 NEWSLETTER
NEWSLETTER
With the advent of generative ai solutions, a paradigm shift is underway across industries, driven by organizations embracing foundation models to unlock unprecedented opportunities. amazon Bedrock has emerged as the preferred choice for numerous customers seeking to innovate and launch generative ai applications, leading to an exponential surge in demand for model inference capabilities. Bedrock customers aim to scale their worldwide applications to accommodate growth, and require additional burst capacity to handle unexpected surges in traffic. Currently, users might have to engineer their applications to handle scenarios involving traffic spikes that can use service quotas from multiple regions by implementing complex techniques such as client-side load balancing between AWS regions, where amazon Bedrock service is supported. However, this dynamic nature of demand is difficult to predict, increases operational overhead, introduces potential points of failure, and might hinder businesses from achieving true global resilience and continuous service availability.
Today, we are happy to announce the general availability of cross-region inference, a powerful feature allowing automatic cross-region inference routing for requests coming to amazon Bedrock. This offers developers using on-demand inference mode, a seamless solution for managing optimal availability, performance, and resiliency while managing incoming traffic spikes of applications powered by amazon Bedrock. By opting in, developers no longer have to spend time and effort predicting demand fluctuations. Instead, cross-region inference dynamically routes traffic across multiple regions, ensuring optimal availability for each request and smoother performance during high-usage periods. Moreover, this capability prioritizes the connected amazon Bedrock API source/primary region when possible, helping to minimize latency and improve responsiveness. As a result, customers can enhance their applications’ reliability, performance, and efficiency.
Let us dig deeper into this feature where we will cover:
- Key features and benefits of cross-region inference
- Getting started with cross-region inference
- Code samples for defining and leveraging this feature
- How to think about migrating to cross-region inference
- Key considerations
- Best Practices to follow for this feature
- Conclusion
Let’s dig in!
Key features and benefits.
One of the critical requirements from our customers is the ability to manage bursts and spiky traffic patterns across a variety of generative ai workloads and disparate request shapes. Some of the key features of cross-region inference include:
- Utilize capacity from multiple AWS regions allowing generative ai workloads to scale with demand.
- Compatibility with existing amazon Bedrock API
- No additional routing or data transfer cost and you pay the same price per token for models as in your source/primary region.
- Become more resilient to any traffic bursts. This means, users can focus on their core workloads and writing logic for their applications powered by amazon Bedrock.
- Ability to choose from a range of pre-configured AWS region sets tailored to your needs.
The below image would help to understand how this feature works. amazon Bedrock makes real-time decisions for every request made via cross-region inference at any point of time. When a request arrives to amazon Bedrock, a capacity check is performed in the same region where the request originated from, if there is enough capacity the request is fulfilled else a second check determines a secondary region which has capacity to take the request, it is then re-routed to that decided region and results are retrieved for customer request. This ability to perform capacity checks was not available to customers so they had to implement manual checks of every region of choice after receiving an error and then re-route. Further the typical custom implementation of re-routing might be based on round robin mechanism with no insights into the available capacity of a region. With this new capability, amazon Bedrock takes into account all the aspects of traffic and capacity in real-time, to make the decision on behalf of customers in a fully-managed manner without any extra costs.
Few points to be aware of:
- AWS network backbone is used for data transfer between regions instead of internet or VPC peering, resulting in secure and reliable execution.
- The feature will try to serve the request from your primary region first. It will route to other regions in case of heavy traffic, bottlenecks and load balance the requests.
- You can access a select list of models via cross-region inference, which are essentially region agnostic models made available across the entire region-set. You will be able to use a subset of models available in amazon Bedrock from anywhere inside the region-set even if the model is not available in your primary region.
- You can use this feature in the amazon Bedrock model invocation APIs (
InvokeModelandConverseAPI). - You can choose whether to use Foundation Models directly via their respective model identifier or use the model via the cross-region inference mechanism. Any inferences performed via this feature will consider on-demand capacity from all of its pre-configured regions to maximize availability.
