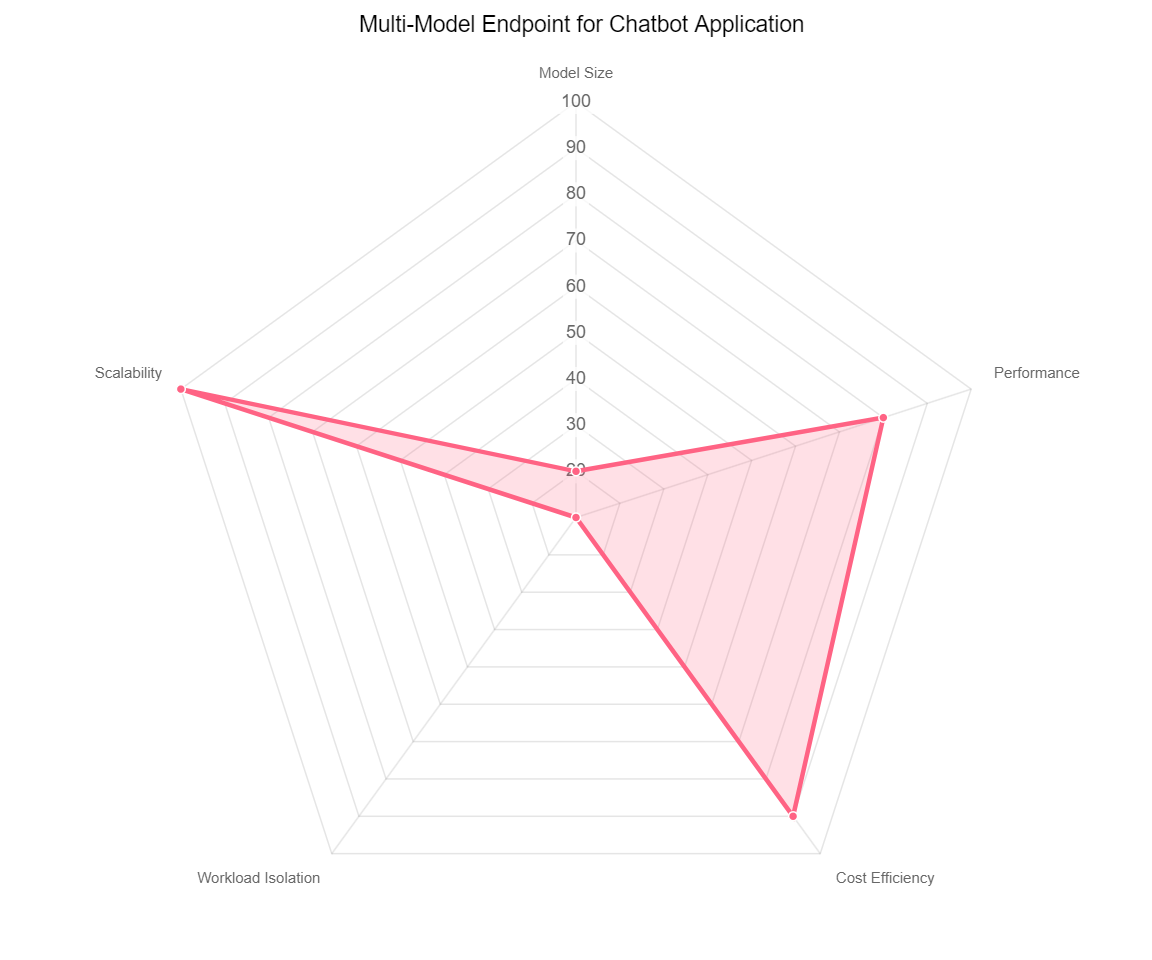
Each chatbot experience may need to be tailored to each specific customer. The models being used may be relatively smaller (FLAN-T5-XXL, Llama 7B, and k-NN), and each chatbot operates at a designated set of hours for different time zones each day. The solution may also have Retrieval Augmented Generation (RAG) incorporated with a database containing all the knowledge base items to be used with inference in real time. There isn’t any customer-specific data being exchanged through this chatbot. Cold start latencies are tolerable because the chatbots operate on a defined schedule. For this use case, you can choose a multi-model endpoint architecture, and may be able minimize cost by using smaller instance types (like a G5) and potentially reduce operational overhead by hosting multiple models on each endpoint at scale. With the exception of workload isolation, fitness functions in this use case may have more of an even priority, and trade-offs are minimized to an extent.
