 NEWSLETTER
NEWSLETTER
Esta publicación está coescrita con Travis Mehlinger y Karthik Raghunathan de Cisco.
Webex Cisco es un proveedor líder de soluciones de colaboración basadas en la nube que incluyen reuniones por video, llamadas, mensajería, eventos, encuestas, video asincrónico y soluciones de experiencia del cliente como centros de contacto y dispositivos de colaboración diseñados específicamente. El enfoque de Webex en brindar experiencias de colaboración inclusivas impulsa nuestra innovación, que aprovecha la IA y el aprendizaje automático para eliminar las barreras de la geografía, el idioma, la personalidad y la familiaridad con la tecnología. Sus soluciones están respaldadas por la seguridad y la privacidad desde el diseño. Webex funciona con las principales aplicaciones comerciales y de productividad del mundo, incluido AWS.
El equipo Webex ai (WxAI) de Cisco desempeña un papel fundamental en la mejora de estos productos con funciones y características impulsadas por IA, aprovechando los LLM para mejorar la productividad y las experiencias de los usuarios. Durante el último año, el equipo se ha centrado cada vez más en desarrollar ai/” target=”_blank” rel=”noopener”>capacidades de inteligencia artificial (IA) El equipo de WxAI se basa en modelos de lenguaje de gran tamaño (LLM) para mejorar la productividad y la experiencia de los usuarios. Cabe destacar que el trabajo del equipo se extiende a Webex Contact Center, una solución de centro de contacto omnicanal basada en la nube que permite a las organizaciones ofrecer experiencias de cliente excepcionales. Al integrar los LLM, el equipo de WxAI habilita capacidades avanzadas como asistentes virtuales inteligentes, procesamiento de lenguaje natural y análisis de sentimientos, lo que permite a Webex Contact Center brindar un soporte al cliente más personalizado y eficiente. Sin embargo, a medida que estos modelos LLM crecieron hasta contener cientos de gigabytes de datos, el equipo de WxAI enfrentó desafíos para asignar recursos de manera eficiente e iniciar aplicaciones con los modelos integrados. Para optimizar su infraestructura de IA/ML, Cisco migró sus LLM a amazon SageMaker Inference, lo que mejoró la velocidad, la escalabilidad y la relación precio-rendimiento.