- There will be additional latency incurred when re-routing happens and, in our testing, it has been a double-digit milliseconds latency add.
- All terms applicable to the use of a particular model, including any end user license agreement, still apply when using cross-region inference.
- When using this feature, your throughput can reach up to double the allocated quotas in the region that the inference profile is in. The increase in throughput only applies to invocation performed via inference profiles, the regular quota still applies if you opt for in-region model invocation request. To see quotas for on-demand throughput, refer to the Runtime quotas section in Quotas for amazon Bedrock or use the Service Quotas console
Definition of a secondary region
Let us dive deep into a few important aspects:
- What is a secondary region? As part of this launch, you can select either a US Model or EU Model, each of which will include 2-3 preset regions from these geographical locations.
- Which models are included? As part of this launch, we will have Claude 3 family of models (Haiku, Sonnet, Opus) and Claude 3.5 Sonnet made available.
- Can we use PrivateLink? Yes, you will be able to leverage your private links and ensure traffic flows via your VPC with this feature.
- Can we use Provisioned Throughput with this feature as well? Currently, this feature will not apply to Provisioned Throughput and can be used for on-demand inference only.
- When does the workload traffic get re-routed? Cross-region inference will first try to service your request via the primary region (region of the connected amazon Bedrock endpoint). As the traffic patterns spike up and amazon Bedrock detects potential delays, the traffic will shift pro-actively to the secondary region and get serviced from those regions.
- Where would the logs be for cross-region inference? The logs and invocations will still be in the primary region and account where the request originates from. amazon Bedrock will output indicators on the logs which will show which region actually serviced the request.
- Here is an example of the traffic patterns can be from below (map not to scale).
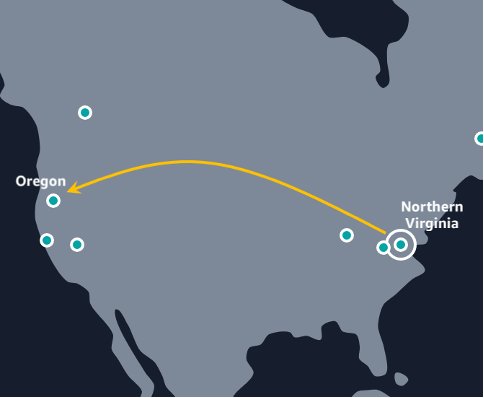
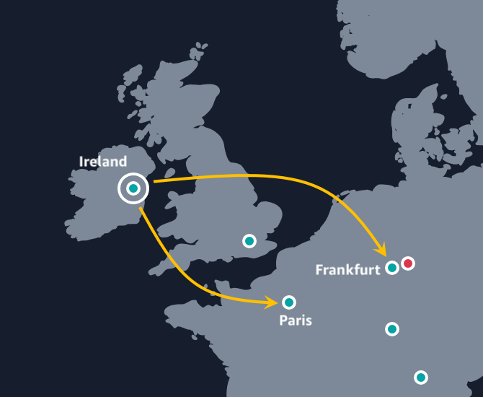
A customer with a workload in eu-west-1 (Ireland) may choose both eu-west-3 (Paris) and eu-central-1 (Frankfurt) as a pair of secondary regions, or a workload in us-east-1 (Northern Virginia) may choose us-west-2 (Oregon) as a single secondary region, or vice versa. This would keep all inference traffic within the United States of America or European Union.