One final example would be an image generation application using a model like Stable Diffusion 2.0, which is a 3.5-billion-parameter model. Our spider chart is as follows.
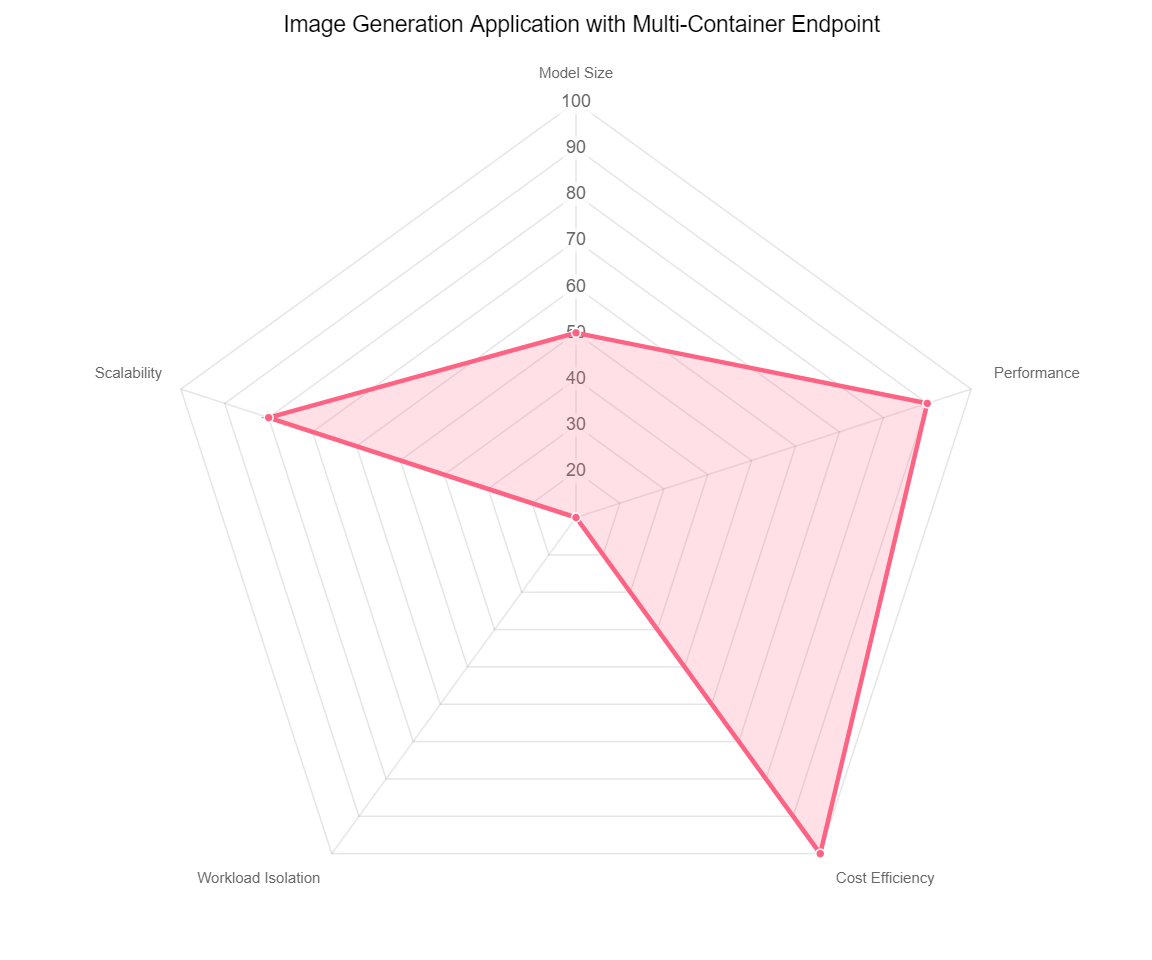
This is a subscription-based application serving thousands of FMs and customers. The response time needs to be quick because each customer expects a fast turnaround of image outputs. Throughput is critical as well because there will be hundreds of thousands of requests at any given second, so the instance type will have to be a larger instance type, like a P4D that has enough GPU and memory. For this you can consider building a multi-container endpoint hosting multiple copies of the model to denoise image generation from one request set to another. For this use case, in order to prioritize latency and throughput and accommodate user demand, cost of compute and workload isolation will be the trade-offs.
