 NEWSLETTER
NEWSLETTER
Las empresas tienen acceso a cantidades masivas de datos, muchos de los cuales son difíciles de descubrir porque no están estructurados. Los enfoques convencionales para analizar datos no estructurados utilizan palabras clave o coincidencias de sinónimos. No capturan el contexto completo de un documento, lo que los hace menos efectivos al tratar con datos no estructurados.
Por el contrario, las incrustaciones de texto utilizan capacidades de aprendizaje automático (ML) para capturar el significado de datos no estructurados. Las incrustaciones se generan mediante modelos de lenguaje representacional que traducen texto en vectores numéricos y codifican información contextual en un documento. Esto permite aplicaciones como búsqueda semántica, generación aumentada de recuperación (RAG), modelado de temas y clasificación de texto.
Por ejemplo, en la industria de servicios financieros, las aplicaciones incluyen la extracción de información de informes de ganancias, la búsqueda de información de estados financieros y el análisis de sentimientos sobre acciones y mercados que se encuentran en noticias financieras. Las incrustaciones de texto permiten a los profesionales de la industria extraer información de los documentos, minimizar errores y aumentar su rendimiento.
En esta publicación, mostramos una aplicación que puede buscar y consultar noticias financieras en diferentes idiomas utilizando los modelos Embed y Rerank de Cohere con Amazon Bedrock.
Modelo de incrustación multilingüe de Cohere
Cohere es una plataforma de inteligencia artificial empresarial líder que crea modelos de lenguaje grande (LLM) de clase mundial y soluciones impulsadas por LLM que permiten a las computadoras buscar, capturar significado y conversar en texto. Proporcionan facilidad de uso y sólidos controles de seguridad y privacidad.
Modelo de incrustación multilingüe de Cohere genera representaciones vectoriales de documentos para más de 100 idiomas y está disponible en Amazon Bedrock. Esto permite a los clientes de AWS acceder a ella como una API, lo que elimina la necesidad de administrar la infraestructura subyacente y garantiza que la información confidencial permanezca administrada y protegida de forma segura.
El modelo multilingüe agrupa texto con significados similares asignándoles posiciones cercanas entre sí en un espacio vectorial semántico. Con un modelo de incrustación multilingüe, los desarrolladores pueden procesar texto en varios idiomas sin la necesidad de cambiar entre diferentes modelos, como se ilustra en la siguiente figura. Esto hace que el procesamiento sea más eficiente y mejora el rendimiento de las aplicaciones multilingües.
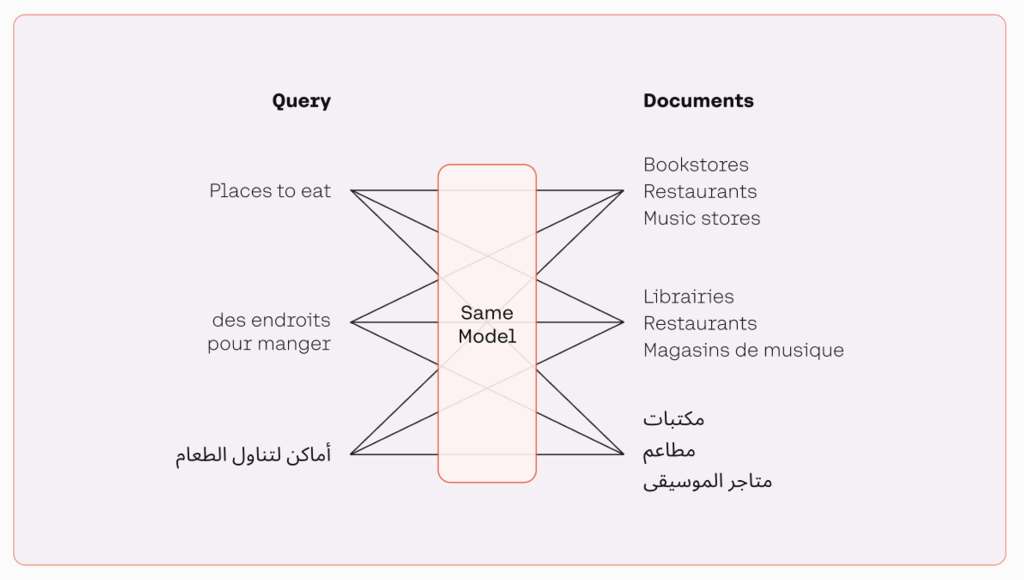
Los siguientes son algunos de los aspectos más destacados del modelo de integración de Cohere:
- Centrarse en la calidad del documento – Los modelos de incrustación típicos están entrenados para medir la similitud entre documentos, pero el modelo de Cohere también mide la calidad de los documentos.