Security and Architecture of how cross-region inference looks like
The following diagram shows the high-level architecture for a cross-region inference request:
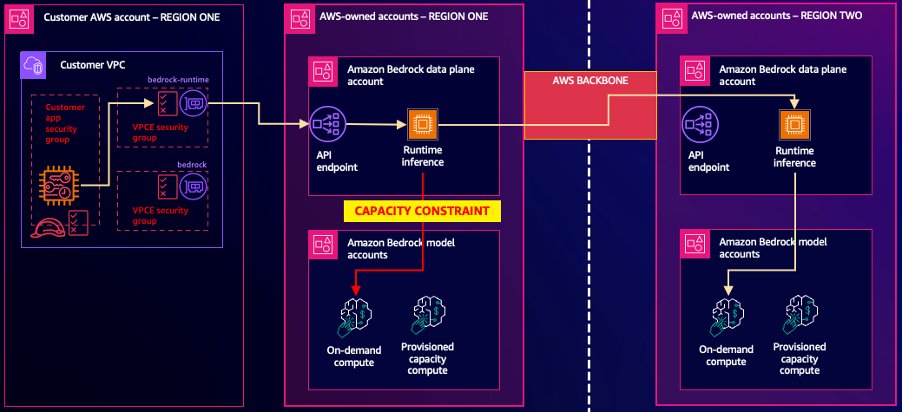
The operational flow starts with an Inference request coming to a primary region for an on-demand baseline model. Capacity evaluations are made on the primary region and the secondary region list, creating a region capacity list in capacity order. The region with the most available capacity, in this case eu-central-1 (Frankfurt), is selected as the next target. The request is re-routed to Frankfurt using the AWS Backbone network, ensuring that all traffic remains within the AWS network. The request bypasses the standard API entry-point for the amazon Bedrock service in the secondary region and goes directly to the Runtime inference service, where the response is returned back to the primary region over the AWS Backbone and then returned to the caller as per a normal inference request. If processing in the chosen region fails for any reason, then the next region in the region capacity list highest available capacity is tried, eu-west-1 (Ireland) in this example, followed by eu-west-3 (Paris), until all configured regions have been attempted. If no region in the secondary region list can handle the inference request, then the API will return the standard “throttled” response.
Networking and data logging
The AWS-to-AWS traffic flows, such as Region-to-Region (inclusive of Edge Locations and Direct Connect paths), will always traverse AWS-owned and operated backbone paths. This not only reduces threats, such as common exploits and DDoS attacks, but also ensures that all internal AWS-to-AWS traffic uses only trusted network paths. This is combined with inter-Region and intra-Region path encryption and routing policy enforcement mechanisms, all of which use AWS secure facilities. This combination of enforcement mechanisms helps ensure that AWS-to-AWS traffic will never use non-encrypted or untrusted paths, such as the internet, and hence as a result all cross-region inference requests will remain on the AWS backbone at all times.
Log entries will continue to be made in the original source region for both amazon CloudWatch and AWS CloudTrail, and there will be no additional logs in the re-routed region. In order to indicate that re-routing happened the related entry in AWS CloudTrail will also include the following additional data – it is only added if the request was processed in a re-routed region.
During an inference request, amazon Bedrock does not log or otherwise store any of a customer’s prompts or model responses. This is still true if cross-region inference re-routes a query from a primary region to a secondary region for processing – that secondary region does not store any data related to the inference request, and no amazon CloudWatch or AWS CloudTrail logs are stored in that secondary region.
Identity and Access Management
AWS Identity and Access Management (IAM) is key to securely managing your identities and access to AWS services and resources. With the introduction of cross-region inference there is a new context key aws:RequestedRegion. The caller must have this enabled for each of the regions in the inference region list. This is evaluated in the source region before any model inference request is made, and if the caller does not have permission for every region in the inference region list, then the request is denied without any inference taking place.
An example policy, which allows the caller to use the cross-region inference with the InvokeModel* APIs for any model in the us-east-1 and us-west-2 region is as follows:
Getting started with Cross-region inference
To get started with cross-region inference, you make use of Inference Profiles in amazon Bedrock. An inference profile for a model, configures different model ARNs from respective AWS regions and abstracts them behind a unified model identifier (both id and ARN). Just by simply using this new inference profile identifier with the InvokeModel or Converse API, you can use the cross-region inference feature.
