 NEWSLETTER
NEWSLETTER
Large language models (LLMs) have become an integral part of modern ai applications, powering tools like chatbots and code generators. However, increased reliance on these models has revealed critical inefficiencies in inference processes. Attention mechanisms such as FlashAttention and SparseAttention often struggle with diverse workloads, dynamic input patterns, and GPU resource limitations. These challenges, along with high latency and memory bottlenecks, underscore the need for a more efficient and flexible solution to support scalable and responsive LLM inference.
Researchers at the University of Washington, NVIDIA, Perplexity ai, and Carnegie Mellon University have developed FlashInfer, an ai library and kernel generator designed for LLM inference. FlashInfer provides high-performance GPU kernel implementations for several attention mechanisms, including FlashAttention, SparseAttention, PageAttention, and sampling. Its design prioritizes flexibility and efficiency, addressing key challenges in the LLM inference service.
FlashInfer incorporates a sparse block format to handle heterogeneous KV cache storage efficiently and employs dynamic load-balanced scheduling to optimize GPU utilization. With integration into popular LLM service frameworks such as SGLang, vLLM, and MLC-Engine, FlashInfer offers a practical and adaptable approach to improving inference performance.
Technical features and benefits
FlashInfer introduces several technical innovations:
- Comprehensive care centers: FlashInfer supports a variety of attention mechanisms, including pre-completion, decoding, and attention-aggregation, ensuring compatibility with various KV cache formats. This adaptability improves performance in both single request and batch service scenarios.
- Optimized shared prefix decoding: Through clustered query attention (GQA) and fused string attention (spin position embedding), FlashInfer achieves significant speedups, such as a 31x improvement over vLLM's page attention implementation for fast decoding and prolonged.
- Dynamic programming with load balancing: FlashInfer's scheduler dynamically adapts to input changes, reducing GPU downtime and ensuring efficient utilization. Its support for CUDA Graphs further enhances its applicability in production environments.
- Customizable JIT compilation: FlashInfer allows users to define and build custom attention variants on high-performance cores. This feature is tailored to specialized use cases, such as sliding window care or RoPE transformations.

Performance information
FlashInfer demonstrates notable performance improvements in several benchmarks:
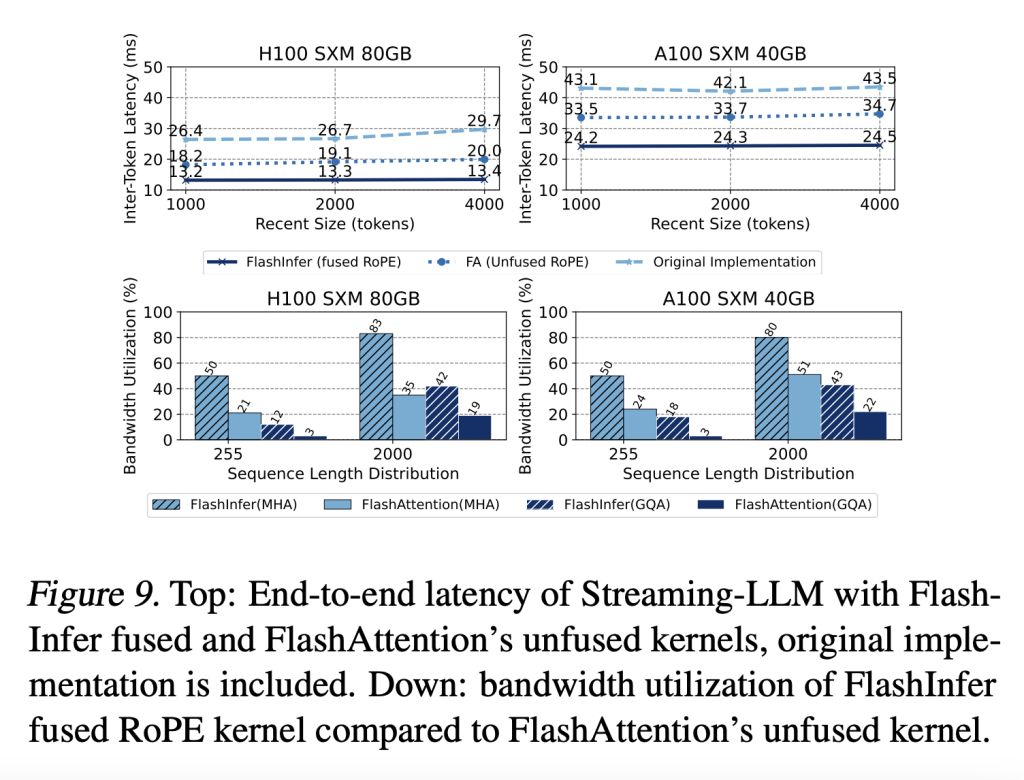
- Latency reduction: The library reduces latency between tokens by 29% to 69% compared to existing solutions like Triton. These gains are particularly evident in scenarios involving long context inference and parallel generation.
- Performance improvements: On NVIDIA H100 GPUs, FlashInfer achieves 13-17% speedup for parallel generation tasks, highlighting its effectiveness for high-demand applications.
- Improved GPU utilization: FlashInfer's dynamic scheduler and optimized cores improve bandwidth and FLOP utilization, particularly in scenarios with skewed or uniform sequence lengths.
FlashInfer also excels at parallel decoding tasks, with composable formats that enable significant reductions in time to first token (TTFT). For example, tests on the Llama 3.1 model (70B parameters) show a decrease of up to 22.86% in TTFT at specific configurations.
Conclusion
FlashInfer offers a practical and efficient solution to the challenges of LLM inference, providing significant improvements in performance and resource utilization. Its flexible design and integration capabilities make it a valuable tool for advancing LLM service frameworks. By addressing key inefficiencies and delivering robust technical solutions, FlashInfer paves the way for more accessible and scalable ai applications. As an open source project, it invites greater collaboration and innovation from the research community, ensuring continuous improvement and adaptation to emerging challenges in ai infrastructure.
Verify he Paper and <a target="_blank" href="https://github.com/flashinfer-ai/flashinfer” target=”_blank” rel=”noreferrer noopener”>GitHub Page. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on <a target="_blank" href="https://twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. Don't forget to join our SubReddit over 60,000 ml.
UPCOMING FREE ai WEBINAR (JANUARY 15, 2025): <a target="_blank" href="https://info.gretel.ai/boost-llm-accuracy-with-sd-and-evaluation-intelligence?utm_source=marktechpost&utm_medium=newsletter&utm_campaign=202501_gretel_galileo_webinar”>Increase LLM Accuracy with Synthetic Data and Assessment Intelligence–<a target="_blank" href="https://info.gretel.ai/boost-llm-accuracy-with-sd-and-evaluation-intelligence?utm_source=marktechpost&utm_medium=newsletter&utm_campaign=202501_gretel_galileo_webinar”>Join this webinar to learn practical information to improve LLM model performance and accuracy while protecting data privacy..
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for social good. Their most recent endeavor is the launch of an ai media platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easily understandable to a wide audience. The platform has more than 2 million monthly visits, which illustrates its popularity among the public.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}