
Companies around the world are looking to use multiple data sources to implement a unified search experience for their employees and end customers. Given the large volume of data that needs to be searched and indexed, retrieval speed, solution scalability, and search performance become key factors to consider when choosing an enterprise intelligent search solution. Additionally, these unique data sources comprise repositories of structured and unstructured content, including various file types, which can cause compatibility issues.
Amazon Kendra is a highly accurate, intelligent search service that enables users to find answers to their questions from their structured and unstructured data using natural language processing and advanced search algorithms. Return specific answers to questions, giving users an experience close to interacting with a human expert.
Today, Amazon Kendra released seven additional data format support options for your use. This allows you to easily integrate your existing data sources as-is and intelligently search across multiple content repositories.
In this post, we discuss the new supported data formats and how to use them.
New supported data formats
Previously, Amazon Kendra supported documents that included structured text in the form of FAQs, as well as unstructured text in the form of HTML files, Microsoft PowerPoint presentations, Microsoft Word documents, plain text documents, and PDFs.
With this release, Amazon Kendra now offers support for seven additional data formats:
- Rich Text Format (RTF)
- JavaScript Object Notation (JSON)
- Markdown (MD)
- Comma Separated Values (CSV)
- Microsoft Excel (MS Excel)
- Extensible Markup Language (XML)
- Extensible Style Sheet Language (XSLT) Transformations
Amazon Kendra users can add these documents with different data formats to their index in the following two ways:
Solution Overview
In the following sections, we walk through the steps for adding documents from a data source and performing a search on those documents.
The following diagram shows the architecture of our solution.
To test this solution for any of the supported formats, you must use your own data. You can test uploading documents of the same or different formats to the S3 bucket.
Create an Amazon Kendra Index
For instructions on how to create your Amazon Kendra index, see Creating an index.
You can skip this step if you have a pre-existing index to use for this demo.
Upload documents to an S3 bucket and ingest into the index using the S3 connector
Complete the following steps to connect an S3 bucket to your index:
- Create an S3 bucket to store your documents.
- Create a folder called sample-data.
- Upload the documents you want to test in the folder.
- In the Amazon Kendra console, go to your index and choose data sources.
- Choose add data source.
- Low Available data sourcesselect S3 and choose add connector.
- Enter a name for your connector (such as
Demo_S3_connector) and choose Next. - Choose Explore S3 and choose the S3 bucket where you uploaded the documents.
- For Identity and access management functioncreate a new role.
- For Set Synchronization Execution Programselect run on demand.
- Choose Next.
- About him review and create page, choose add data source.
- After the creation process is complete, choose sync now.
Now that you’ve ingested some documents, you can navigate to the built-in search console to test your queries.
Search your documents with the Amazon Kendra search console
In the Amazon Kendra console, choose Search indexed content in the navigation pane.
