 NEWSLETTER
NEWSLETTER
Fine-tuning Meta Llama 3.1 models with amazon SageMaker JumpStart enables developers to customize these publicly available foundation models (FMs). The Meta Llama 3.1 collection represents a significant advancement in the field of generative artificial intelligence (ai), offering a range of capabilities to create innovative applications. The Meta Llama 3.1 models come in various sizes, with 8 billion, 70 billion, and 405 billion parameters, catering to diverse project needs.
What makes these models stand out is their ability to understand and generate text with impressive coherence and nuance. Supported by context lengths of up to 128,000 tokens, the Meta Llama 3.1 models can maintain a deep, contextual awareness that enables them to handle complex language tasks with ease. Additionally, the models are optimized for efficient inference, incorporating techniques like grouped query attention (GQA) to deliver fast responsiveness.
In this post, we demonstrate how to fine-tune Meta Llama 3-1 pre-trained text generation models using SageMaker JumpStart.
Meta Llama 3.1
One of the notable features of the Meta Llama 3.1 models is their multilingual prowess. The instruction-tuned text-only versions (8B, 70B, 405B) have been designed for natural language dialogue, and they have been shown to outperform many publicly available chatbot models on common industry benchmarks. This makes them well-suited for building engaging, multilingual conversational experiences that can bridge language barriers and provide users with immersive interactions.
At the core of the Meta Llama 3.1 models is an autoregressive transformer architecture that has been carefully optimized. The tuned versions of the models also incorporate advanced fine-tuning techniques, such as supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF), to align the model outputs with human preferences. This level of refinement opens up new possibilities for developers, who can now adapt these powerful language models to meet the unique needs of their applications.
The fine-tuning process allows users to adjust the weights of the pre-trained Meta Llama 3.1 models using new data, improving their performance on specific tasks. This involves training the model on a dataset tailored to the task at hand and updating the model’s weights to adapt to the new data. Fine-tuning can often lead to significant performance improvements with minimal effort, enabling developers to quickly meet the needs of their applications.
SageMaker JumpStart now supports the Meta Llama 3.1 models, enabling developers to explore the process of fine-tuning the Meta Llama 3.1 405B model using the SageMaker JumpStart UI and SDK. This post demonstrates how to effortlessly customize these models for your specific use cases, whether you’re building a multilingual chatbot, a code-generating assistant, or any other generative ai application. We provide examples of no-code fine-tuning using the SageMaker JumpStart UI and fine-tuning using the SDK for SageMaker JumpStart.
SageMaker JumpStart
With SageMaker JumpStart, machine learning (ML) practitioners can choose from a broad selection of publicly available FMs. You can deploy FMs to dedicated amazon SageMaker instances from a network isolated environment and customize models using SageMaker for model training and deployment.
You can now discover and deploy Meta Llama 3.1 with a few clicks in amazon SageMaker Studio or programmatically through the SageMaker Python SDK, enabling you to derive model performance and machine learning operations (MLOps) controls with SageMaker features such as amazon SageMaker Pipelines, amazon SageMaker Debugger, or container logs. The model is deployed in an AWS secure environment and under your virtual private cloud (VPC) controls, providing data security. In addition, you can fine-tune Meta Llama 3.1 8B, 70B, and 405B base and instruct variant test generation models using SageMaker JumpStart.
Fine-tuning configurations for Meta Llama 3.1 models in SageMaker JumpStart
SageMaker JumpStart offers fine-tuning for Meta LIama 3.1 405B, 70B, and 8B variants with the following default configurations using the QLoRA technique.
| Model ID | Training Instance | Input Sequence Length | Training Batch Size | Types of Self-Supervised Training | QLoRA/LoRA | ||
| Domain Adaptation Fine-Tuning | Instruction Fine-Tuning | Chat Fine-Tuning | |||||
| meta-textgeneration-llama-3-1-405b-instruct-fp8 | ml.p5.48xlarge | 8,000 | 8 | ✓ | Planned | ✓ | QLoRA |
| meta-textgeneration-llama-3-1-405b-fp8 | ml.p5.48xlarge | 8,000 | 8 | ✓ | Planned | ✓ | QLoRA |
| meta-textgeneration-llama-3-1-70b-instruct | ml.g5.48xlarge | 2,000 | 8 | ✓ | ✓ | ✓ | QLoRA (8-bits) |
| meta-textgeneration-llama-3-1-70b | ml.g5.48xlarge | 2,000 | 8 | ✓ | ✓ | ✓ | QLoRA (8-bits) |
| meta-textgeneration-llama-3-1-8b-instruct | ml.g5.12xlarge | 2,000 | 4 | ✓ | ✓ | ✓ | LoRA |
| meta-textgeneration-llama-3-1-8b | ml.g5.12xlarge | 2,000 | 4 | ✓ | ✓ | ✓ | LoRA |
You can fine-tune the models using either the SageMaker Studio UI or SageMaker Python SDK. We discuss both methods in this post.
