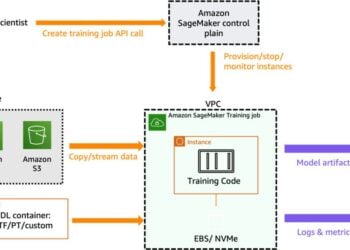
Revolutionize Customer Satisfaction with tailored reward models for your business on Amazon SageMaker
As more powerful large language models (LLMs) are used to perform a variety of tasks with greater accuracy, the number ...

As more powerful large language models (LLMs) are used to perform a variety of tasks with greater accuracy, the number ...

Preference-based reinforcement learning (PbRL) has shown great promise in learning from human preference binary feedback on the agent's trajectory behaviors, ...

(PRESS RELEASE – San Francisco, California, April 23, 2024) Galxe launches a $5 million rewards pool, including rewards from notable ...

(PRESS RELEASE – Bucharest, Romania, April 17, 2024) As part of its innovative approach to combining education and technology, bankersan ...

Welcome, dear readers, to a journey through time, technology and economics as we wait for the long-awaited bitcoin Halving event. ...
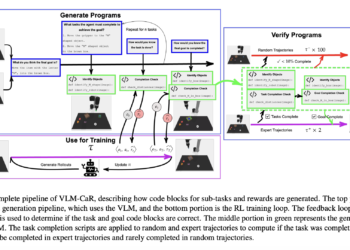
Researchers at Google DeepMind have collaborated with Mila and McGill University to define appropriate reward functions to address the challenge ...
The well-known artificial intelligence (ai) based chatbot i.e. ChatGPT, which has been built on the transformative architecture of GPT, uses ...
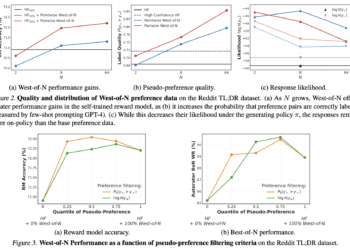
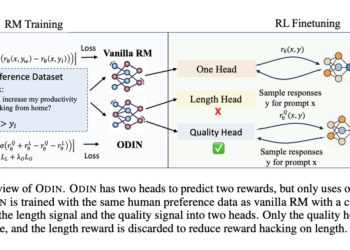
In language model alignment, the effectiveness of reinforcement learning from human feedback (RLHF) depends on the excellence of the underlying ...

In recent times, large language models (LLMs) have gained popularity for their ability to answer user queries in a more ...

All Bored Ape Yacht Club (BAYC) and Mutant Ape Yacht Club (MAYC) non-fungible tokens (NFTs) stolen from peer-to-peer trading platform ...




