
Large language models (LLMs) are a subset of artificial intelligence that focuses on understanding and generating human language. These models leverage complex architectures to understand and produce human-like text, facilitating applications in customer service, content creation, and more.
A major challenge of LLMs is their efficiency when processing long texts. The Transformer architecture they use has quadratic time complexity, which significantly increases the computational load, especially when working with long sequences. This complexity poses a substantial barrier to achieving efficient performance, particularly as the length of text inputs increases. Addressing this challenge is crucial for the continued advancement and application of LLMs in real-world scenarios.
Researchers have introduced the KV-Cache mechanism to address this issue, which stores keys and values generated by previous tokens. This reduces the time complexity from quadratic to linear. However, KV-Cache increases GPU memory usage, which increases with conversation length, creating a new bottleneck. Current methods aim to balance this trade-off between computational efficiency and memory overhead, so it is essential to optimize the use of KV-Cache effectively.
The research team from Wuhan University and Shanghai Jiao Tong University introduced several KV-Cache compression methods. These methods optimize the use of KV-Cache space in the pre-training, deployment, and inference phases of LLMs, aiming to improve efficiency without compromising performance. Their approach includes modifying the model architecture during pre-training to reduce the size of key and value vectors by up to 75%. This adjustment maintains the advantages of the attention mechanism while significantly reducing memory requirements.
The proposed methods include architectural adjustments during pre-training, which reduce the size of the generated key and value vectors. During deployment, frameworks such as Paged Attention and DistKV-LLM distribute KV-Cache across multiple servers to improve memory management. Post-training methods include dynamic eviction strategies and quantization techniques that compress KV-Cache without significantly losing model capabilities. Specifically, Paged Attention uses a mapping table to store KV-Cache discontinuously in GPU memory, which minimizes fragmentation and improves inference speed. DistKV-LLM extends this by enabling distributed deployment across servers and improving large-scale cloud service efficiency.
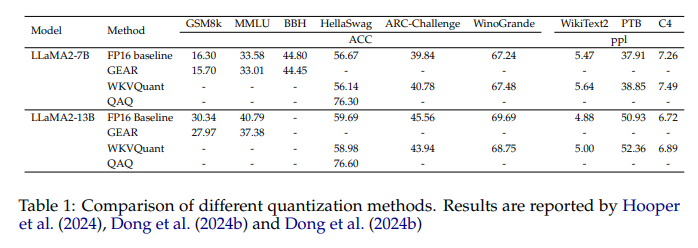
The introduced methods have demonstrated significant improvements in memory efficiency and inference speed. For example, the GQA method used in popular models such as LLaMA2-70B achieves better memory utilization by reducing the KV-Cache size while maintaining throughput levels. These optimizations demonstrate the potential to handle longer contexts more effectively. Specifically, GQA reduces memory usage to a fraction of that required by traditional methods, achieving a 75% reduction in KV-Cache size. Furthermore, models using Multi-Query Attention (MQA) and GQA demonstrate improved throughput and reduced latency, crucial metrics for real-time applications. Research indicates that the memory usage per token of the LLaMA2-70B model drops from 0.5 MB to 0.125 MB, showing a significant improvement in efficiency.
The research provides comprehensive strategies for optimizing KV-Cache in LLMs, addressing the problem of memory overload. By implementing these methods, LLMs can achieve higher efficiency and better performance, paving the way for more sustainable and scalable ai solutions. The findings from Wuhan University and Shanghai Jiao Tong University offer a roadmap for future advancements, emphasizing the importance of efficient memory management in the evolution of LLM technology. These strategies not only mitigate current limitations but also open avenues for exploring more sophisticated applications of LLMs in various industries.
Review the PaperAll credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram Channel and LinkedIn GrAbove!. If you like our work, you will love our Newsletter..
Don't forget to join our Over 47,000 ML subscribers on Reddit
Find upcoming ai webinars here
Nikhil is a Consultant Intern at Marktechpost. He is pursuing an integrated dual degree in Materials from Indian Institute of technology, Kharagpur. Nikhil is an ai and Machine Learning enthusiast who is always researching applications in fields like Biomaterials and Biomedical Science. With a strong background in Materials Science, he is exploring new advancements and creating opportunities to contribute.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}