The following are examples of search results for different types of documents:
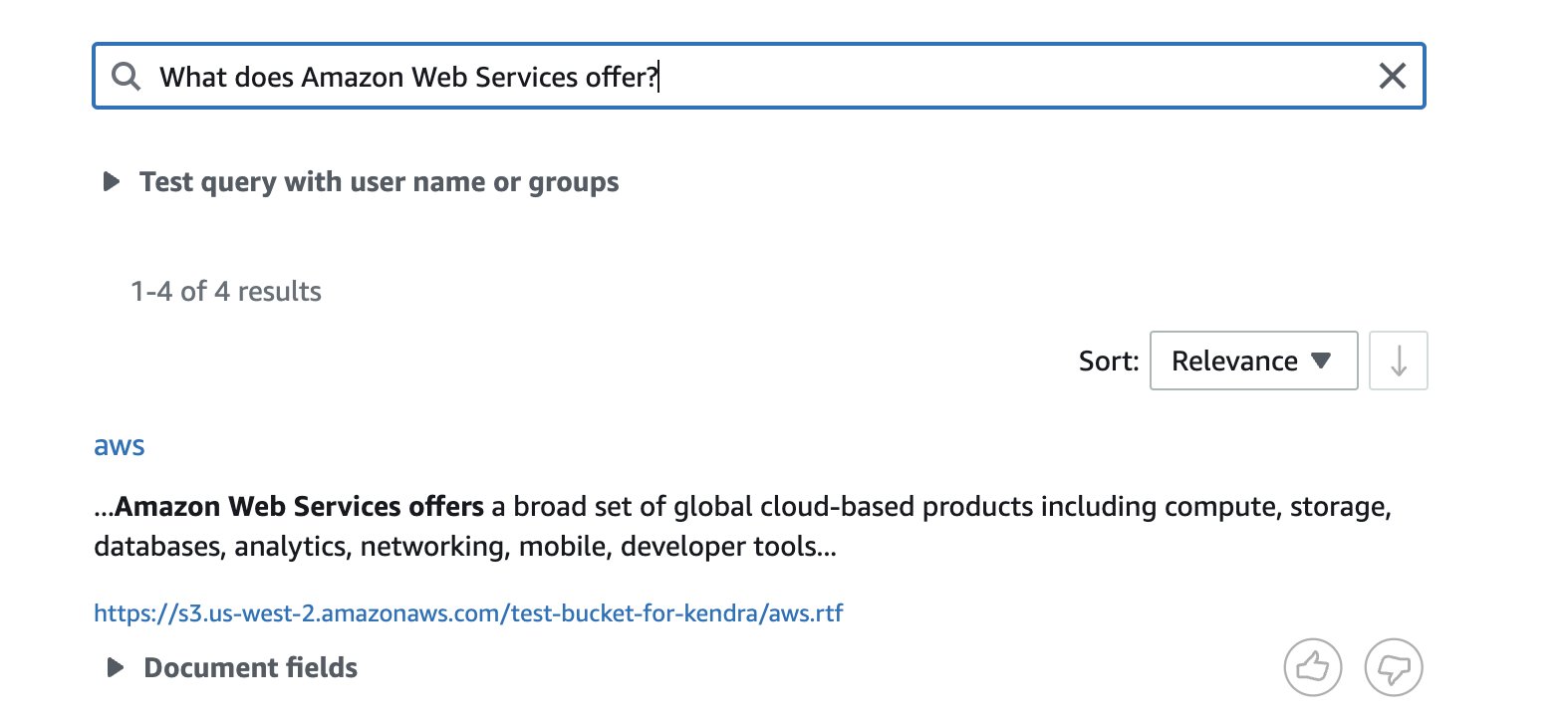
- RTF – Enter data in RTF format uploaded to S3 bucket and sync data source:

The following screenshot shows the search results.
- JSON – Enter data in JSON format uploaded to S3 bucket and sync data source:
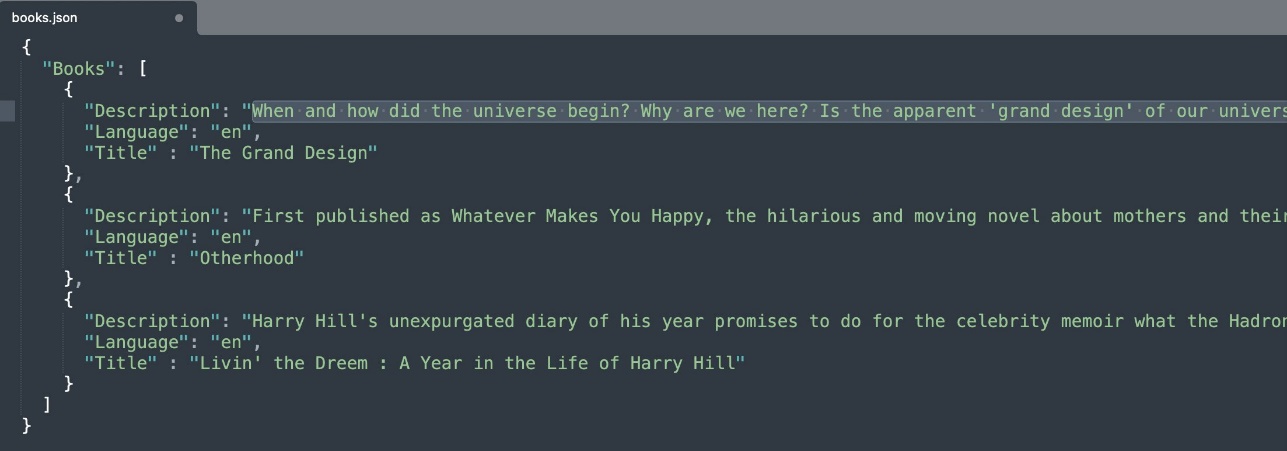
The following screenshot shows the search results.