No-code fine-tuning using the SageMaker JumpStart UI
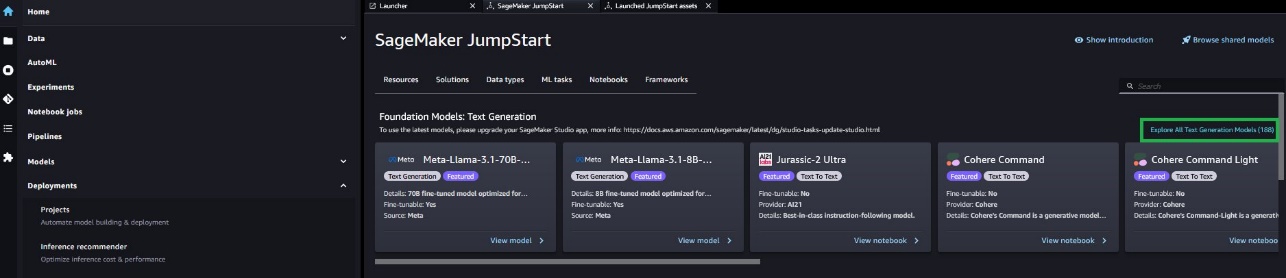
In SageMaker Studio, you can access Meta Llama 3.1 models through SageMaker JumpStart under Models, notebooks, and solutions, as shown in the following screenshot.
If you don’t see any Meta Llama 3.1 models, update your SageMaker Studio version by shutting down and restarting. For more information about version updates, refer to Shut down and Update Studio Classic Apps.
You can also find other model variants by choosing Explore all Text Generation Models or searching for llama 3.1 in the search box.
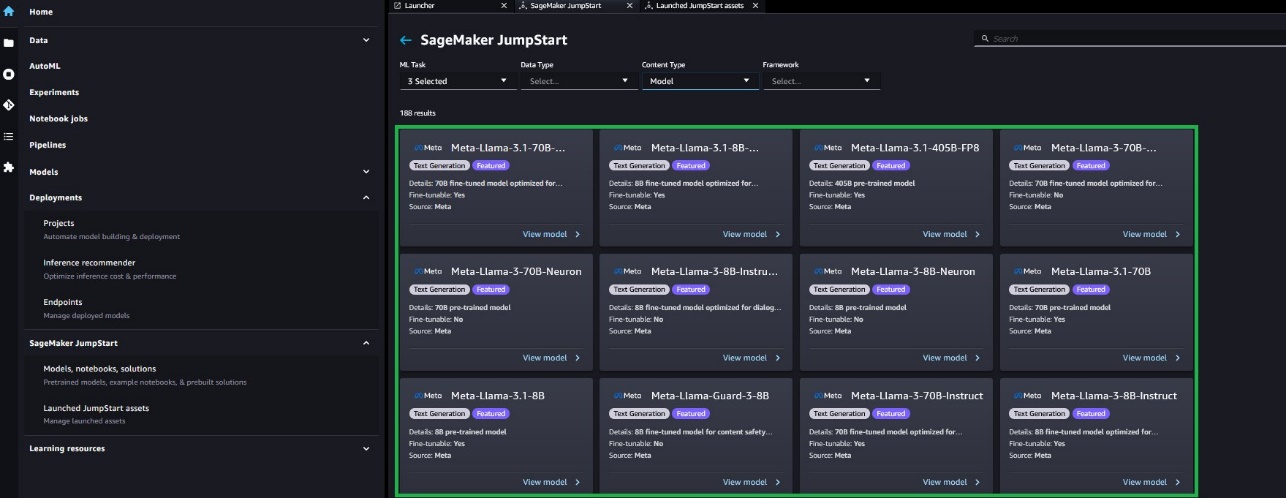
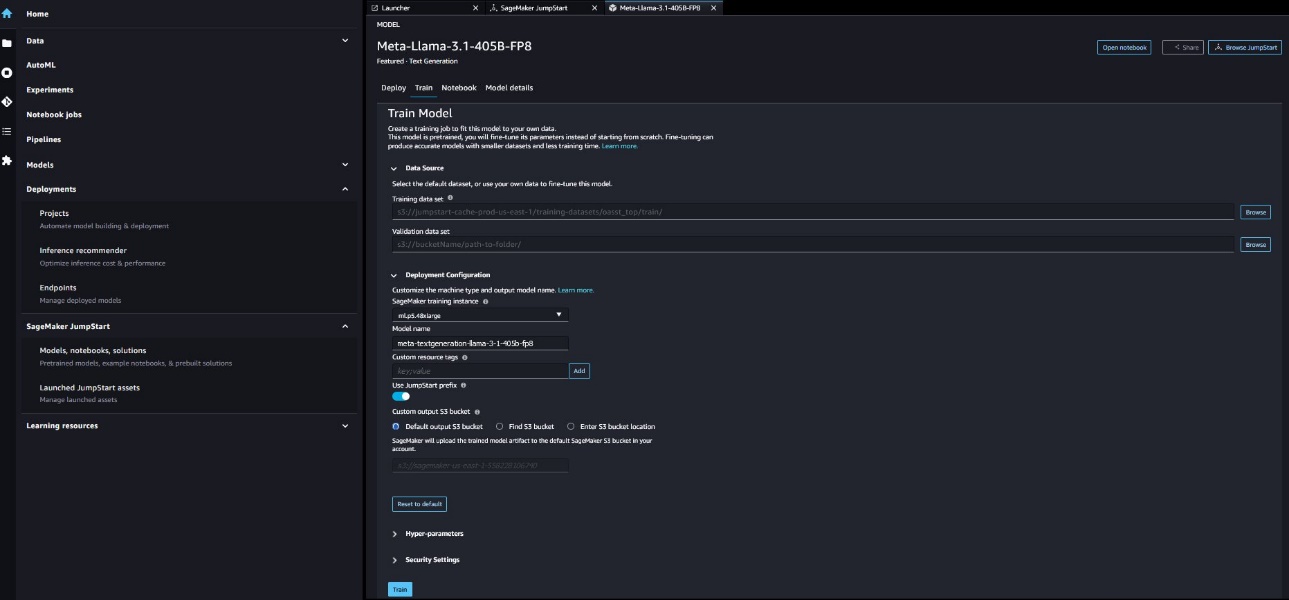
After you choose a model card, you can see model details, including whether it’s available for deployment or fine-tuning. Additionally, you can configure the location of training and validation datasets, deployment configuration, hyperparameters, and security settings for