- Mejor recuperación para aplicaciones RAG – Las aplicaciones RAG requieren un buen sistema de recuperación, en el que sobresale el modelo de integración de Cohere.
- Compresión de datos rentable – Cohere utiliza un método de entrenamiento especial que tiene en cuenta la compresión, lo que resulta en ahorros sustanciales de costos para su base de datos vectorial.
Casos de uso para incrustar texto
Las incrustaciones de texto convierten los datos no estructurados en una forma estructurada. Esto le permite comparar, analizar y obtener información objetivamente de todos estos documentos. Los siguientes son casos de uso de ejemplo que permite el modelo de integración de Cohere:
- búsqueda semántica – Permite potentes aplicaciones de búsqueda cuando se combina con una base de datos vectorial, con excelente relevancia basada en el significado de la frase de búsqueda.
- Motor de búsqueda para un sistema más grande. – Encuentra y recupera la información más relevante de fuentes de datos empresariales conectadas para sistemas RAG
- Clasificación de texto – Admite reconocimiento de intenciones, análisis de sentimientos y análisis avanzado de documentos
- Modelado de temas – Convierte una colección de documentos en grupos distintos para descubrir temas y temas emergentes.
Sistemas de búsqueda mejorados con Rerank
En las empresas donde ya existen sistemas convencionales de búsqueda de palabras clave, ¿cómo se introducen capacidades modernas de búsqueda semántica? Para sistemas que han sido parte de la arquitectura de información de una empresa durante mucho tiempo, en muchos casos simplemente no es factible una migración completa a un enfoque basado en incorporaciones.
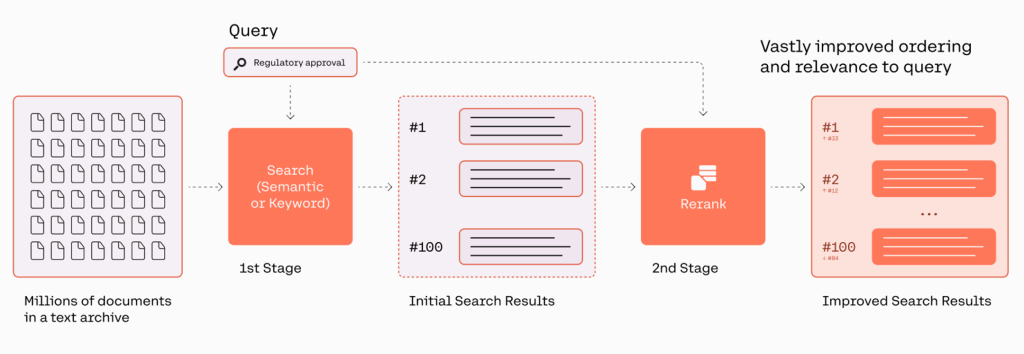
Punto final de reclasificación de Cohere está diseñado para cerrar esta brecha. Actúa como la segunda etapa de un flujo de búsqueda para proporcionar una clasificación de documentos relevantes según la consulta de un usuario. Las empresas pueden conservar un sistema de palabras clave (o incluso semántico) existente para la recuperación de la primera etapa y mejorar la calidad de los resultados de búsqueda con el punto final Rerank en la reclasificación de la segunda etapa.
Rerank proporciona una opción rápida y sencilla para mejorar los resultados de búsqueda al introducir tecnología de búsqueda semántica en la pila de un usuario con una sola línea de código. El punto final también viene con soporte multilingüe. La siguiente figura ilustra el flujo de trabajo de recuperación y reclasificación.
Descripción general de la solución
Los analistas financieros necesitan digerir una gran cantidad de contenido, como publicaciones financieras y medios de comunicación, para mantenerse informados. De acuerdo con la Asociación de Profesionales Financieros (AFP), los analistas financieros dedican el 75% de su tiempo a recopilar datos o administrar el proceso en lugar de realizar análisis de valor agregado. Encontrar la respuesta a una pregunta a través de una variedad de fuentes y documentos es un trabajo tedioso y que requiere mucho tiempo. El modelo de integración de Cohere ayuda a los analistas a buscar rápidamente en numerosos títulos de artículos en varios idiomas para encontrar y clasificar los artículos que son más relevantes para una consulta particular, ahorrando una enorme cantidad de tiempo y esfuerzo.