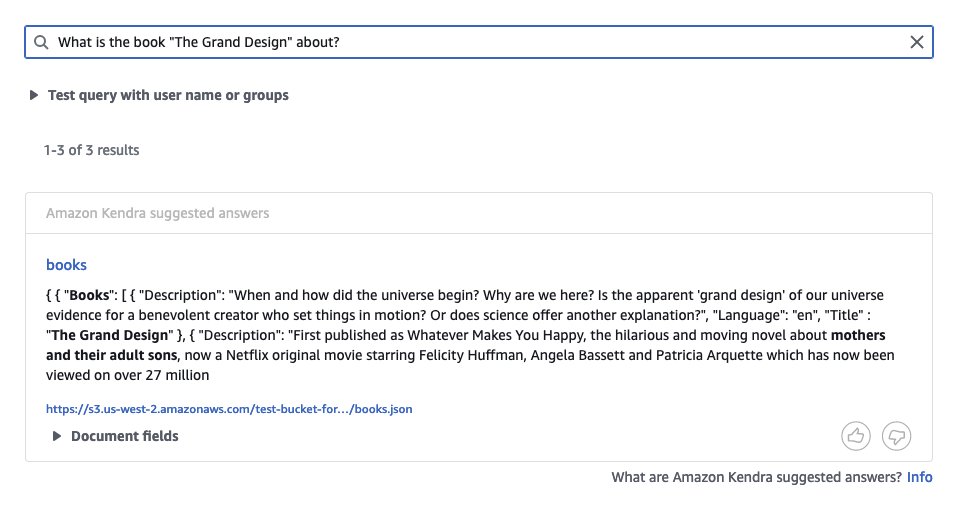
- Reduction – Enter the data in MD format uploaded to the S3 bucket and sync the data source:
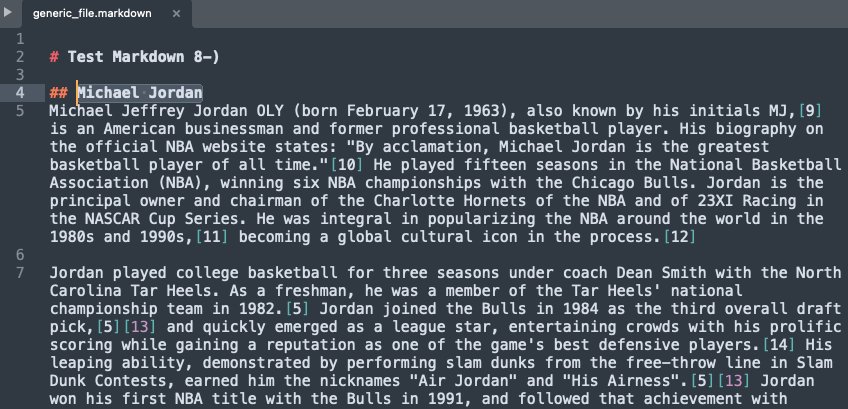
The following screenshot shows the search results.