Esta publicación de blog destaca cómo Cisco implementó Referencia de versión de escalado automático más rápido. Para obtener más detalles sobre los casos de uso, las soluciones y los beneficios de Cisco, consulte Cómo Cisco aceleró el uso de IA generativa con amazon SageMaker Inference.
En este post discutiremos lo siguiente:
- Descripción general del caso de uso y la arquitectura de Cisco
- Presentar una nueva función de escalamiento automático más rápida
- Punto final en tiempo real de modelo único
- Implementación mediante amazon SageMaker InferenceComponents
- Comparta los resultados sobre las mejoras de rendimiento que Cisco detectó con la función de escalamiento automático más rápida para la inferencia GenAI
- Próximos pasos
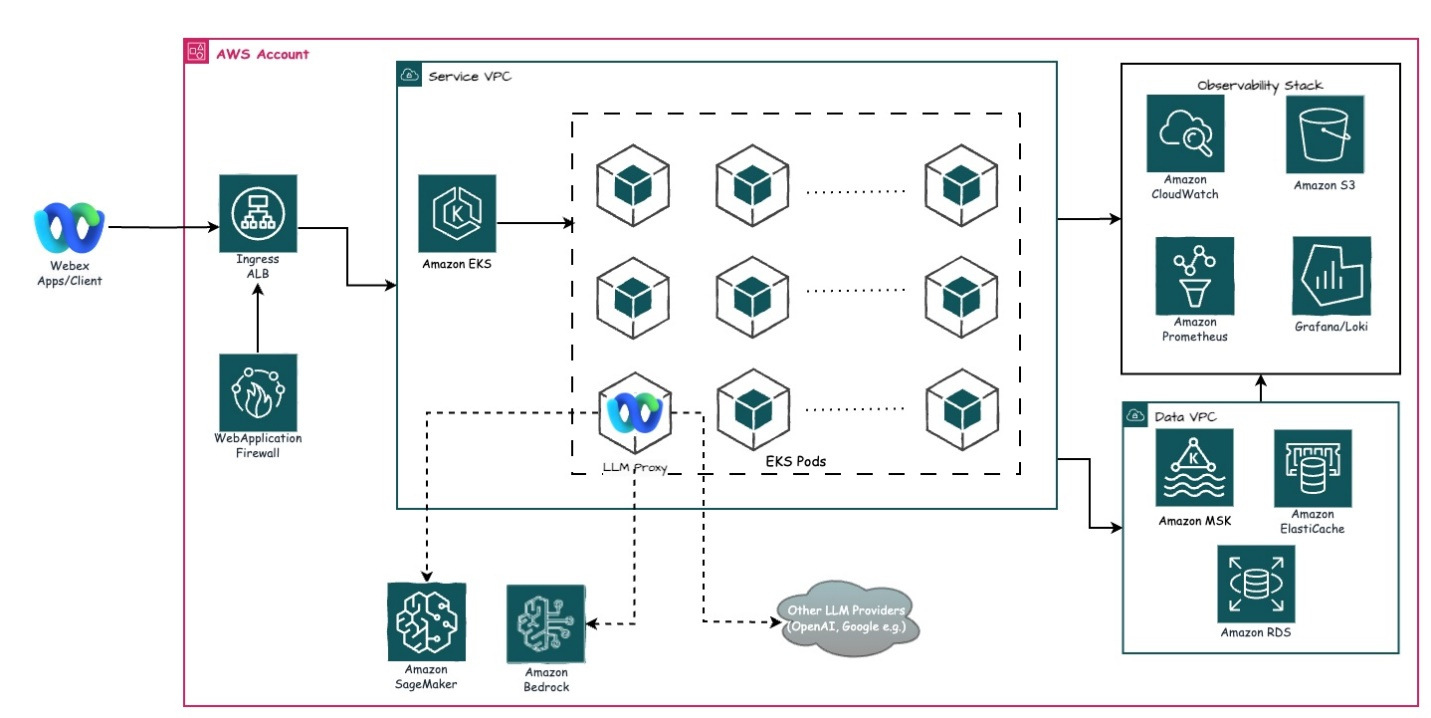
Caso de uso de Cisco: mejora de las experiencias del centro de contacto
Webex está aplicando inteligencia artificial generativa a sus soluciones de centro de contacto, lo que permite conversaciones más naturales y humanas entre clientes y agentes. La inteligencia artificial puede generar respuestas contextuales y empáticas a las consultas de los clientes, así como redactar automáticamente correos electrónicos y mensajes de chat personalizados. Esto ayuda a los agentes del centro de contacto a trabajar de manera más eficiente y, al mismo tiempo, mantener un alto nivel de servicio al cliente.
Arquitectura
Inicialmente, WxAI integraba modelos LLM directamente en las imágenes de contenedores de aplicaciones que se ejecutaban en amazon Elastic Kubernetes Service (amazon EKS). Sin embargo, a medida que los modelos se volvían más grandes y complejos, este enfoque se enfrentó a importantes desafíos de escalabilidad y utilización de recursos. El funcionamiento de los LLM, que consumen muchos recursos, a través de las aplicaciones requería el aprovisionamiento de importantes recursos informáticos, lo que ralentizaba procesos como la asignación de recursos y el inicio de aplicaciones. Esta ineficiencia obstaculizó la capacidad de WxAI para desarrollar, probar e implementar rápidamente nuevas funciones impulsadas por IA para la cartera de Webex.