Applying fitness functions to selecting the FM hosting option
In this section, we show you how to apply the preceding fitness functions in selecting the right FM hosting option on SageMaker FMs at scale.
SageMaker single-model endpoints
SageMaker single-model endpoints allow you to host one FM on a container hosted on dedicated instances for low latency and high throughput. These endpoints are fully managed and support auto scaling. You can configure the single-model endpoint as a provisioned endpoint where you pass in endpoint infrastructure configuration such as the instance type and count, where SageMaker automatically launches compute resources and scales them in and out depending on the auto scaling policy. You can scale to hosting hundreds of models using multiple single-model endpoints and employ a cell-based architecture for increased resiliency and reduced blast-radius.
When evaluating fitness functions for a provisioned single-model endpoint, consider the following:
- Foundation model size – This is suitable if you have models that can’t fit into single ML accelerator’s memory and therefore need multiple accelerators in an instance.
- Performance and FM inference latency – This is relevant for latency-critical generative ai applications.
- Workload isolation – Your application may need Amazon Elastic Compute Cloud (Amazon EC2) instance-level isolation due to security compliance reasons. Each FM will get a separate inference endpoint and won’t share the EC2 instance with another other model. For example, you can isolate a HIPAA-related model inference workload (such as a PHI detection model) in a separate endpoint with a dedicated security group configuration with network isolation. You can isolate your GPU-based model inference workload from others based on Nitro-based EC2 instances like p4dn in order to isolate them from less trusted workloads. The Nitro System-based EC2 instances provide a unique approach to virtualization and isolation, enabling you to secure and isolate sensitive data processing from AWS operators and software at all times. It provides the most important dimension of confidential computing as an intrinsic, on-by-default set of protections from the system software and cloud operators. This option also supports deploying AWS Marketplace models provided by third-party model providers on SageMaker.
SageMaker multi-model endpoints
SageMaker multi-model endpoints (MMEs) allow you to co-host multiple models on a GPU core, share GPU instances behind an endpoint across multiple models, and dynamically load and unload models based on the incoming traffic. With this, you can significantly save cost and achieve the best price-performance.
MMEs are the best choice if you need to host smaller models that can all fit into a single ML accelerator on an instance. This strategy should be considered if you have a large number (up to thousands) of similar sized (fewer than 1 billion parameters) models that you can serve through a shared container within an instance and don’t need to access all the models at the same time. You can load the model that needs to be used and then unload it for a different model.
MMEs are also designed for co-hosting models that use the same ML framework because they use the shared container to load multiple models. Therefore, if you have a mix of ML frameworks in your model fleet (such as PyTorch and TensorFlow), a SageMaker endpoint with InferenceComponents is a better choice. We discuss InferenceComponents more later in this post.
Finally, MMEs are suitable for applications that can tolerate an occasional cold start latency penalty because infrequently used models can be off-loaded in favor of frequently invoked models. If you have a long tail of infrequently accessed models, a multi-model endpoint can efficiently serve this traffic and enable significant cost savings.
Consider the following when assessing when to use MMEs:
- Foundation model size – You may have models that fit into single ML accelerator’s HBM on an instance and therefore don’t need multiple accelerators.
- Performance and FM inference latency – You may have generative ai applications that can tolerate cold start latency when the model is requested and is not in the memory.
- Workload isolation – Consider having all the models share the same container.
- Scalability – Consider the following:
- You can pack multiple models in a single endpoint and scale per model and ML instance.
- You can enable instance-level auto scaling based on workload patterns.
- MMEs support scaling to thousands of models per endpoint. You don’t need to maintain per-model auto scaling and deployment configuration.
- You can use hot deployment whenever the model is requested by the inference request.