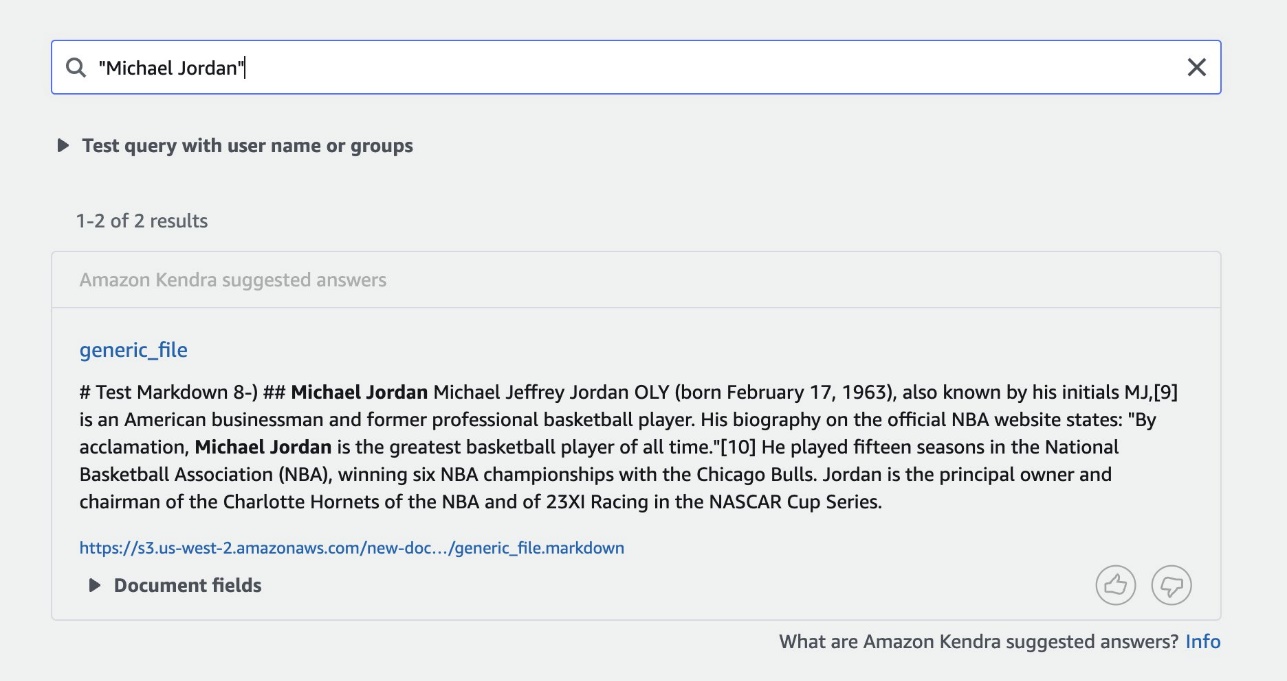
- CSV – Enter the data in CSV format uploaded to the S3 bucket and synchronize the data source:

The following screenshot shows the search results.
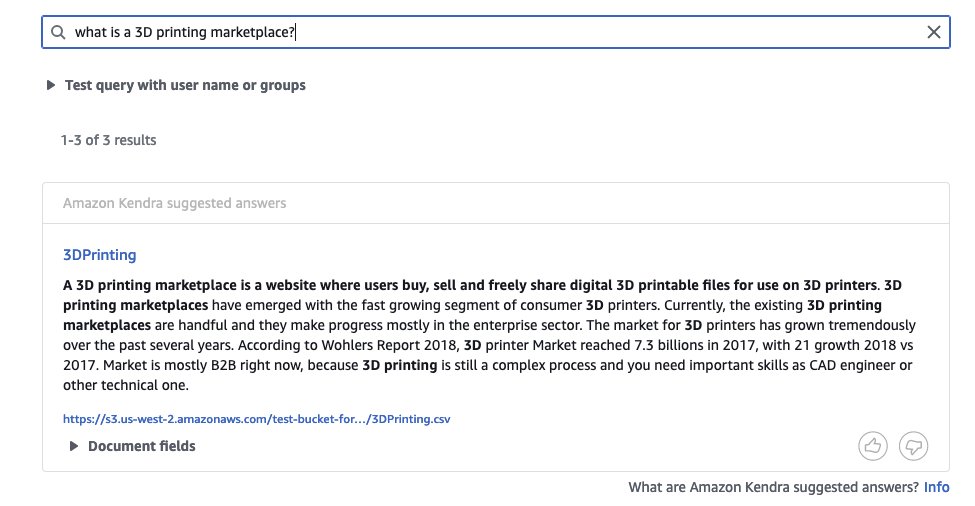
- Standing out – Enter data in Excel format uploaded to S3 bucket and sync data source:
The following screenshot shows the search results.
