

Imagen por rawpixel.com en Freepik
No importa en qué negocio se encuentre, saber cómo analizar datos es más importante que nunca en la era basada en datos. El análisis de datos permitiría a las empresas seguir siendo competitivas y proporcionaría la capacidad de tomar mejores decisiones.
La importancia del análisis de datos impulsa a cada individuo a saber cómo realizar el análisis de datos. Sin embargo, a veces lleva demasiado tiempo realizar un análisis de datos. Es por eso que podemos confiar en ChatGPT para crear un informe completo a partir de nuestro archivo de datos.
Este artículo explorará cinco pasos simples para crear informes analíticos completos a partir de su archivo CSV. Estos cinco pasos incluyen:
Paso 1: importar el archivo CSV
Paso 2: resumen de datos y preprocesamiento
Paso 3: Análisis de datos
Paso 4: visualización de datos
Paso 5: generación de informes
Como requisito previo, este artículo asume que el lector se ha suscrito a ChatGPT Plus. Con eso en mente, comencemos.
El primer paso es preparar el archivo CSV que desea analizar y crear un informe. Este archivo podría provenir de cualquier fuente confiable, pero este artículo usaría el conjunto de datos Telecom Churn de Kaggle.
Asegúrese de que los datos estén estructurados, organizados y tengan un encabezado claro. Si tiene un objetivo determinado que desea analizar, no olvide incluir esos datos en el archivo. En nuestro ejemplo, intentaríamos realizar un análisis de la columna de abandono.
Con los datos listos, adjúntelos al ChatGPT y deje que el modelo haga su trabajo.
El siguiente paso es obtener el resumen de datos de nuestro archivo CSV y preprocesarlos. Ingrese el siguiente mensaje mientras carga los datos.
Provide the data summary to this file and perform appropriate data processing for the dataset.El mensaje anterior proporciona los siguientes resultados:
Aquí está el resumen de su conjunto de datos:
Número de filas: 3333
Número de columnas: 11
Nombres de columnas:
Batir
Semanas de cuenta
Renovación de contrato
Plan de datos
Uso de datos
LlamadasServicioCliente
DíaMinutos
Llamadas diurnas
Cargo mensual
Tarifa por excedente
RoamMins
Tipos de datos:
Entero: abandono, semanas de cuenta, renovación de contrato, plan de datos, llamadas de servicio al cliente, llamadas diarias
Flotante: uso de datos, minutos diarios, carga mensual, tarifa por exceso, minutos de itinerancia
Valores faltantes: No faltan valores en ninguna de las columnas.
ChatGPT claramente pudo leer bien los datos y pudo proporcionar el conjunto de datos proporcionado. El siguiente resultado es el preprocesamiento de datos del ChatGPT.
Dado que no faltan valores en el conjunto de datos, el enfoque principal de la limpieza y el preprocesamiento de datos estará en:
- Comprobar si hay valores atípicos o anomalías en los datos.
- Normalizar o estandarizar los datos si es necesario, especialmente para columnas con valores numéricos continuos.
- Convertir datos categóricos a un formato adecuado para el análisis, si es necesario.
Procedamos con estos pasos.