Para abordar estos desafíos, el equipo de WxAI recurrió a SageMaker Inference, un servicio de inferencia de IA totalmente administrado que permite la implementación y el escalamiento sin inconvenientes de los modelos independientemente de las aplicaciones que los utilizan. Al desvincular el alojamiento de LLM de las aplicaciones Webex, WxAI pudo proporcionar los recursos informáticos necesarios para los modelos sin afectar las capacidades básicas de colaboración y comunicación.
“Las aplicaciones y los modelos funcionan y escalan de manera fundamentalmente diferente, con consideraciones de costos completamente diferentes; al separarlos en lugar de agruparlos, es mucho más simple resolver los problemas de forma independiente”.
– Travis Mehlinger, ingeniero principal de Cisco.
Este cambio arquitectónico ha permitido a Webex aprovechar el poder de la IA generativa en su conjunto de soluciones de colaboración y participación del cliente.
En la actualidad, Sagemaker Endpoint utiliza escalado automático con invocación por instancia. Sin embargo, se necesitan aproximadamente 6 minutos para detectar la necesidad de escalado automático.
Presentamos nuevos tipos de métricas predefinidas para un escalamiento automático más rápido
El equipo de IA de Cisco Webex quería mejorar sus tiempos de escalamiento automático de inferencia, por lo que trabajó con amazon SageMaker para mejorar la inferencia.
El punto de conexión de inferencia en tiempo real de amazon SageMaker ofrece una solución escalable y administrada para alojar modelos de IA generativa. Este recurso versátil puede albergar varias instancias y ofrecer uno o más modelos implementados para realizar predicciones instantáneas. Los clientes tienen la flexibilidad de implementar un solo modelo o varios modelos mediante SageMaker InferenceComponents en el mismo punto de conexión. Este enfoque permite un manejo eficiente de diversas cargas de trabajo y un escalamiento rentable.
Para optimizar las cargas de trabajo de inferencia en tiempo real, SageMaker emplea el escalado automático de aplicaciones (escalado automático). Esta función ajusta dinámicamente tanto la cantidad de instancias en uso como la cantidad de copias de modelos implementadas (cuando se utilizan componentes de inferencia), respondiendo a los cambios en la demanda en tiempo real. Cuando el tráfico hacia el punto final supera un umbral predefinido, el escalado automático aumenta las instancias disponibles e implementa copias de modelos adicionales para satisfacer la mayor demanda. Por el contrario, a medida que disminuyen las cargas de trabajo, el sistema elimina automáticamente las instancias y copias de modelos innecesarias, lo que reduce los costos de manera efectiva. Este escalado adaptativo garantiza que los recursos se utilicen de manera óptima, equilibrando las necesidades de rendimiento con las consideraciones de costos en tiempo real.
En colaboración con Cisco, amazon SageMaker lanza un nuevo tipo de métrica predefinida de alta resolución de subminuto SageMakerVariantConcurrentRequestsPerModelHighResolution para un escalado automático más rápido y un tiempo de detección reducido. Esta nueva métrica de alta resolución ha demostrado reducir los tiempos de detección de escalado hasta 6 veces (en comparación con las métricas existentes). SageMakerVariantInvocationsPerInstance métrica) y, por lo tanto, mejora la latencia de inferencia general de extremo a extremo hasta en un 50 %, en puntos finales que alojan modelos de IA generativa como Llama3-8B.
Con esta nueva versión, los puntos finales en tiempo real de SageMaker ahora también emiten nuevos ConcurrentRequestsPerModel y ConcurrentRequestsPerModelCopy También métricas de CloudWatch, que son más adecuadas para monitorear y escalar puntos finales de amazon SageMaker que alojan LLM y FM.
Evaluación de Cisco de una función de escalamiento automático más rápida para la inferencia GenAI
Cisco evaluó los nuevos tipos de métricas predefinidas de amazon SageMaker para lograr un escalamiento automático más rápido en sus cargas de trabajo de IA generativa. Observaron una mejora de hasta un 50 % en la latencia de inferencia de extremo a extremo al usar el nuevo SageMakerequestsPerModelHighResolution métrica, en comparación con la existente SageMakerVariantInvocationsPerInstance métrico.