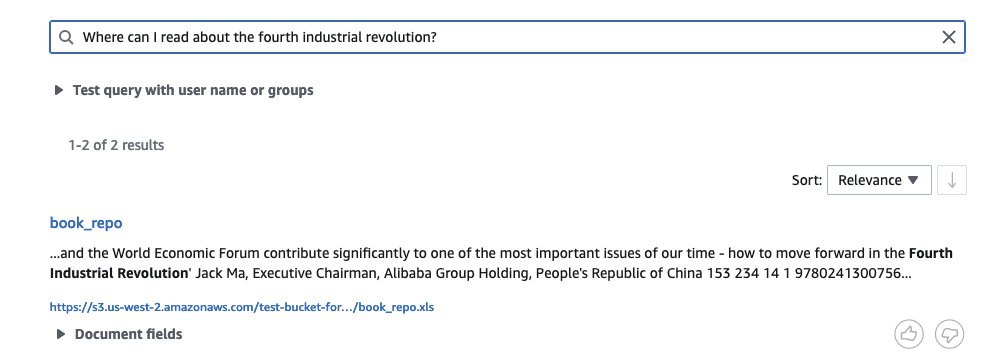
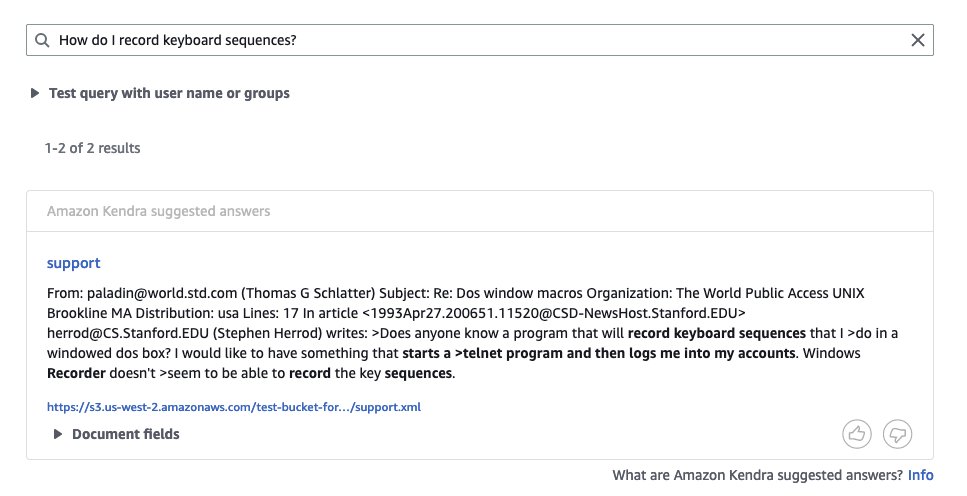
- XML – Enter the data in XML format uploaded to the S3 bucket and synchronize the data source:
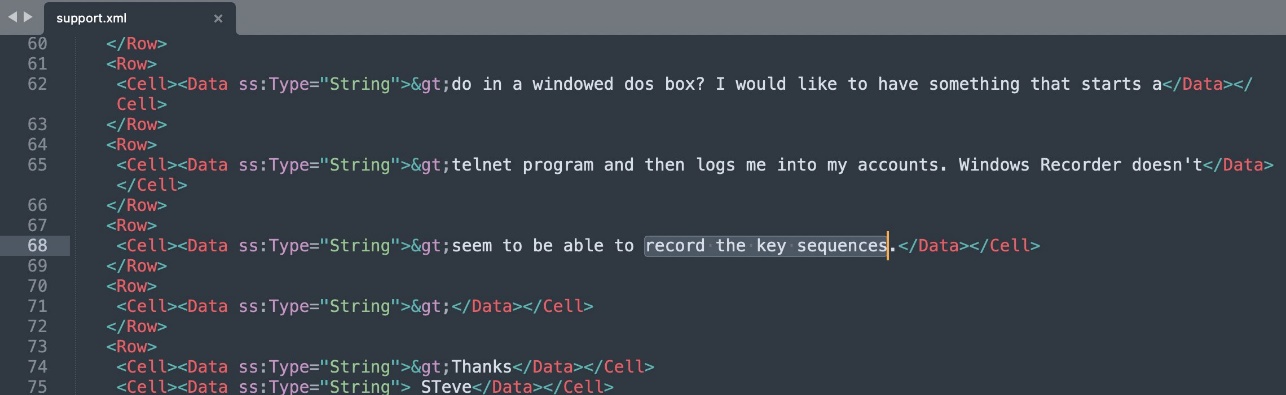
The following screenshot shows the search results.