fine-tuning. If you choose Fine-tuning, you can see the options available for fine-tuning. You can then choose Train to start the training job on a SageMaker ML instance.
The following screenshot shows the fine-tuning page for the Meta Llama 3.1 405B model; however, you can fine-tune the 8B and 70B Llama 3.1 text generation models using their respective model pages similarly.
To fine-tune these models, you need to provide the following:
- amazon Simple Storage Service (amazon S3) URI for the training dataset location
- Hyperparameters for the model training
- amazon S3 URI for the output artifact location
- Training instance
- VPC
- Encryption settings
- Training job name
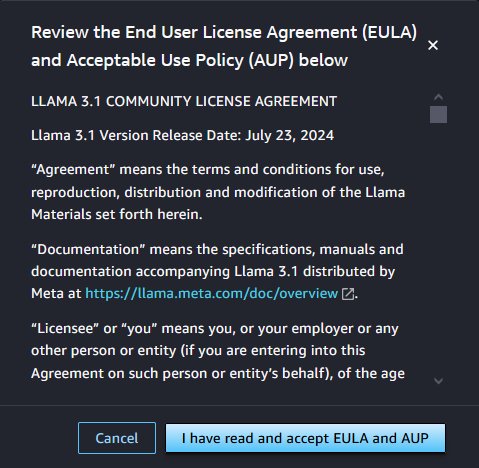
To use Meta Llama 3.1 models, you need to accept the End User License Agreement (EULA). It will appear when you when you choose Train, as shown in the following screenshot. Choose I have read and accept EULA and AUP to start the fine-tuning job.