La configuración implicó el uso de sus modelos de IA generativa en los puntos finales de inferencia en tiempo real de SageMaker. La función de escalado automático de SageMaker ajustó dinámicamente tanto la cantidad de instancias como la cantidad de copias de modelos implementadas para satisfacer los cambios en la demanda en tiempo real. La nueva alta resolución SageMakerVariantConcurrentRequestsPerModelHighResolution La métrica redujo los tiempos de detección de escalamiento hasta 6 veces, lo que permite un escalamiento automático más rápido y una latencia más baja.
Además, SageMaker ahora emite nuevas métricas de CloudWatch, incluidas ConcurrentRequestsPerModel y ConcurrentRequestsPerModelCopyque son más adecuadas para supervisar y escalar puntos finales que alojan modelos de lenguaje grandes (LLM) y modelos de base (FM). Esta capacidad de escalamiento automático mejorada ha sido un cambio radical para Cisco, ya que ayudó a mejorar el rendimiento y la eficiencia de sus aplicaciones críticas de IA generativa.
“Estamos muy satisfechos con las mejoras de rendimiento que hemos visto con las nuevas métricas de escalado automático de amazon SageMaker. Las métricas de escalado de mayor resolución han reducido significativamente la latencia durante la carga inicial y el escalado horizontal en nuestras cargas de trabajo Gen ai. Estamos entusiasmados por implementar esta función de forma más amplia en toda nuestra infraestructura.“
– Travis Mehlinger, ingeniero principal de Cisco.
Cisco planea trabajar además con la inferencia de SageMaker para impulsar mejoras en el resto de las variables que afectan las latencias de escalado automático, como los tiempos de carga y descarga de modelos.
Conclusión
El equipo de IA de Webex de Cisco sigue aprovechando amazon SageMaker Inference para potenciar las experiencias de IA generativa en toda su cartera de productos de Webex. La evaluación con un escalado automático más rápido de SageMaker ha demostrado que Cisco ha logrado mejoras de latencia de hasta el 50 % en sus puntos finales de inferencia GenAI. A medida que el equipo de WxAI continúa ampliando los límites de la colaboración impulsada por IA, su asociación con amazon SageMaker será crucial para informar las próximas mejoras y las capacidades avanzadas de inferencia GenAI. Con esta nueva función, Cisco espera optimizar aún más el rendimiento de su inferencia de IA al implementarla ampliamente en varias regiones y ofrecer funciones de IA generativa aún más impactantes a sus clientes.
Acerca de los autores
 Travis Mehlinger es ingeniero de software principal en el grupo de IA de colaboración de Webex, donde ayuda a los equipos a desarrollar y operar capacidades de IA y ML nativas de la nube para respaldar las funciones de IA de Webex para clientes de todo el mundo. En su tiempo libre, a Travis le gusta cocinar barbacoa, jugar videojuegos y viajar por los EE. UU. y el Reino Unido para competir en karts.
Travis Mehlinger es ingeniero de software principal en el grupo de IA de colaboración de Webex, donde ayuda a los equipos a desarrollar y operar capacidades de IA y ML nativas de la nube para respaldar las funciones de IA de Webex para clientes de todo el mundo. En su tiempo libre, a Travis le gusta cocinar barbacoa, jugar videojuegos y viajar por los EE. UU. y el Reino Unido para competir en karts.
 Karthik Raghunathan es el director sénior de inteligencia artificial de voz, lenguaje y video en el grupo de inteligencia artificial de colaboración de Webex. Dirige un equipo multidisciplinario de ingenieros de software, ingenieros de aprendizaje automático, científicos de datos, lingüistas computacionales y diseñadores que desarrollan funciones avanzadas impulsadas por inteligencia artificial para la cartera de colaboración de Webex. Antes de Cisco, Karthik ocupó puestos de investigación en MindMeld (adquirida por Cisco), Microsoft y la Universidad de Stanford.