Here are the steps to start using cross-region inference with the help of inference profiles:
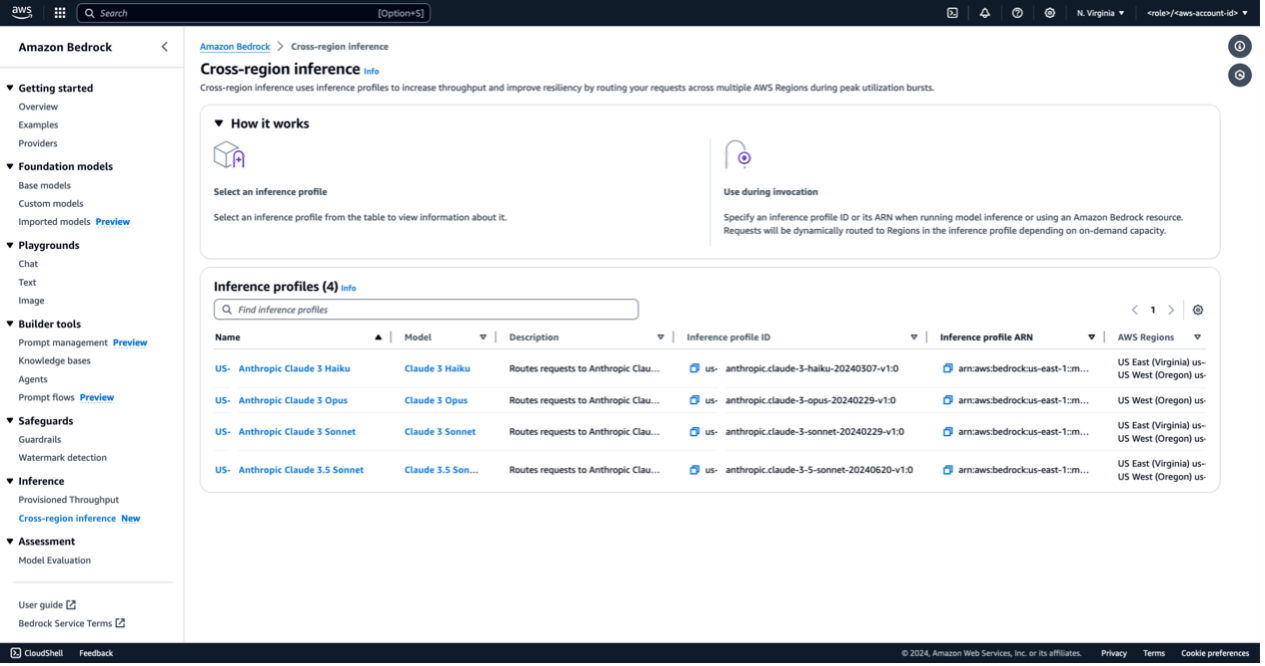
- List Inference Profiles
You can list the inference profiles available in your region by either signing in to amazon Bedrock AWS console or API.- Console
- From the left-hand pane, select “Cross-region Inference”
- You can explore different inference profiles available for your region(s).
- Copy the inference profile ID and use it in your application, as described in the section below
- API
It is also possible to list the inference profiles available in your region via boto3 SDK or AWS CLI.
- Console
You can observe how different inference profiles have been configured for various geo locations comprising of multiple AWS regions. For example, the models with the prefix us. are configured for AWS regions in USA, whereas models with eu. are configured with the regions in European Union (EU).
- Modify Your Application
- Update your application to use the inference profile ID/ARN from console or from the API response as
modelIdin your requests viaInvokeModelorConverse - This new inference profile will automatically manage inference throttling and re-route your request(s) across multiple AWS Regions (as per configuration) during peak utilization bursts.