- You can load the models dynamically as per the inference request and unload in response to memory pressure.
- You can time share the underlying the resources with the models.
- Cost-efficiency – Consider time sharing the resource across the models by dynamic loading and unloading of the models, resulting in cost savings.
SageMaker inference endpoint with InferenceComponents
The new SageMaker inference endpoint with InferenceComponents provides a scalable approach to hosting multiple FMs in a single endpoint and scaling per model. It provides you with fine-grained control to allocate resources (accelerators, memory, CPU) and set auto scaling policies on a per-model basis to get assured throughput and predictable performance, and you can manage the utilization of compute across multiple models individually. If you have a lot of models of varying sizes and traffic patterns that you need to host, and the model sizes don’t allow them to fit in a single accelerator’s memory, this is the best option. It also allows you to scale to zero to save costs, but your application latency requirements need to be flexible enough to account for a cold start time for models. This option allows you the most flexibility in utilizing your compute as long as container-level isolation per customer or FM is sufficient. For more details on the new SageMaker endpoint with InferenceComponents, refer to the detailed post Reduce model deployment costs by 50% on average using the latest features of Amazon SageMaker.
Consider the following when determining when you should use an endpoint with InferenceComponents:
- Foundation model size – This is suitable for models that can’t fit into single ML accelerator’s memory and therefore need multiple accelerators in an instance.
- Performance and FM inference latency – This is suitable for latency-critical generative ai applications.
- Workload isolation – You may have applications where container-level isolation is sufficient.
- Scalability – Consider the following:
- You can pack multiple FMs in a single endpoint and scale per model.
- You can enable instance-level and model container-level scaling based on workload patterns.
- This method supports scaling to hundreds of FMs per endpoint. You don’t need to configure the auto scaling policy for each model or container.
- It supports the initial placement of the models in the fleet and handling insufficient accelerators.
- Cost-efficiency – You can scale to zero per model when there is no traffic to save costs.
Packing multiple FMs on same endpoint: Model grouping
Determining what inference architecture strategy you employ on SageMaker depends on your application priorities and requirements. Some SaaS providers are selling into regulated environments that impose strict isolation requirements—they need to have an option that enables them to offer to some or all of their FMs the option of being deployed in a dedicated model. But in order to optimize costs and gain economies of scale, SaaS providers need to also have multi-tenant environments where they host multiple FMs across a shared set of SageMaker resources. Most organizations will probably have a hybrid hosting environment where they have both single-model endpoints and multi-model or multi-container endpoints as part of their SageMaker architecture.
A critical exercise you will need to perform when architecting this distributed inference environment is to group your models for each type of architecture, you’ll need to set up in your SageMaker endpoints. The first decision you’ll have to make is around workload isolation requirements—you will need to isolate the FMs that need to be in their own dedicated endpoints, whether it’s for security reasons, reducing the blast-radius and noisy neighbor risk, or meeting strict SLAs for latency.
Secondly, you’ll need to determine whether the FMs fit into a single ML accelerator or require multiple accelerators, what the model sizes are, and what their traffic patterns are. Similar sized models that collectively serve to support a central function could logically be grouped together by co-hosting multiple models on an endpoint, because these would be part of a single business application that is managed by a central team. For co-hosting multiple models on the same endpoint, a grouping exercise needs to be performed to determine which models can sit in a single instance, a single container, or multiple containers.
Grouping the models for MMEs
MMEs are best suited for smaller models (fewer than 1 billion parameters that can fit into single accelerator) and are of similar in size and invocation latencies. Some variation in model size is acceptable; for example, Zendesk’s models range from 10–50 MB, which works fine, but variations in size that are a factor of 10, 50, or 100 times greater aren’t suitable. Larger models may cause a higher number of loads and unloads of smaller models to accommodate sufficient memory space, which can result in added latency on the endpoint. Differences in performance characteristics of larger models could also consume resources like CPU unevenly, which could impact other models on the instance.
The models that are grouped together on the MME need to have staggered traffic patterns to allow you to share compute across the models for inference. Your access patterns and inference latency also need to allow for some cold start time as you switch between models.