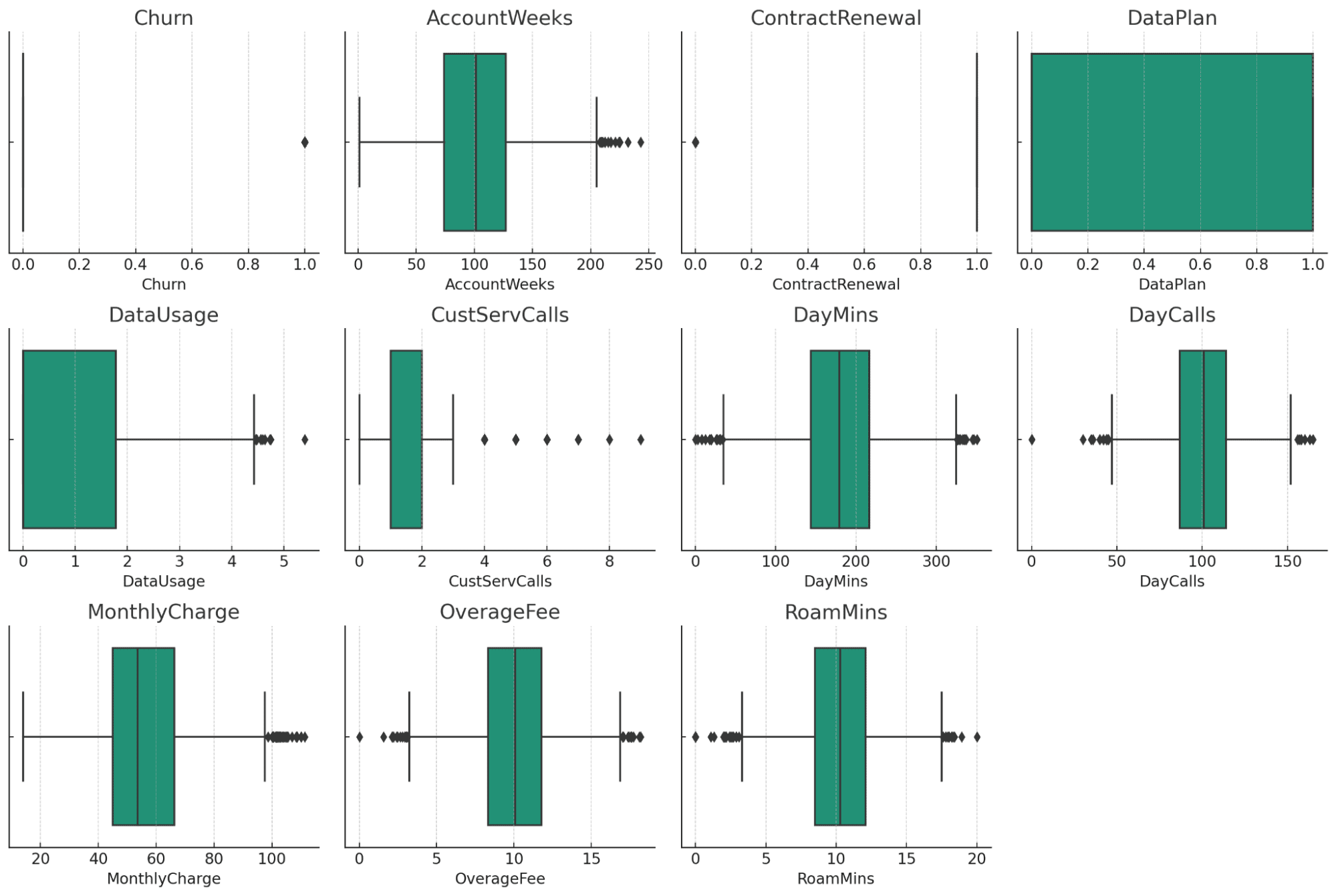
Los diagramas de caja proporcionan una descripción visual de los posibles valores atípicos en cada columna numérica de su conjunto de datos. He aquí algunas observaciones:
- AccountWeeks, CustServCalls, DayCalls: estas columnas muestran una distribución bastante normal con algunos valores atípicos.
- DataUsage, DayMins, MonthlyCharge, OverageFee, RoamMins: estas columnas también muestran algunos valores atípicos, pero parecen estar dentro de un rango razonable, considerando la naturaleza de los datos.
- Rotación, renovación de contrato, plan de datos: al ser datos categóricos/binarios, estas columnas no muestran valores atípicos tradicionales.
Dada esta información, los próximos pasos en la limpieza y el preprocesamiento de datos podrían incluir:
- Manejo de valores atípicos: podemos decidir si eliminamos, limitamos o manejamos de otro modo los valores atípicos en función de sus necesidades analíticas específicas y su conocimiento del dominio.