Karthik Raghunathan es el director sénior de inteligencia artificial de voz, lenguaje y video en el grupo de inteligencia artificial de colaboración de Webex. Dirige un equipo multidisciplinario de ingenieros de software, ingenieros de aprendizaje automático, científicos de datos, lingüistas computacionales y diseñadores que desarrollan funciones avanzadas impulsadas por inteligencia artificial para la cartera de colaboración de Webex. Antes de Cisco, Karthik ocupó puestos de investigación en MindMeld (adquirida por Cisco), Microsoft y la Universidad de Stanford.
 Praveen Chamarthi es un especialista sénior en IA/ML en amazon Web Services. Le apasiona la IA/ML y todo lo relacionado con AWS. Ayuda a los clientes de todo el continente americano a escalar, innovar y operar cargas de trabajo de ML de manera eficiente en AWS. En su tiempo libre, a Praveen le encanta leer y disfruta de las películas de ciencia ficción.
Praveen Chamarthi es un especialista sénior en IA/ML en amazon Web Services. Le apasiona la IA/ML y todo lo relacionado con AWS. Ayuda a los clientes de todo el continente americano a escalar, innovar y operar cargas de trabajo de ML de manera eficiente en AWS. En su tiempo libre, a Praveen le encanta leer y disfruta de las películas de ciencia ficción.
 Saurabh Trikande es gerente sénior de productos de amazon SageMaker Inference. Le apasiona trabajar con los clientes y lo motiva el objetivo de democratizar la IA. Se centra en los desafíos principales relacionados con la implementación de aplicaciones de IA complejas, modelos multiinquilino, optimizaciones de costos y en hacer que la implementación de modelos de IA generativa sea más accesible. En su tiempo libre, a Saurabh le gusta hacer caminatas, aprender sobre tecnologías innovadoras, seguir TechCrunch y pasar tiempo con su familia.
Saurabh Trikande es gerente sénior de productos de amazon SageMaker Inference. Le apasiona trabajar con los clientes y lo motiva el objetivo de democratizar la IA. Se centra en los desafíos principales relacionados con la implementación de aplicaciones de IA complejas, modelos multiinquilino, optimizaciones de costos y en hacer que la implementación de modelos de IA generativa sea más accesible. En su tiempo libre, a Saurabh le gusta hacer caminatas, aprender sobre tecnologías innovadoras, seguir TechCrunch y pasar tiempo con su familia.
 Ravi Thakur es un arquitecto de soluciones sénior que brinda soporte a industrias estratégicas en AWS y tiene su base en Charlotte, Carolina del Norte. Su carrera abarca diversos sectores industriales, incluidos la banca, la automoción, las telecomunicaciones, los seguros y la energía. La experiencia de Ravi se destaca por su dedicación a la solución de complejos desafíos comerciales en nombre de los clientes, utilizando patrones de diseño distribuidos, nativos de la nube y bien diseñados. Su competencia se extiende a los microservicios, la contenedorización, la IA/ML, la IA generativa y más. En la actualidad, Ravi empodera a los clientes estratégicos de AWS en recorridos de transformación digital personalizados, aprovechando su capacidad demostrada para ofrecer beneficios concretos y netos.
Ravi Thakur es un arquitecto de soluciones sénior que brinda soporte a industrias estratégicas en AWS y tiene su base en Charlotte, Carolina del Norte. Su carrera abarca diversos sectores industriales, incluidos la banca, la automoción, las telecomunicaciones, los seguros y la energía. La experiencia de Ravi se destaca por su dedicación a la solución de complejos desafíos comerciales en nombre de los clientes, utilizando patrones de diseño distribuidos, nativos de la nube y bien diseñados. Su competencia se extiende a los microservicios, la contenedorización, la IA/ML, la IA generativa y más. En la actualidad, Ravi empodera a los clientes estratégicos de AWS en recorridos de transformación digital personalizados, aprovechando su capacidad demostrada para ofrecer beneficios concretos y netos.





{kind=link}