En el siguiente ejemplo de caso de uso, mostramos cómo el modelo Insertar de Cohere busca y consulta noticias financieras en diferentes idiomas en un canal único. Luego demostramos cómo agregar Rerank a la recuperación de incrustaciones (o agregarlo a una búsqueda léxica heredada) puede mejorar aún más los resultados.
El cuaderno de soporte está disponible en ai/cohere-aws/blob/main/notebooks/bedrock/Financial%20Multilingual%20Embeddings.ipynb” target=”_blank” rel=”noopener”>GitHub.
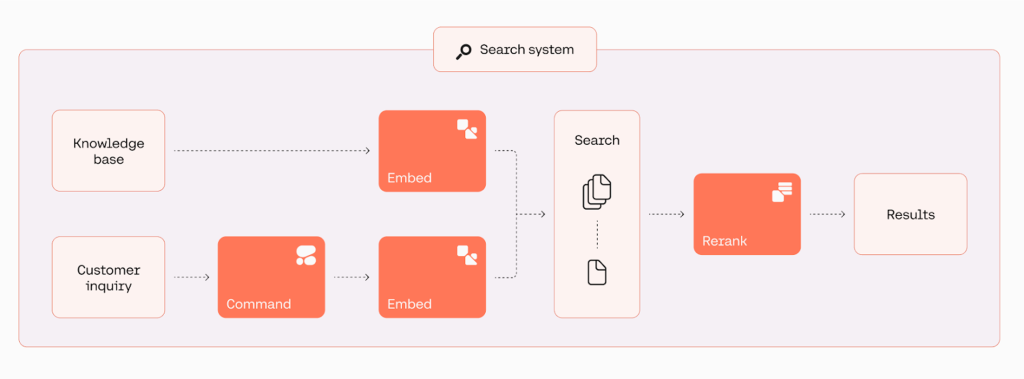
El siguiente diagrama ilustra el flujo de trabajo de la aplicación.
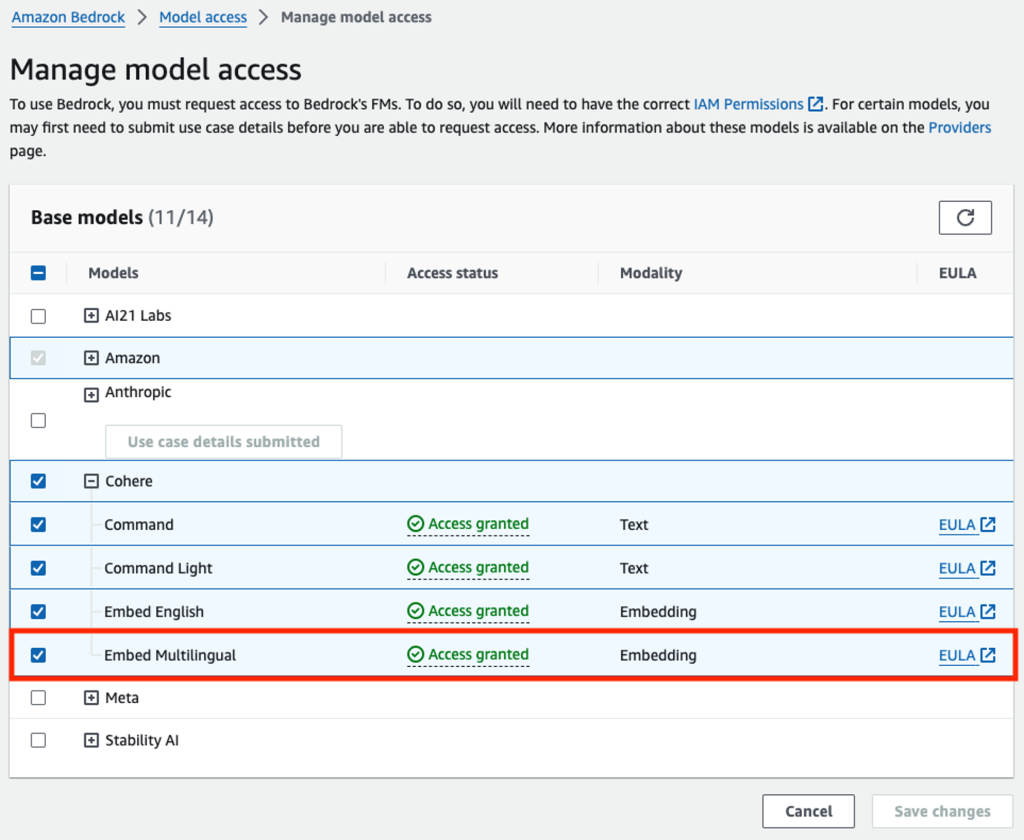
Habilite el acceso al modelo a través de Amazon Bedrock
Los usuarios de Amazon Bedrock deben solicitar acceso a los modelos para que estén disponibles para su uso. Para solicitar acceso a modelos adicionales, elija Acceso al modelo el panel de navegación en la consola de Amazon Bedrock. Para obtener más información, consulte Acceso al modelo. Para este tutorial, debe solicitar acceso al modelo Cohere Embed Multilingual.
