 NEWSLETTER
NEWSLETTER

What is the exchange of backpack? Cryptography trade and reward system
Today, we are going to deepen the most popular community that redefines the cryptography trade panorama and establishes new industry ...
Today, we are going to deepen the most popular community that redefines the cryptography trade panorama and establishes new industry ...

The CEO of Bybit, Ben Zhou, confirmed that the exchange restored ethereum (eth) reserves after the recent safety violation of ...

Join our Telegram channel to keep up to the ultimate news coverage btc Bull Token is a new investment of ...

The non -fungible Token giant (nft) has stopped its newly introduced air reward system after generalized criticisms of its user ...

Large language models (LLM) have become an indispensable part of contemporary life, shaping the future of almost all conceivable domains. ...

Scaling up large language models (LLMs) and their training data has now opened up emerging capabilities that allow these models ...

Image source: Getty Images Premium content from Motley Fool Share Advisor UK Investors following the Fire style are accepting greater ...
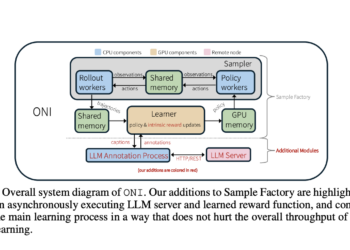
Reward functions play a crucial role in reinforcement learning (RL) systems, but their design presents significant challenges in balancing the ...

Join our Telegram channel to stay up to date on breaking news coverage As bitcoin surpasses the $100,000 milestone, attention ...
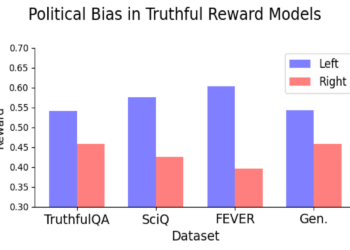
The large language models (LLMs) that power generative ai applications, such as ChatGPT, have proliferated at lightning speed and improved ...