The following are some of the recommended criteria for grouping the models for MMEs:
- Smaller models – Use models with fewer than 1 billion parameters
- Model size – Group similar sized models and co-host into the same endpoint
- Invocation latency – Group models with similar invocation latency requirements that can tolerate cold starts
- Hardware – Group the models using the same underlying EC2 instance type
Grouping the models for an endpoint with InferenceComponents
A SageMaker endpoint with InferenceComponents is best suited for hosting larger FMs (over 1 billion parameters) at scale that require multiple ML accelerators or devices in an EC2 instance. This option is suited for latency-sensitive workloads and applications where container-level isolation is sufficient. The following are some of the recommended criteria for grouping the models for an endpoint with multiple InferenceComponents:
- Hardware – Group the models using the same underlying EC2 instance type
- Model size – Grouping the model based on model size is recommended but not mandatory
Summary
In this post, we looked at three real-time ML inference options (single endpoints, multi-model endpoints, and endpoints with InferenceComponents) in SageMaker to efficiently host FMs at scale cost-effectively. You can use the five fitness functions to help you choose the right SageMaker hosting option for FMs at scale. Group the FMs and co-host them on SageMaker inference endpoints using the recommended grouping criteria. In addition to the fitness functions we discussed, you can use the following table to decide which shared SageMaker hosting option is best for your use case. You can find code samples for each of the FM hosting options on SageMaker in the following GitHub repos: single SageMaker endpoint, multi-model endpoint, and InferenceComponents endpoint.
| . | Single-Model Endpoint | Multi-Model Endpoint | Endpoint with InferenceComponents |
| Model lifecycle | API for management | Dynamic through Amazon S3 path | API for management |
| Instance types supported | CPU, single and multi GPU, AWS Inferentia based Instances | CPU, single GPU based instances | CPU, single and multi GPU, AWS Inferentia based Instances |
| Metric granularity | Endpoint | Endpoint | Endpoint and container |
| Scaling granularity | ML instance | ML instance | Container |
| Scaling behavior | Independent ML instance scaling | Models are loaded and unloaded from memory | Independent container scaling |
| Model pinning | . | Models can be unloaded based on memory | Each container can be configured to be always loaded or unloaded |
| Container requirements | SageMaker pre-built, SageMaker-compatible Bring Your Own Container (BYOC) | MMS, Triton, BYOC with MME contracts | SageMaker pre-built, SageMaker compatible BYOC |
| Routing options | Random or least connection | Random, sticky with popularity window | Random or least connection |
| Hardware allocation for model | Dedicated to single model | Shared | Dedicated for each container |
| Number of models supported | Single | Thousands | Hundreds |
| Response streaming | Supported | Not supported | Supported |
| Data capture | Supported | Not supported | Not supported |
| Shadow testing | Supported | Not supported | Not supported |
| Multi-variants | Supported | Not applicable | Not supported |
| AWS Marketplace models | Supported | Not applicable | Not supported |
About the authors
 Mehran Najafi, PhD, is a Senior Solutions Architect for AWS focused on ai/ML and SaaS solutions at Scale.
Mehran Najafi, PhD, is a Senior Solutions Architect for AWS focused on ai/ML and SaaS solutions at Scale.
 Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and artificial intelligence. He focuses on Deep learning including NLP and Computer Vision domains. He helps customers achieve high performance model inference on SageMaker.
Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and artificial intelligence. He focuses on Deep learning including NLP and Computer Vision domains. He helps customers achieve high performance model inference on SageMaker.
 Rielah DeJesus is a Principal Solutions Architect at AWS who has successfully helped various enterprise customers in the DC, Maryland, and Virginia area move to the cloud. A customer advocate and technical advisor, she helps organizations like Heroku/Salesforce achieve success on the AWS platform. She is a staunch supporter of Women in IT and very passionate about finding ways to creatively use technology and data to solve everyday challenges.
Rielah DeJesus is a Principal Solutions Architect at AWS who has successfully helped various enterprise customers in the DC, Maryland, and Virginia area move to the cloud. A customer advocate and technical advisor, she helps organizations like Heroku/Salesforce achieve success on the AWS platform. She is a staunch supporter of Women in IT and very passionate about finding ways to creatively use technology and data to solve everyday challenges.






{kind=link}