- Transformación de datos: si es necesario, podemos normalizar o estandarizar columnas como DayMins, MonthlyCharge, etc., especialmente si planea utilizar algoritmos que sean sensibles a la escala de los datos.
- Codificación de datos categóricos: convierta datos categóricos a un formato adecuado para el análisis, si se requiere dicha transformación.
Puede dejar que ChatGPT realice pasos adicionales para la limpieza y el preprocesamiento de datos o dejarlo como está. Para este ejemplo, continuaríamos con los siguientes pasos.
A continuación, realizaríamos un análisis de datos con ChatGPT. El análisis de datos depende de lo que se quiera lograr. En nuestro caso, queremos realizar un análisis de datos desde el Churn POV.
Usamos el siguiente mensaje para ejecutar el análisis de datos con ChatGPT para el caso anterior.
Please perform the data analysis based on the data above with respect to the churn data.El análisis de los datos se puede ver en el siguiente resultado.
Para realizar un análisis de datos con respecto a los datos de abandono, nos centraremos en comprender cómo se relacionan los diferentes factores con el abandono de clientes. La deserción, al ser una variable binaria (0 para no deserción, 1 para deserción), generalmente se analiza mediante métodos de clasificación y examinando las relaciones con otras variables. Aquí está el plan:
- Análisis de correlación: para comenzar, veremos cómo cada característica numérica se correlaciona con la deserción. Esto nos da una comprensión inicial de qué factores podrían estar más estrechamente relacionados con la deserción.
- Pruebas estadísticas: para variables categóricas como ContractRenewal y DataPlan, podemos utilizar pruebas estadísticas para ver si existen diferencias significativas en las tasas de abandono entre diferentes categorías.
- Análisis visual: crearemos algunas visualizaciones para explorar más a fondo estas relaciones. Esto incluye comparar las tasas de abandono entre diferentes grupos y trazar variables clave en función del abandono.
- Estadísticas resumidas: proporcionaremos estadísticas resumidas para diferentes grupos según el estado de abandono para ver si hay diferencias notables en las medias o distribuciones.
Comencemos con el análisis de correlación y luego pasemos a los siguientes pasos.
Análisis de correlación con abandono
La correlación de diferentes variables con la deserción es la siguiente (de la correlación negativa más fuerte a la correlación positiva más fuerte):
Correlación negativa:
- Renovación de contrato: correlación negativa más fuerte. Indica que los clientes que no renuevan sus contratos tienen más probabilidades de abandonar.
- Plan de datos: los clientes sin un plan de datos tienen un poco más de probabilidad de abandonar.
- Uso de datos: un mayor uso de datos disminuye ligeramente la probabilidad de abandono.
Correlacion positiva:
- AccountWeeks, DayCalls: correlación positiva muy débil, lo que sugiere un impacto mínimo en la deserción.
- RoamMins: un ligero aumento en la probabilidad de abandono con más minutos de roaming.
- Cargo mensual: tasas de abandono ligeramente más altas con cargos mensuales aumentados.
- Tarifa por excedente: las tarifas por excedente más altas están moderadamente correlacionadas con una mayor deserción.
- DayMins: los minutos diarios más altos se correlacionan moderadamente con una mayor deserción.
- CustServCalls: Fuerte correlación positiva. Más llamadas de servicio al cliente se asocian con mayores tasas de abandono.
Con base en estas correlaciones, parece que factores como la renovación de contratos, las llamadas al servicio de atención al cliente, los minutos diarios y las tarifas por excedente están más estrechamente relacionados con la deserción. Podemos explorar más a fondo estos factores mediante análisis visual y pruebas estadísticas, especialmente para variables categóricas como ContractRenewal y DataPlan.