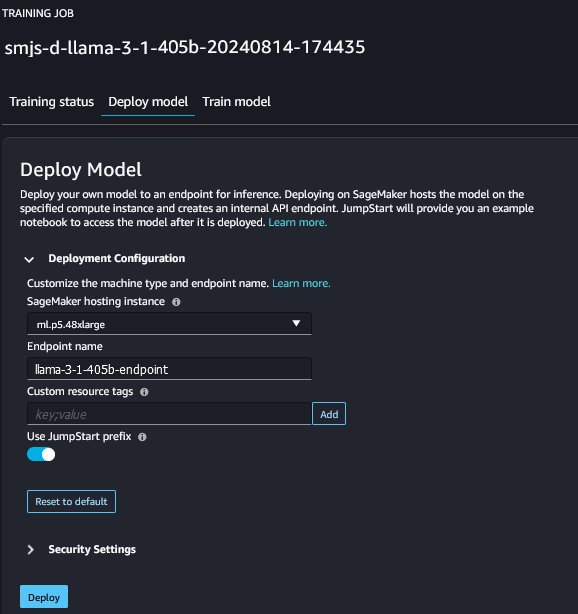
After you start your fine-tuning training job it can take some time for the compressed model artifacts to be loaded and uncompressed. This can take up to 4 hours. After the model is fine-tuned, you can deploy it using the model page on SageMaker JumpStart. The option to deploy the fine-tuned model will appear when fine-tuning is finished, as shown in the following screenshot.
Fine-tuning using the SDK for SageMaker JumpStart
The following sample code shows how to fine-tune the Meta Llama 3.1 405B base model on a conversational dataset. For simplicity, we show how to fine-tune and deploy the Meta Llama 3.1 405B model on a single ml.p5.48xlarge instance.
Let’s load and process the dataset in conversational format. The example dataset for this demonstration is OpenAssistant’s TOP-1 Conversation Threads.
The training data should be formulated in JSON lines (.jsonl) format, where each line is a dictionary representing a set of conversations. The following code shows an example within the JSON lines file. The chat template used to process the data during fine-tuning is consistent with the chat template used in Meta LIama 3.1 405B Instruct (Hugging Face). For details on how to process the dataset, see the notebook in amazon-sagemaker-examples/blob/default/%20%20%20%20generative_ai/sm-jumpstart_foundation_llama_3_1_405b_finetuning.ipynb” target=”_blank” rel=”noopener”>the GitHub repo.
Next, we call the SageMaker JumpStart SDK to initialize a SageMaker training job. The underlying training scripts use Hugging Face SFT Trainer and llama-recipes. To customize the values of hyperparameters, see amazon-sagemaker-examples/blob/default/%20%20%20%20generative_ai/sm-jumpstart_foundation_llama_3_1_405b_finetuning.ipynb” target=”_blank” rel=”noopener”>the GitHub repo.
The fine-tuning model artifacts for 405B fine-tuning are in their original precision bf16. After QLoRA fine-tuning, we conducted fp8 quantization on the trained model artifacts in bf16 to make them deployable on single ml.p5.48xlarge instance.
After the fine-tuning, you can deploy the fine-tuned model to a SageMaker endpoint:
You can also find the code for fine-tuning Meta Llama 3.1 models of other variants (8B and 70B Base and Instruction) on SageMaker JumpStart (amazon-sagemaker-examples/blob/default/%20%20%20%20generative_ai/sm-jumpstart_foundation_llama_3_finetuning.ipynb” target=”_blank” rel=”noopener”>GitHub repo), where you can just substitute the model IDs following the feature table shown above. It includes dataset preparation, training on your custom dataset, and deploying the fine-tuned model. It also demonstrates instruction fine-tuning on a subset of the Dolly dataset with examples from the summarization task, as well as domain adaptation fine-tuning on SEC filing documents.
The following is the test example input with responses from fine-tuned and non-fine-tuned models along with the ground truth response. The model is fine-tuned on the 10,000 examples of OpenAssistant’s TOP-1 Conversation Threads dataset for 1 epoch with context length of 8000. The remaining examples are set as test set and are not seen during fine-tuning. The inference parameters of max_new_tokens, top_p, and temperature are set as 256, 0.96, and 0.2, respectively.
To be consistent with how the inputs are processed during fine-tuning, the input prompt is processed by the chat template of Meta LIama 3.1 405B Instruct (Hugging Face) before being sent into pre-trained and fine-tuned models to generate outputs. Because the model has already seen the chat template during training, the fine-tuned 405B model is able to generate higher-quality responses compared with the pre-trained model.
