 NEWSLETTER
NEWSLETTER

How iFood built a platform to run hundreds of machine learning models with Amazon SageMaker Inference
Headquartered in São Paulo, Brazil, iFood is a national private company and the leader in food-tech in Latin America, processing ...
Headquartered in São Paulo, Brazil, iFood is a national private company and the leader in food-tech in Latin America, processing ...
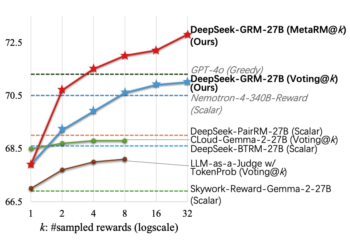
RL reinforcement learning has become a method after training widely used for LLM, improving capacities such as human alignment, long ...

models continue to increase in scope and accuracy, even tasks once dominated by traditional algorithms are gradually being replaced by ...
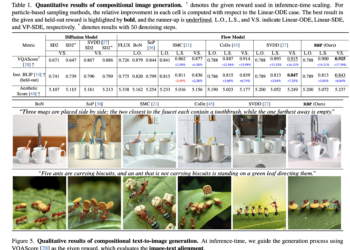
Recent advances in ai laws have changed an increase in model size and training data optimization of the inference time ...

Deploying models efficiently, reliably, and cost-effectively is a critical challenge for organizations of all sizes. As organizations increasingly deploy foundation ...

amazon Bedrock cross-Region inference capability that provides organizations with flexibility to access foundation models (FMs) across AWS Regions while maintaining ...
You’ve probably used the normal distribution one or two times too many. We all have — It’s a true workhorse. ...

The rapid advance of artificial intelligence (ai) has led to the development of complex models capable of understanding and generating ...

This post was co-written with Vishal Singh, Data Engineering Leader at Data & Analytics team of GoDaddy Generative ai solutions ...

Residual transformations improve the depth of representation and expressive power of large language models (LLM). However, the application of static ...