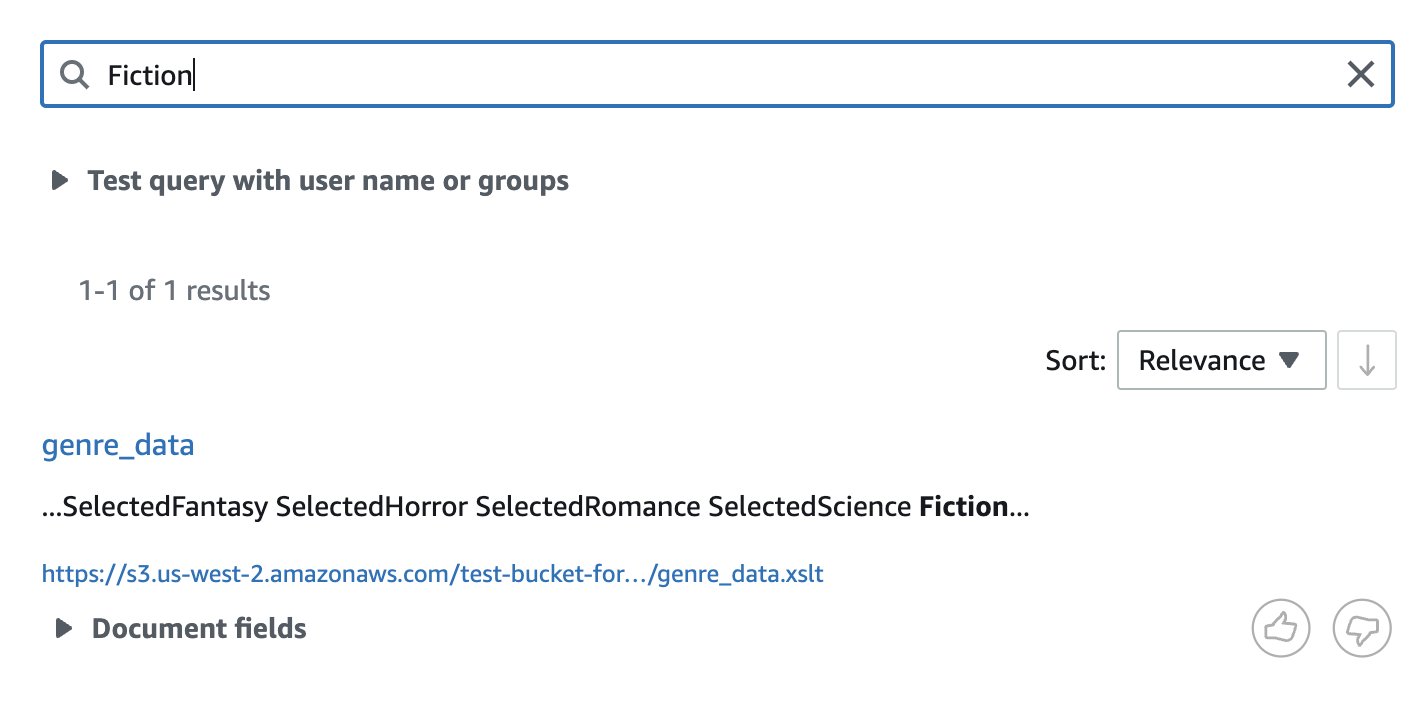
- XSLT – Enter data in XSLT format uploaded to S3 bucket and sync data source:
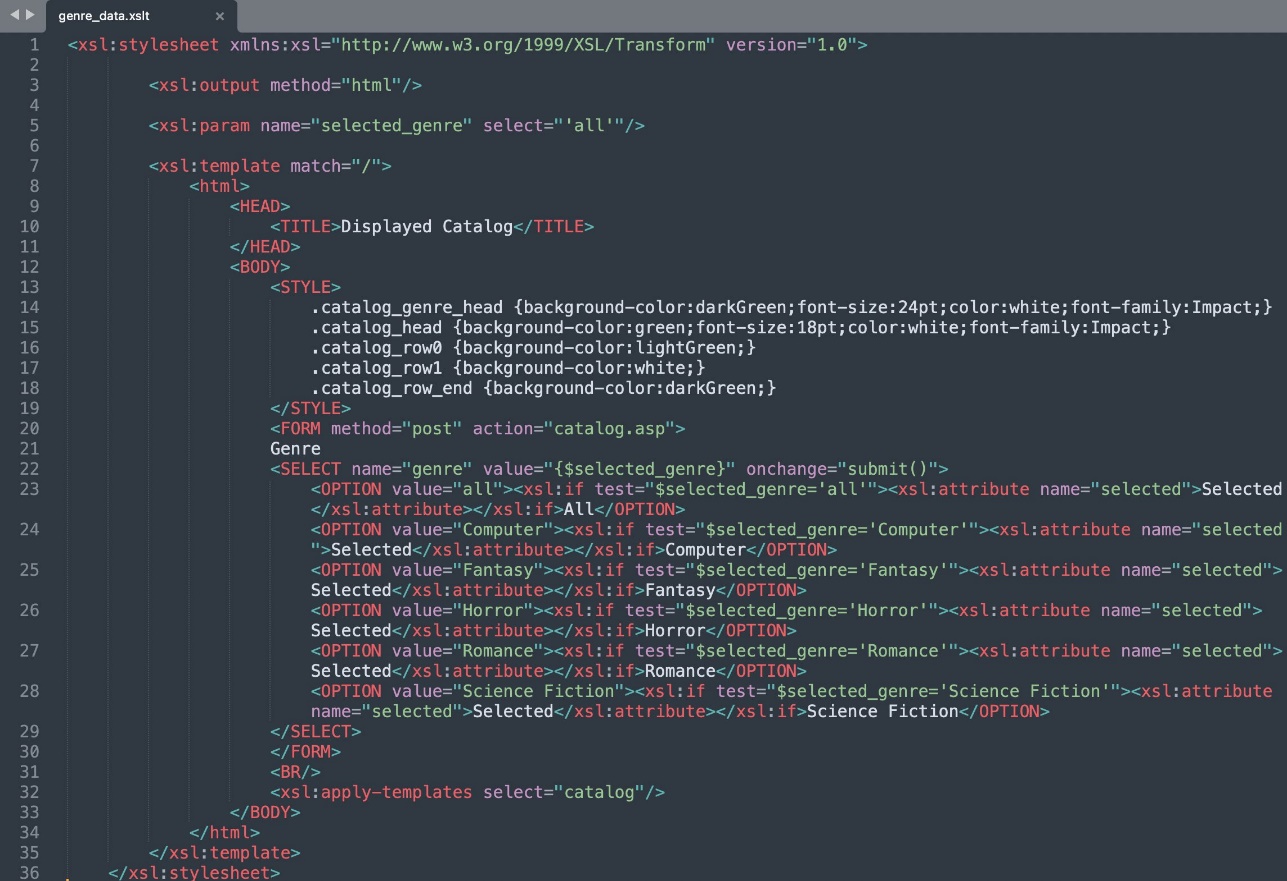
The following screenshot shows the search results.