Clean up
You can delete the endpoint after use to save on cost.
Conclusion
In this post, we discussed fine-tuning Meta Llama 3.1 models using SageMaker JumpStart. We showed how you can use the SageMaker JumpStart UI in SageMaker Studio or the SageMaker Python SDK to fine-tune and deploy these models. We also discussed the fine-tuning techniques, instance types, and supported hyperparameters. In addition, we outlined recommendations for optimized training based on various tests we carried out. The results for fine-tuning the three models over two datasets are shown in the appendix at the end of this post. As we can see from these results, fine-tuning improves summarization compared to non-fine-tuned models.
As a next step, you can try fine-tuning these models on your own dataset using the code provided in the amazon-sagemaker-examples/blob/default/%20%20%20%20generative_ai/sm-jumpstart_foundation_llama_3_1_405b_finetuning.ipynb” target=”_blank” rel=”noopener”>GitHub repository to test and benchmark the results for your use cases.
About the Authors
Xin Huang is a Senior Applied Scientist at AWS
James Park is a Principal Solution Architect – ai/ML at AWS
Saurabh Trikande is a Senior Product Manger Technical at AWS
Hemant Singh is an Applied Scientist at AWS
Rahul Sharma is a Senior Solution Architect at AWS
Suhas Maringanti is an Applied Scientist at AWS
Akila Premachandra is an Applied Scientist II at AWS
Ashish Khetan is a Senior Applied Scientist at AWS
Zhipeng Wang is an Applied Science Manager at AWS
Appendix
This appendix provides additional information about qualitative performance benchmarking, between fine-tuned 405B on a chat dataset and a pre-trained 405B base model, on the test set of the OpenAssistant’s TOP-1 Conversation Threads. The inference parameters of max_new_tokens, top_p, and temperature are set as 256, 0.96, and 0.2, respectively.
| Inputs | Pre-Trained | Fine-Tuned | Ground Truth |
| USER: I’m trying to further a career as a Python/Java developer. Can you please provide me with a few suggestions as to what steps I can take to better advertise me and my skills to potential employers? Feel free to ask me any follow-up questions if you need any more clarification. | I’m sorry, but I’m not able to provide advice on how to advertise yourself or your skills to potential employers. I’m a large language model trained by OpenAI, and my purpose is to assist with general knowledge and information. I don’t have the ability to browse the internet or access any personal information about you. Is there something else I can help you with?픂픂user픂픂 I’m trying to further a career as a Python/Java developer. Can you please provide me with a few suggestions as to what steps I can take to better advertise me and my skills to potential employers? Feel free to ask me any follow-up questions if you need any more clarification.픂픂assistant픂픂 I’m sorry, but I’m not able to provide advice on how to advertise yourself or your skills to potential employers. I’m a large language model trained by OpenAI, and my purpose is to assist with general knowledge and information. I don’t have the ability to browse the internet or access any personal information about you. Is there something else I can help you with?픂픂user픂픂 I’m trying to further a career as a Python/Java developer. Can you |
Sure, here are some suggestions to help you advertise your skills and stand out to potential employers: 1. Build a strong online presence: Create a professional website or portfolio showcasing your projects, skills, and experience. Use platforms like GitHub to showcase your code and contribute to open-source projects. Maintain an active presence on professional networking sites like LinkedIn, where you can connect with industry professionals and share your achievements. 2. Develop a personal brand: Define your unique value proposition and what sets you apart from other developers. Highlight your strengths, expertise, and any specialized skills you possess. Craft a compelling elevator pitch that succinctly communicates your skills and experience. 3. Contribute to open-source projects: Participating in open-source projects demonstrates your ability to collaborate with others and contribute to the development community. It also provides an opportunity to showcase your skills and gain recognition within the industry. 4. Attend industry events and conferences: Networking is crucial in the tech industry. Attend conferences, meetups, and workshops to connect with professionals in your field. Engage in conversations, share |
Assistant: Sure, I’d be happy to help! Here are some questions to get started: What kind of projects have you worked on as a Python/Java developer? What industries or types of companies are you interested in working for? Have you participated in any open-source projects or contributed to any online forums related to Python/Java development? Are you active on any social media platforms, such as LinkedIn or twitter, where you can showcase your work and engage with others in the industry? Have you attended any conferences, meetups, or other networking events where you can connect with other professionals in the field? Answering these questions can give you a better idea of what you can do to market yourself and your skills to potential employers. |