Instalar paquetes e importar módulos.
Primero, instalamos los paquetes necesarios e importamos los módulos que usaremos en este ejemplo:
Importar documentos
Utilizamos un conjunto de datos (MultiFIN) que contiene una lista de titulares de artículos del mundo real que cubren 15 idiomas (inglés, turco, danés, español, polaco, griego, finlandés, hebreo, japonés, húngaro, noruego, ruso, italiano, islandés y sueco). ). Este es un conjunto de datos de código abierto seleccionado para el procesamiento del lenguaje natural (NLP) financiero y está disponible en un repositorio de GitHub.
En nuestro caso, hemos creado un archivo CSV con los datos de MultiFIN así como una columna con las traducciones. No utilizamos esta columna para alimentar el modelo; Lo usamos para ayudarnos a seguir cuando imprimimos los resultados para aquellos que no hablan danés o español. Apuntamos a ese CSV para crear nuestro marco de datos:
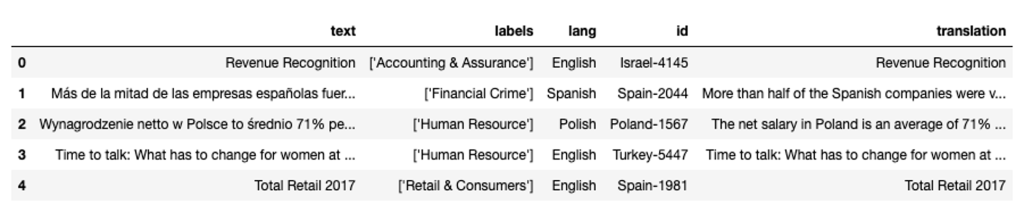
Seleccione una lista de documentos para consultar
MultiFIN cuenta con más de 6.000 registros en 15 idiomas diferentes. Para nuestro caso de uso de ejemplo, nos centramos en tres idiomas: inglés, español y danés. También clasificamos los encabezados por longitud y elegimos los más largos.
Como elegimos los artículos más largos, nos aseguramos de que la longitud no se deba a secuencias repetidas. El siguiente código muestra un ejemplo en el que ese es el caso. Lo limpiaremos.
df('text').iloc(2215)
Nuestra lista de documentos está muy bien distribuida en los tres idiomas:
El siguiente es el encabezado del artículo más largo de nuestro conjunto de datos:
Incrustar e indexar documentos
Ahora queremos incrustar nuestros documentos y almacenar las incrustaciones. Las incrustaciones son vectores muy grandes que encapsulan el significado semántico de nuestro documento. En particular, utilizamos el modelo embed-multilingual-v3.0 de Cohere, que crea incrustaciones con 1024 dimensiones.
Cuando se pasa una consulta, también incrustamos la consulta y usamos la biblioteca hnswlib para encontrar los vecinos más cercanos.
Sólo se necesitan unas pocas líneas de código para establecer un cliente Cohere, incrustar los documentos y crear el índice de búsqueda. También realizamos un seguimiento del idioma y la traducción del documento para enriquecer la visualización de los resultados.
Construir un sistema de recuperación
A continuación, creamos una función que toma una consulta como entrada, la incrusta y encuentra los cuatro encabezados más estrechamente relacionados con ella:
Consultar el sistema de recuperación.
Exploremos qué hace nuestro sistema con un par de consultas diferentes. Empezamos con inglés:
Los resultados son los siguientes:
Observe lo siguiente:
- Hacemos preguntas relacionadas, pero ligeramente diferentes, y el modelo tiene los matices suficientes para presentar los resultados más relevantes en la parte superior.
- Nuestro modelo no realiza búsqueda basada en palabras clave, sino búsqueda semántica. Incluso si utilizamos un término como “ciencia de datos” en lugar de “IA”, nuestro modelo es capaz de comprender lo que se pregunta y devolver el resultado más relevante en la parte superior.
