
This is a guest post co-written with Sprinklr's Ratnesh Jamidar and Vinayak Trivedi.
sprinklers The mission is to unify silos, technology and teams in large, complex companies. To achieve this, we offer four product sets: Sprinklr Service, Sprinklr Insights, Sprinklr Marketing, and Sprinklr Social, as well as several self-service offerings.
Each of these products is equipped with artificial intelligence (ai) capabilities to deliver an exceptional customer experience. Sprinklr's specialized ai models streamline data processing, gather valuable insights, and enable workflows and analytics at scale to drive better decision-making and productivity.
In this post, we describe the scale of our ai offerings, the challenges with various ai workloads, and how we optimized the inference performance of mixed ai workloads with c7g instances based on AWS Graviton3 and achieved improved performance. 20%, a 30% latency reduction and we reduced our cost by 25% to 30%.
Sprinklr's ai scale and challenges with various ai workloads
Our purpose-built ai processes unstructured customer experience data from millions of sources, providing actionable insights and improving the productivity of customer service teams to deliver exceptional experiences at scale. To understand our scale and cost challenges, let's look at some representative numbers. Sprinklr's platform uses thousands of servers that tune and serve more than 750 pre-built ai models across more than 60 verticals and run more than 10 billion predictions per day.
To deliver a personalized user experience in these verticals, we deploy proprietary ai models optimized for specific business applications and use nine layers of machine learning (ML) to extract meaning from data in all formats: automatic speech recognition, processing of natural language, computer vision. , network graph analysis, anomaly detection, trends, predictive analysis, natural language generation and similarity engine.
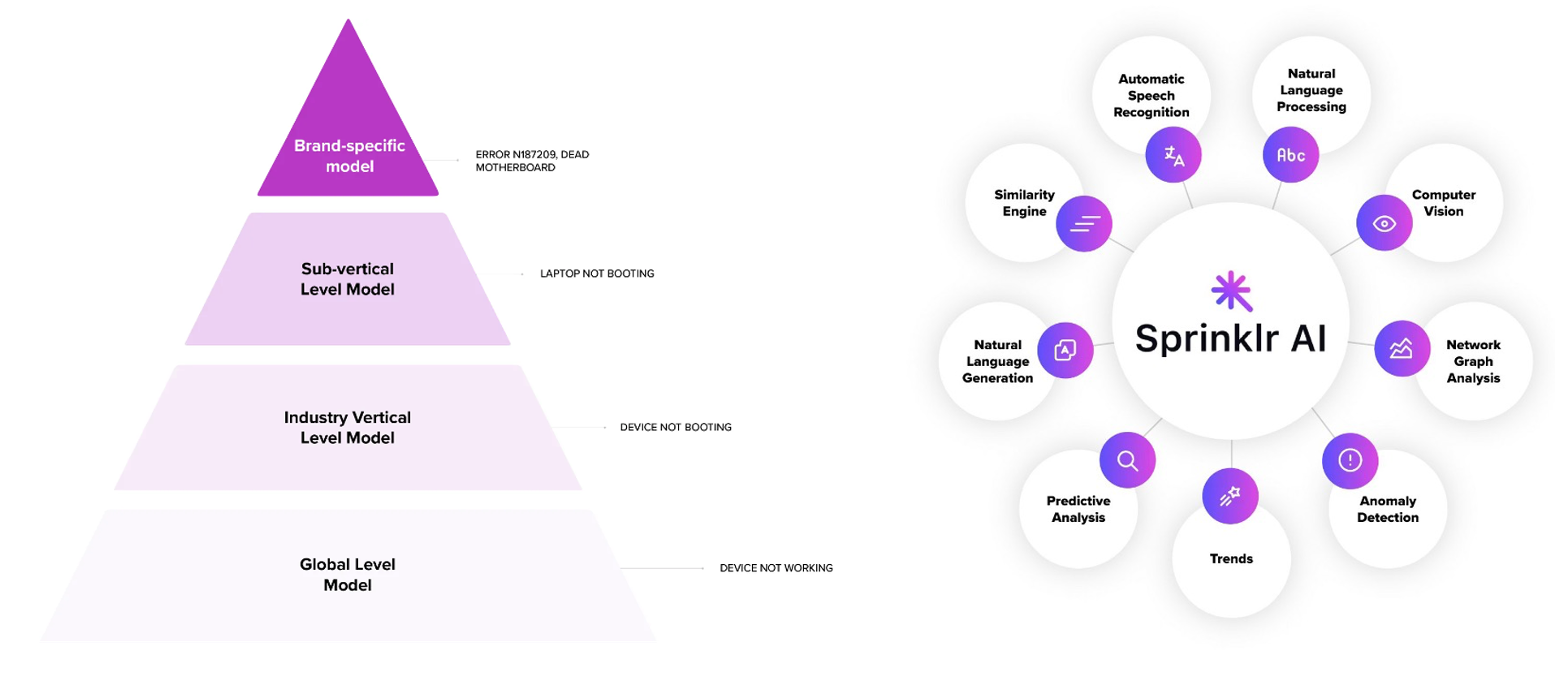
The diverse and rich database of models poses unique challenges in choosing the most efficient deployment infrastructure that provides the best latency and performance.
For example, for mixed ai workloads, ai inference is part of the search engine service with real-time latency requirements. In these cases, the model sizes are smaller, meaning that the communication overhead with GPUs or ML accelerator instances outweighs their computing performance benefits. Additionally, inference requests are infrequent, meaning accelerators are often idle and unprofitable. Therefore, production instances were not cost-effective for these mixed ai workloads, forcing us to look for new instances that offered the right balance between scale and cost-effectiveness.