- Update your application to use the inference profile ID/ARN from console or from the API response as
- Monitor and Adjust
- Use amazon CloudWatch to monitor your inference traffic and latency across regions.
- Adjust the use of inference profile vs FMs directly based on your observed traffic patterns and performance requirements.
Code example to leverage Inference Profiles
Use of inference profiles is similar to that of foundation models in amazon Bedrock using the InvokeModel or Converse API, the only difference between the modelId is addition of a prefix such as us. or eu.
Foundation Model
Inference Profile
Deep Dive
While it is straight forward to start using inference profiles, you first need to know which inference profiles are available as part of your region. Start with the list of inference profiles and observe models available for this feature. This is done through the AWS CLI or SDK.
You can expect an output similar to the one below:
The difference between ARN for a foundation model available via amazon Bedrock and the inference profile can be observed as:
Foundation Model: arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-3-5-sonnet-20240620-v1:0
Inference Profile: arn:aws:bedrock:us-east-1::inference-profile/us.anthropic.claude-3-5-sonnet-20240620-v1:0
Choose the configured inference profile, and start sending inference requests to your model’s endpoint as usual. amazon Bedrock will automatically route and scale the requests across the configured regions as needed. You can choose to use both ARN as well as ID with the Converse API whereas just the inference profile ID with the InvokeModel API. It is important to note which models are supported by Converse API.
In the code sample above you must specify such as US regions including us-east-1, us-west-2 or EU regions including eu-central-1, eu-west-1, eu-west-3. The will then be relative, either us or eu.
Adapting your applications to use Inference Profiles for your amazon Bedrock FMs is quick and easy with steps above. No significant code changes are required on the client side. amazon Bedrock handles the cross-region inference transparently. Monitor CloudTrail logs to check if your request is automatically re-routed to another region as described in the section above.
How to think about adopting to the new cross-region inference feature?
When considering the adoption of this new capability, it’s essential to carefully evaluate your application requirements, traffic patterns, and existing infrastructure. Here’s a step-by-step approach to help you plan and adopt cross-region inference:
- Assess your current workload and traffic patterns. Analyze your existing generative ai workloads and identify those that experience significant traffic bursts or have high availability requirements including current traffic patterns, including peak loads, geographical distribution, and any seasonal or cyclical variations
- Evaluate the potential benefits of cross-region inference. Consider the potential advantages of leveraging cross-region inference, such as increased burst capacity, improved availability, and better performance for global users. Estimate the potential cost savings by not having to implement a custom logic of your own and pay for data transfer (as well as different token pricing for models) or efficiency gains by off-loading multiple regional deployments into a single, fully-managed distributed solution.
- Plan and execute the migration. Update your application code to use the inference profile ID/ARN instead of individual foundation model IDs, following the provided code sample above. Test your application thoroughly in a non-production environment, simulating various traffic patterns and failure scenarios. Monitor your application’s performance, latency, and cost during the migration process, and make adjustments as needed.
- Develop new applications with cross-region inference in mind. For new application development, consider designing with cross-region inference as the foundation, leveraging inference profiles from the start. Incorporate best practices for high availability, resilience, and global performance into your application architecture.
Key Considerations
Impact on Current Generative ai Workloads
Inference profiles are designed to be compatible with existing amazon Bedrock APIs, such as InvokeModel and Converse. Also, any third-party/opensource tool which uses these APIs such as LangChain can be used with inference profiles. This means that you can seamlessly integrate inference profiles into your existing workloads without the need for significant code changes. Simply update your application to use the inference profiles ARN instead of individual model IDs, and amazon Bedrock will handle the cross-region routing transparently.
Impact on Pricing
The feature comes with no additional cost to you. You pay the same price per token of individual models in your primary/source region. There is no additional cost associated with cross-region inference including the failover capabilities provided by this feature. This includes management, data-transfer, encryption, network usage and potential differences in price per million token per model.