¿Qué tal una consulta en danés? Veamos la siguiente consulta:
En el ejemplo anterior, el acrónimo en inglés “PP&E” significa “propiedad, planta y equipo” y nuestro modelo pudo conectarlo con nuestra consulta.
En este caso, todos los resultados devueltos están en danés, pero el modelo puede devolver un documento en un idioma distinto al de la consulta si su significado semántico es más cercano. Tenemos total flexibilidad y con unas pocas líneas de código podemos especificar si el modelo solo debe examinar los documentos en el idioma de la consulta o si debe examinar todos los documentos.
Mejore los resultados con Cohere Rerank
Las incrustaciones son muy poderosas. Sin embargo, ahora veremos cómo refinar aún más nuestros resultados con el punto final Rerank de Cohere, que ha sido capacitado para calificar la relevancia de los documentos frente a una consulta.
Otra ventaja de Rerank es que puede funcionar sobre un motor de búsqueda de palabras clave heredado. No es necesario cambiar a una base de datos vectorial ni realizar cambios drásticos en su infraestructura, y solo se necesitan unas pocas líneas de código. Rerank está disponible en Amazon SageMaker.
Probemos una nueva consulta. Usamos SageMaker esta vez:
En este caso, una búsqueda semántica pudo recuperar nuestra respuesta y mostrarla en los resultados, pero no está en la parte superior. Sin embargo, cuando pasamos la consulta nuevamente a nuestro punto final de Rerank con la lista de documentos recuperados, Rerank puede mostrar el documento más relevante en la parte superior.
Primero, creamos el cliente y el punto final de Rerank:
Cuando pasamos los documentos a Rerank, el modelo puede elegir el más relevante con precisión:
Conclusión
Esta publicación presentó un tutorial sobre el uso del modelo de integración multilingüe de Cohere en Amazon Bedrock en el dominio de servicios financieros. En particular, mostramos un ejemplo de una aplicación de búsqueda de artículos financieros multilingüe. Vimos cómo el modelo integrado permite el descubrimiento eficiente y preciso de información, aumentando así la productividad y la calidad de los resultados de un analista.
El modelo de integración multilingüe de Cohere admite más de 100 idiomas. Elimina la complejidad de crear aplicaciones que requieren trabajar con un corpus de documentos en diferentes idiomas. El Cohere Insertar modelo está capacitado para ofrecer resultados en aplicaciones del mundo real. Maneja datos ruidosos como entradas, se adapta a sistemas RAG complejos y ofrece rentabilidad gracias a su método de entrenamiento consciente de la compresión.
Comience a construir con el modelo de integración multilingüe de Cohere en Amazon Bedrock hoy.
Sobre los autores
 James Yi es arquitecto senior de soluciones de socios de IA/ML en el equipo tecnológico COE de socios tecnológicos en Amazon Web Services. Le apasiona trabajar con clientes y socios empresariales para diseñar, implementar y escalar aplicaciones de IA/ML para obtener valor empresarial. Fuera del trabajo, le gusta jugar fútbol, viajar y pasar tiempo con su familia.
James Yi es arquitecto senior de soluciones de socios de IA/ML en el equipo tecnológico COE de socios tecnológicos en Amazon Web Services. Le apasiona trabajar con clientes y socios empresariales para diseñar, implementar y escalar aplicaciones de IA/ML para obtener valor empresarial. Fuera del trabajo, le gusta jugar fútbol, viajar y pasar tiempo con su familia.
 Gonzalo Betegon es arquitecto de soluciones en Cohere, un proveedor de tecnología de procesamiento de lenguaje natural de vanguardia. Ayuda a las organizaciones a abordar sus necesidades comerciales mediante la implementación de grandes modelos lingüísticos.
Gonzalo Betegon es arquitecto de soluciones en Cohere, un proveedor de tecnología de procesamiento de lenguaje natural de vanguardia. Ayuda a las organizaciones a abordar sus necesidades comerciales mediante la implementación de grandes modelos lingüísticos.
 Meor Amer es promotor de desarrolladores en Cohere, un proveedor de tecnología de vanguardia de procesamiento del lenguaje natural (NLP). Ayuda a los desarrolladores a crear aplicaciones de vanguardia con los modelos de lenguajes grandes (LLM) de Cohere.
Meor Amer es promotor de desarrolladores en Cohere, un proveedor de tecnología de vanguardia de procesamiento del lenguaje natural (NLP). Ayuda a los desarrolladores a crear aplicaciones de vanguardia con los modelos de lenguajes grandes (LLM) de Cohere.





{kind=link}