Análisis visual
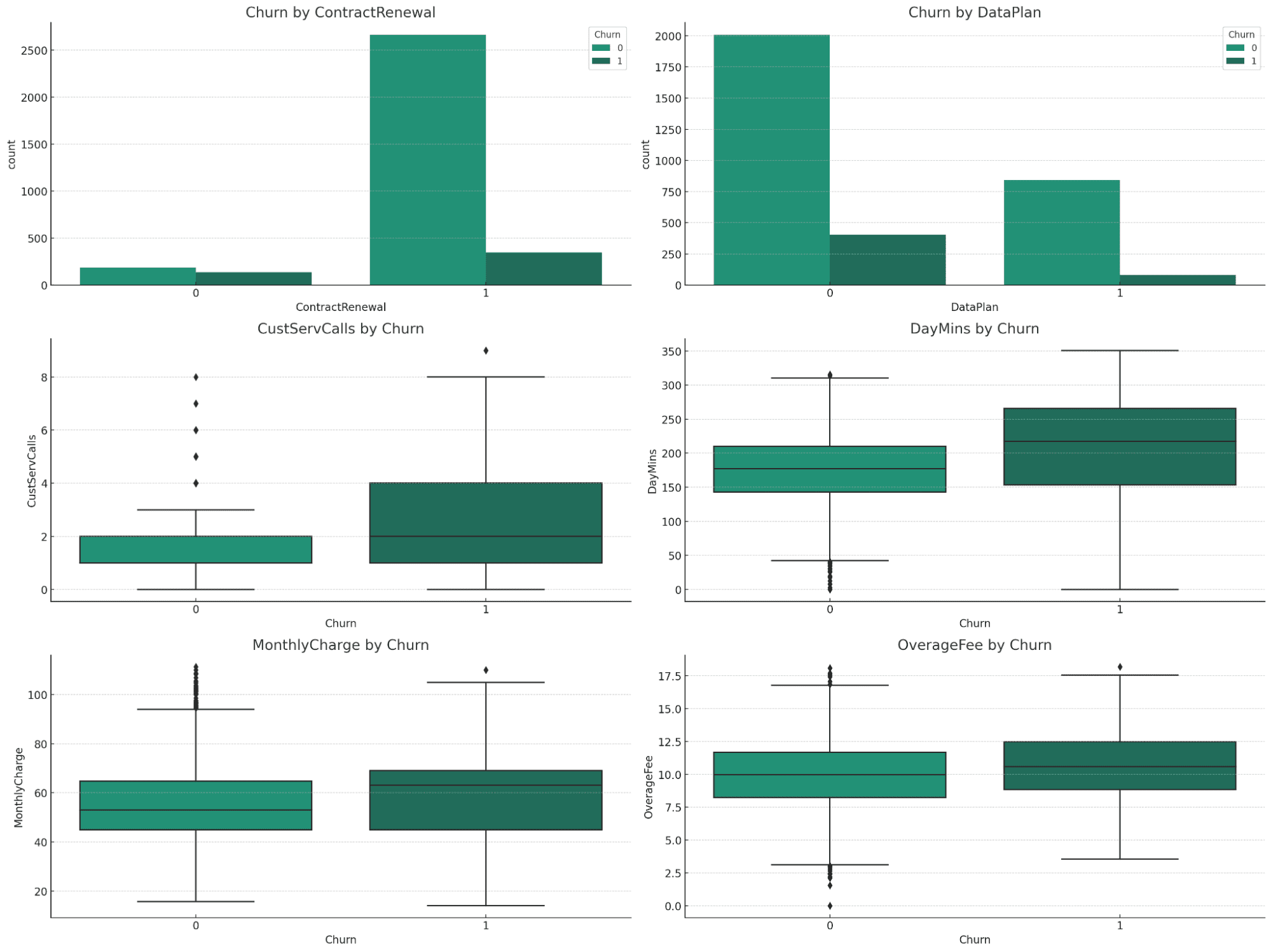
Las visualizaciones ofrecen información valiosa sobre la relación entre las diferentes variables y la deserción:
Rotación por renovación de contrato y plan de datos:
- Renovación de contrato: es evidente una diferencia significativa en las tasas de abandono. Los clientes que no renovaron sus contratos muestran una mayor tasa de abandono.