Regulations, Compliance, and Data Residency
Although none of the customer data is stored in either the primary or secondary region(s) when using cross-region inference, it’s important to consider that your inference data will be processed and transmitted beyond your primary region. If you have stric7t data residency or compliance requirements, you should carefully evaluate whether cross-region inference aligns with your policies and regulations.
Conclusion
In this blog we introduced the latest feature from amazon Bedrock, cross-region inference via inference profiles, and a peek into how it operates and also dived into some of the how-to’s and points for considerations. This feature empowers developers to enhance the reliability, performance, and efficiency of their applications, without the need to spend time and effort building complex resiliency structures. This feature is now generally available in US and EU for supported models.
About the authors
 Talha Chattha is a Generative ai Specialist Solutions Architect at amazon Web Services, based in Stockholm. Talha helps establish practices to ease the path to production for Gen ai workloads. Talha is an expert in amazon Bedrock and supports customers across entire EMEA. He holds passion about meta-agents, scalable on-demand inference, advanced RAG solutions and cost optimized prompt engineering with LLMs. When not shaping the future of ai, he explores the scenic European landscapes and delicious cuisines. Connect with Talha at LinkedIn using /in/talha-chattha/.
Talha Chattha is a Generative ai Specialist Solutions Architect at amazon Web Services, based in Stockholm. Talha helps establish practices to ease the path to production for Gen ai workloads. Talha is an expert in amazon Bedrock and supports customers across entire EMEA. He holds passion about meta-agents, scalable on-demand inference, advanced RAG solutions and cost optimized prompt engineering with LLMs. When not shaping the future of ai, he explores the scenic European landscapes and delicious cuisines. Connect with Talha at LinkedIn using /in/talha-chattha/.
 Rupinder Grewal is a Senior ai/ML Specialist Solutions Architect with AWS. He currently focuses on the serving of models and MLOps on amazon SageMaker. Prior to this role, he worked as a Machine Learning Engineer building and hosting models. Outside of work, he enjoys playing tennis and biking on mountain trails.
Rupinder Grewal is a Senior ai/ML Specialist Solutions Architect with AWS. He currently focuses on the serving of models and MLOps on amazon SageMaker. Prior to this role, he worked as a Machine Learning Engineer building and hosting models. Outside of work, he enjoys playing tennis and biking on mountain trails.
![]() Sumit Kumar is a Principal Product Manager, Technical at AWS Bedrock team, based in Seattle. He has 12+ years of product management experience across a variety of domains and is passionate about ai/ML. Outside of work, Sumit loves to travel and enjoys playing cricket and Lawn-Tennis.
Sumit Kumar is a Principal Product Manager, Technical at AWS Bedrock team, based in Seattle. He has 12+ years of product management experience across a variety of domains and is passionate about ai/ML. Outside of work, Sumit loves to travel and enjoys playing cricket and Lawn-Tennis.
 Dr. Andrew Kane is an AWS Principal WW tech Lead (ai Language Services) based out of London. He focuses on the AWS Language and Vision ai services, helping our customers architect multiple ai services into a single use-case driven solution. Before joining AWS at the beginning of 2015, Andrew spent two decades working in the fields of signal processing, financial payments systems, weapons tracking, and editorial and publishing systems. He is a keen karate enthusiast (just one belt away from Black Belt) and is also an avid home-brewer, using automated brewing hardware and other IoT sensors.
Dr. Andrew Kane is an AWS Principal WW tech Lead (ai Language Services) based out of London. He focuses on the AWS Language and Vision ai services, helping our customers architect multiple ai services into a single use-case driven solution. Before joining AWS at the beginning of 2015, Andrew spent two decades working in the fields of signal processing, financial payments systems, weapons tracking, and editorial and publishing systems. He is a keen karate enthusiast (just one belt away from Black Belt) and is also an avid home-brewer, using automated brewing hardware and other IoT sensors.





{kind=link}