Clean
To avoid incurring future costs, clean up the resources that you created as part of this solution using the following steps:
- In the Amazon Kendra console, choose Indices in the navigation pane.
- Choose the index that contains the data source to delete.
- In the navigation pane, choose data sources.
- Choose the data source to delete, then choose Delete.
When you delete a data source, Amazon Kendra deletes all information stored about the data source. Amazon Kendra removes all document data stored in the index and all execution metrics and histories associated with the data source. Deleting a data source does not delete the original documents from your storage.
- In the Amazon Kendra console, choose Indexes in the navigation pane.
- Choose the index to delete, then choose Delete.
See Delete an index and data source for more details.
- In the Amazon S3 console, choose cubes in the navigation pane.
- Select the cube you want to delete, then choose Delete.
- Enter the name of the bucket to confirm the deletion, then choose delete bucket.
If the bucket contains any objects, you will receive an error alert. Empty the bucket before deleting it by selecting the link in the error message and following the instructions in the empty bucket page. Then go back to the delete bucket page and remove the cube.
- To verify that you have removed the repository, open the cubes page and enter the name of the bucket you deleted. If the bucket cannot be found, its deletion was successful.
See the Removing a Deposit page for more details.
Conclusion
In this post, we discuss the new data formats that Amazon Kendra now supports. Additionally, we discuss how to use Amazon Kendra to ingest and search these new types of documents stored in an S3 bucket. For more information on the different supported data formats, see Document Types.
We’ve introduced you to the basics, but there are many additional features that we didn’t cover in this post, such as:
- You can enable user-based access control for your Amazon Kendra index and restrict access to users and groups that you configure.
- You can map additional fields to Amazon Kendra index attributes and enable them to be faceted, searched, and displayed in search results.
- You can integrate different connectors from third-party data sources like Service Now and Salesforce with the Custom Document Enrichment (CDE) capability in Amazon Kendra to perform additional attribute mapping logic and even custom content transformation during ingestion. For the full list of supported connectors, see Connectors.
To learn about these possibilities and more, see the Amazon Kendra Developer Guide.
About the authors
 Rishabh Yadav is an AWS Partner Solutions Architect with extensive experience in DevOps and security offerings on AWS. He works with ASEAN partners to provide guidance on enterprise cloud adoption and architecture reviews along with building AWS practices through implementation of the well-architected framework. Outside of work, he likes to spend his time on the sports field and playing FPS games.
Rishabh Yadav is an AWS Partner Solutions Architect with extensive experience in DevOps and security offerings on AWS. He works with ASEAN partners to provide guidance on enterprise cloud adoption and architecture reviews along with building AWS practices through implementation of the well-architected framework. Outside of work, he likes to spend his time on the sports field and playing FPS games.
 Kruthi Jayasimha Rao is a partner solutions architect with a focus on AI and ML. He provides technical guidance to AWS Partners on how to follow best practices to build secure, resilient, and highly available solutions in the AWS Cloud.
Kruthi Jayasimha Rao is a partner solutions architect with a focus on AI and ML. He provides technical guidance to AWS Partners on how to follow best practices to build secure, resilient, and highly available solutions in the AWS Cloud.
 Keerthy Kumar Kallur is a software development engineer at AWS. He has been with the AWS Kendra team for the past 2 years and has worked in various functions and on clients. In his spare time he likes to do outdoor activities like hiking, sports like volleyball.
Keerthy Kumar Kallur is a software development engineer at AWS. He has been with the AWS Kendra team for the past 2 years and has worked in various functions and on clients. In his spare time he likes to do outdoor activities like hiking, sports like volleyball.






{kind=link}