- Plan de datos: existe una diferencia notable en las tasas de abandono según si los clientes tienen un plan de datos o no, y aquellos sin un plan de datos muestran un mayor abandono.
Variables numéricas (CustServCalls, DayMins, MonthlyCharge, OverageFee) por abandono:
- CustServCalls: los clientes con un mayor número de llamadas de servicio al cliente tienden a abandonar más.
- DayMins: más minutos diarios se asocian con una mayor probabilidad de abandono.
- Cargo mensual: los cargos mensuales más altos se correlacionan con una mayor tasa de abandono.
- Tarifa por excedente: Las tarifas por excedente más altas también están asociadas con una mayor deserción.
Conclusiones del análisis
- El estado de renovación del contrato y la presencia de un plan de datos son factores importantes en la pérdida de clientes.
- El uso elevado (en términos de minutos diarios) y los cargos elevados (cargos mensuales y tarifas por exceso) están asociados con tasas de abandono más altas.
- Un mayor número de llamadas al servicio de atención al cliente es un fuerte indicador de una posible pérdida de clientes.
Próximos pasos
Con base en estos conocimientos, se pueden desarrollar estrategias específicas para reducir la deserción, como mejorar el servicio al cliente, revisar las estrategias de precios u ofrecer incentivos para la renovación de contratos y suscripciones a planes de datos.
Con un solo mensaje, podemos ver qué tan bien ChatGPT podría brindarnos el análisis de datos completo y generar información a partir de los datos. Puede modificar los objetivos del análisis y comenzar desde allí.
La visualización de datos es una actividad de apoyo para mejorar el análisis de datos y el informe general. Al tener la visualización, podemos tener un informe más completo para comprender nuestros datos.
Usando el siguiente mensaje, podemos realizar la visualización de datos con ChatGPT.
Please perform data visualization from the data analysis to explain the data better.Para mejorar la comprensión de los resultados del análisis de datos, crearé una serie de visualizaciones que representen claramente los hallazgos clave relacionados con la pérdida de clientes. Estas visualizaciones incluirán:
- Gráficos de barras para variables categóricas:
- Comparación de tasas de abandono de clientes con y sin renovación de contrato.
- Comparación de tasas de abandono de clientes con y sin plan de datos.
- Gráficos de caja para variables numéricas clave:
- Llamadas de servicio al cliente vs abandono.
- Minutos diarios vs abandono.
- Cargos mensuales vs abandono.
- Tarifas por excedente frente a abandono.
- Mapa de calor de correlación:
Visualizar la correlación de todas las variables con la deserción.
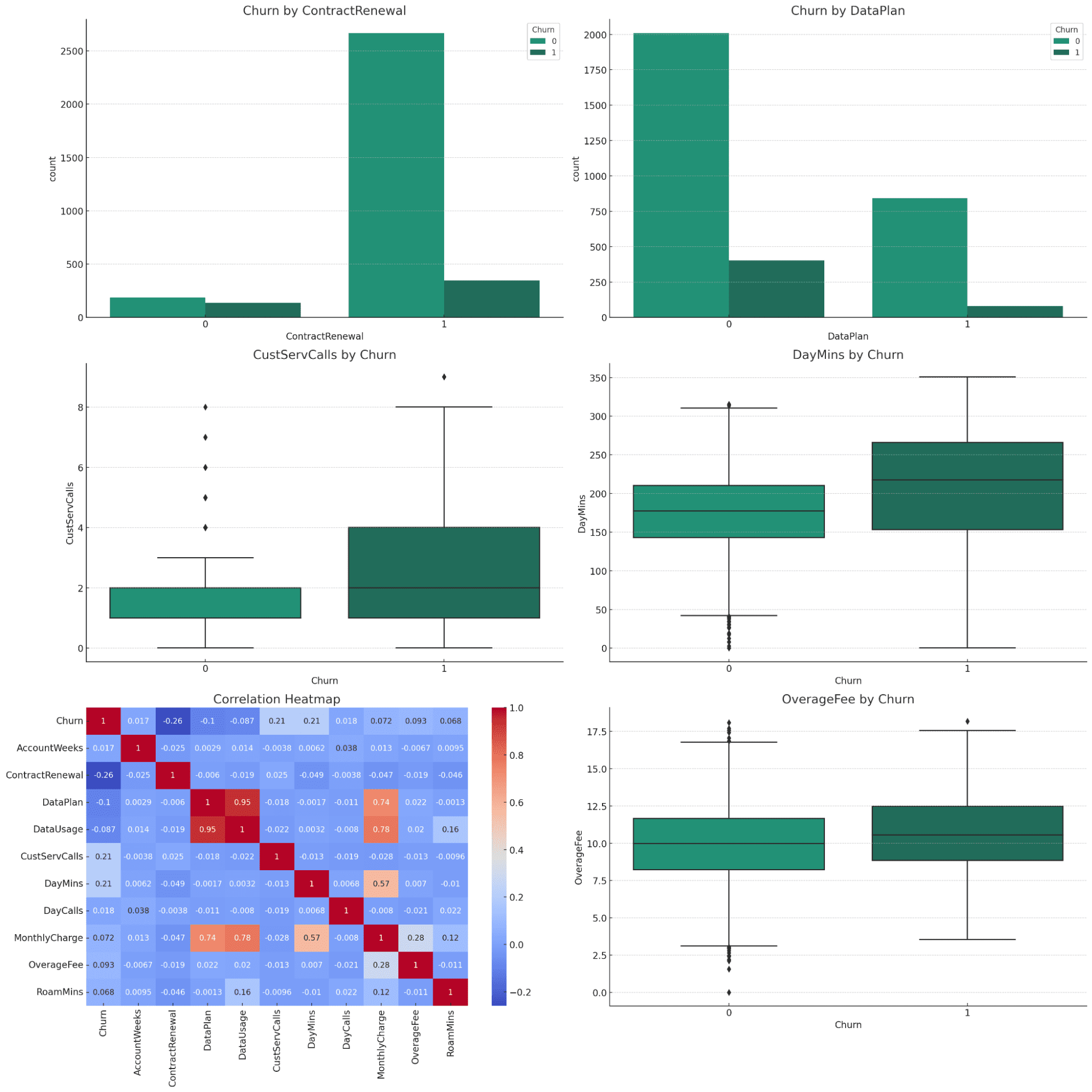
La visualización mostraría todos los gráficos importantes que encapsulan todo el conjunto de datos. Podemos solicitar descripciones más detalladas de cada trama, que podrás probar de forma independiente.
El último paso es generar el informe basado en los pasos anteriores. Desafortunadamente, es posible que ChatGPT no capture toda la descripción y la información del análisis de datos, pero aún podemos tener la versión simple del informe.
Utilice el siguiente mensaje para generar un informe PDF basado en el análisis anterior.
Please provide me with the pdf report from the first step to the last step.Obtendrá el resultado del enlace PDF con su análisis anterior cubierto. Intente repetir los pasos si cree que el resultado es inadecuado o si hay cosas que desea cambiar.
El análisis de datos es una actividad que todo el mundo debería conocer, ya que es una de las habilidades más necesarias en la era actual. Sin embargo, aprender a realizar análisis de datos puede llevar mucho tiempo. Con ChatGPT podemos minimizar todo ese tiempo de actividad.
En este artículo, analizamos cómo generar un informe analítico completo a partir de archivos CSV en 5 pasos. ChatGPT proporciona a los usuarios una actividad de análisis de datos de un extremo a otro, desde la importación del archivo hasta la producción del informe.
Cornellius Yudha Wijaya es subgerente de ciencia de datos y redactor de datos. Mientras trabaja a tiempo completo en Allianz Indonesia, le encanta compartir consejos sobre Python y datos a través de las redes sociales y los medios escritos.





{kind=link}