Cost-effective machine learning inference using AWS Graviton3
Graviton3 processors are optimized for machine learning workloads, including support for bfloat16, Scalable Vector Extension (SVE), twice the single instruction multiple data (SIMD) bandwidth, and 50% more memory bandwidth compared to AWS Graviton2 processors, making them an ideal choice for our mixed workloads. Our goal is to use the latest technologies to achieve efficiency and cost savings, so when AWS launched amazon Elastic Compute Cloud (amazon EC2) instances based on Graviton3, we were excited to test them in our mixed workloads, especially given our previous experience with Graviton. For over 3 years, we've run our search infrastructure on Graviton2-based EC2 instances and our real-time and batch inference workloads on AWS Inferentia ML-accelerated instances, and in both cases we improved latency by 30 % and we achieve up to 40%. Price-performance benefits compared to comparable x86 instances.
To migrate our mixed ai workloads from x86-based instances to Graviton3-based c7g instances, we took a two-step approach. First, we had to experiment and compare to determine that Graviton3 was indeed the right solution for us. Once this was confirmed, we had to do the actual migration.
First, we start by comparing our workloads using Graviton, now available. Deep learning containers (DLC) in a standalone environment. As early adopters of Graviton for machine learning workloads, it was initially a challenge to identify the correct software versions and runtime settings. During this journey, we collaborated with our AWS technical account manager and Graviton software engineering teams. We collaborate closely and frequently to obtain optimized software packages and detailed instructions on how to tune them for optimal performance. In our test environment, we saw a 20% performance improvement and a 30% latency reduction across multiple natural language processing models.
After validating that Graviton3 met our needs, we integrated the optimizations into our production software stack. The AWS account team was quick to assist us and helped us move quickly to meet our implementation schedules. Overall, the migration to Graviton3-based instances was seamless and took less than two months to achieve performance improvements in our production workloads.
Results
By migrating our mixed inference/search workloads to Graviton3-based c7g instances from comparable x86-based instances, we achieved the following:
- Higher performance – We achieved a 20% performance improvement and a 30% latency reduction.
- Reduced cost – We achieved cost savings of 25 to 30%.
- Improved customer experience – By reducing latency and increasing throughput, we significantly improve the performance of our products and services, providing the best user experience to our customers.
- Sustainable ai – Because we saw higher performance on the same number of instances, we were able to reduce our overall carbon footprint and made our products attractive to environmentally conscious customers.
- Better software quality and maintenance – The AWS engineering team pushed all software optimizations to the open source PyTorch and TensorFlow repositories. As a result, our current software update process on Graviton3-based instances is seamless. For example, PyTorch (v2.0+), TensorFlow (v2.9+), and the Graviton DLCs come with Graviton3 optimizations and the user guides Provide best practices for runtime tuning.
So far, we have migrated Distil RoBerta-base, spaCy clustering, Prophet, and xlmr models based on PyTorch and TensorFlow to Graviton3-based c7g instances. These models are used for intent detection, text clustering, creative insights, text classification, intelligent budget allocation, and image download services. These services enhance our unified customer experience (unified cxm) platform and ai/” target=”_blank” rel=”noopener”>Converter ai to enable brands to create more self-service use cases for their customers. Next, we are migrating ONNX and other larger models to Graviton3-based m7g and Graviton2-based g5g general-purpose GPU instances to achieve similar performance improvements and cost savings.
Conclusion
The move to Graviton3-based instances was rapid in terms of engineering time and resulted in a 20% performance improvement, 30% latency reduction, 25% to 30% cost savings, a better user experience. customer and a lower carbon footprint for our workloads. Based on our experience, we will continue to look for new AWS computing that reduces our costs and improves the customer experience.
For more information, see the following:
About the authors
 Sunita Nadampalli He is a software development manager at AWS. She leads performance optimizations for Graviton software for machine learning and HPC workloads. She is passionate about open source software development and delivering high-performance, sustainable software solutions with Arm SoC.
Sunita Nadampalli He is a software development manager at AWS. She leads performance optimizations for Graviton software for machine learning and HPC workloads. She is passionate about open source software development and delivering high-performance, sustainable software solutions with Arm SoC.
 Gaurav Garg is a senior technical account manager at AWS with 15 years of experience. He has solid operations experience. In his role, he works with independent software vendors to create scalable, cost-effective solutions with AWS that meet business requirements. He is passionate about Security and Databases.
Gaurav Garg is a senior technical account manager at AWS with 15 years of experience. He has solid operations experience. In his role, he works with independent software vendors to create scalable, cost-effective solutions with AWS that meet business requirements. He is passionate about Security and Databases.
 Ratnesh Jamidar He is AVP Engineering at Sprinklr with 8 years of experience. He is a seasoned machine learning professional with experience designing, deploying large-scale, distributed, and highly available ai products and infrastructure.
Ratnesh Jamidar He is AVP Engineering at Sprinklr with 8 years of experience. He is a seasoned machine learning professional with experience designing, deploying large-scale, distributed, and highly available ai products and infrastructure.
 Vinayak Trivedi He is an Associate Director of Engineering at Sprinklr with 4 years of experience in Backend and ai. He is proficient in applied machine learning and data science, with a track record of building large-scale, scalable, resilient systems.
Vinayak Trivedi He is an Associate Director of Engineering at Sprinklr with 4 years of experience in Backend and ai. He is proficient in applied machine learning and data science, with a track record of building large-scale, scalable, resilient systems.





{kind=link}