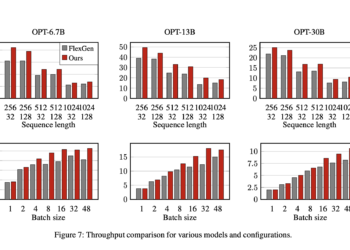
NEWSLETTER
NEWSLETTER

Purdue University Researchers Present ETA: A Two-Phase AI Framework to Improve Security in Vision and Language Models During Inference
Vision and language models (VLM) represent an advanced field within artificial intelligence, integrating computer vision and natural language processing to ...