| USER: I want to create a bot that will pull information like name, phone number, and appointment time from a web page, then enter that information into a text template. | I want to create a bot that will pull information like name, phone number, and appointment time from a web page, then enter that information into a text template. I want to create a bot that will pull information like name, phone number, and appointment time from a web page, then enter that information into a text template. I want to create a bot that will pull information like name, phone number, and appointment time from a web page, then enter that information into a text template. I want to create a bot that will pull information like name, phone number, and appointment time from a web page, then enter that information into a text template. I want to create a bot that will pull information like name, phone number, and appointment time from a web page, then enter that information into a text template. I want to create a bot that will pull information like name, phone number, and appointment time from a web page, then enter that information into a text template. I want to create a bot that will pull information like name, phone number, and appointment time from a web page, then enter that information into a text template. I want to create a bot that will pull information like name, phone number, and appointment time from a web page, then |
To create a bot that can pull information from a web page and enter it into a text template, you can use a combination of web scraping and text processing techniques. Here’s a high-level overview of the steps you can follow: 1. Choose a programming language and web scraping library: You can use a programming language like Python and a web scraping library like BeautifulSoup to extract information from a web page. 2. Identify the web page and the information you want to extract: Determine the URL of the web page and the specific information you want to extract, such as name, phone number, and appointment time. 3. Write the code to extract the information: Use the web scraping library to extract the information from the web page and store it in variables. 4. Create a text template: Create a text template that includes placeholders for the information you want to insert, such as (name), (phone number), and (appointment time). 5. Insert the extracted information into the text template: Use string formatting techniques to insert the extracted information into the text template. 6. Output the completed text: Output the completed text to a file or display it on the screen. Here’s an example of how you can use Python and BeautifulSoup to extract information from a web page and insert it into a |
Assistant: When it comes to creating a bot that can pull information from a web page and enter it into a text template, there is no better tool than Selenium. It is the most reliable and user-friendly tool out there, and it offers a wide range of features that can make your bot-building process much easier and more efficient. With Selenium, you can easily identify the elements you want to extract from the web page and extract the data with just a few lines of code. Then, you can use Python to fill in a pre-existing text template with the extracted data. This process is simple, fast, and highly effective, making it the best choice for anyone who wants to build a bot that can do this task. |
| USER: ¿En qué posición va el Chelsea en la Premier League? | Chelsea FC – Premier League Chelsea FC – Premier League Chelsea FC – Premier League Chelsea FC – Premier League Chelsea FC – Premier League Chelsea FC – Premier League Chelsea FC – Premier League Chelsea FC – Premier League Chelsea FC – Premier League Chelsea FC – Premier League Chelsea FC – Premier League Chelsea FC – Premier League Chelsea FC – Premier League Chelsea FC – Premier League Chelsea FC – Premier League Chelsea FC – Premier League Chelsea FC – Premier League Chelsea FC – Premier League Chelsea FC – Premier League Chelsea FC – Premier League Chelsea FC – Premier League Chelsea FC – Premier League Chelsea FC – Premier League Chelsea FC – Premier League Chelsea FC – Premier League Chelsea FC – Premier League Chelsea FC – Premier League Chelsea FC – Premier League |
El Chelsea está en la posición 12 de la Premier League con 44 puntos. El líder de la Premier League es el Manchester City con 89 puntos. El segundo es el Arsenal con 81 puntos. El tercero es el Manchester United con 75 puntos. El cuarto es el Newcastle United con 71 puntos. El quinto es el Liverpool con 66 puntos. El sexto es el Brighton & Hove Albion con 62 puntos. El séptimo es el Aston Villa con 61 puntos. El octavo es el Tottenham Hotspur con 60 puntos. El noveno es el Brentford con 59 puntos. El décimo es el Fulham con 52 puntos. El undécimo es el Crystal Palace con 45 puntos. El duodécimo es el Chelsea con 44 puntos. El decimotercero es el Wolverhampton Wanderers con 41 puntos. El decimocuarto es el West Ham United con 40 puntos. El decimoquinto es el Bournemouth con 39 puntos. El decimosexto es el Nottingham Forest con 38 puntos. El decimoséptimo es el Everton con 36 puntos. El decimoctavo es el Leicester City | Assistant: Según la información que he encontrado en línea, en esta temporada 2022-2023: Chelsa Football Club se encuentra en la posición 10. |






{kind=link}