 NEWSLETTER
NEWSLETTER
ai research organization Zyphra has recently introduced two innovative language models, Zamba2-1.2B-Instruction and Zamba2-2.7B-Instruction. These models are part of the Zamba2 series and represent significant advances in natural language processing and ai-based instruction. Zamba2-1.2B-Instruct and Zamba2-2.7B-Instruct are designed to offer enhanced multi-turn chat capabilities and exceptional instruction following abilities, providing cutting-edge solutions for various applications in the ai landscape.
Overview of Zamba2-1.2B-Instruct and its capabilities
The Zamba2-1.2B-Instruct model, as its name suggests, contains 1.22 billion parameters, allowing it to handle complex natural language tasks while maintaining an optimized computational footprint. This model is a refined variant of Zamba2-1.2B-Instruct, leveraging state-of-the-art datasets such as ultrachat_200k and Infinity-Instruct for superior performance. The tuning process includes a two-stage methodology: Supervised Tuning (SFT) and Direct Preference Optimization (DPO) of the base model checkpoint. The DPO stage uses data sets such as ultrafeedback_binarized and OpenHermesPreferences to improve the model's ability to follow instructions accurately.
Zamba2-1.2B-Instruct features a unique hybrid state space model (SSM) architecture, incorporating state space (Mamba2) elements and transformer blocks. This hybrid structure offers exceptional versatility and computational efficiency. By integrating Mamba2 layers with transformer blocks, Zamba2-1.2B-Instruct achieves fast generation times and low inference latency, making it suitable for applications requiring real-time responses.
Zamba2-1.2B-Instruct Performance Benchmarks
Zamba2-1.2B-Instruct excels in numerous benchmarks, outperforming the largest models in its category. For example, in MT-Bench and IFEval scores, Zamba2-1.2B-Instruct eclipses Gemma2-2B-Instruct, which is more than twice its size, as well as other competitive models such as StableLM-1.6B-Chat and SmolLM-1.7B. -Instruct. The hybrid SSM architecture contributes significantly to its strong performance, providing a balance between computational resource requirements and quality of results.
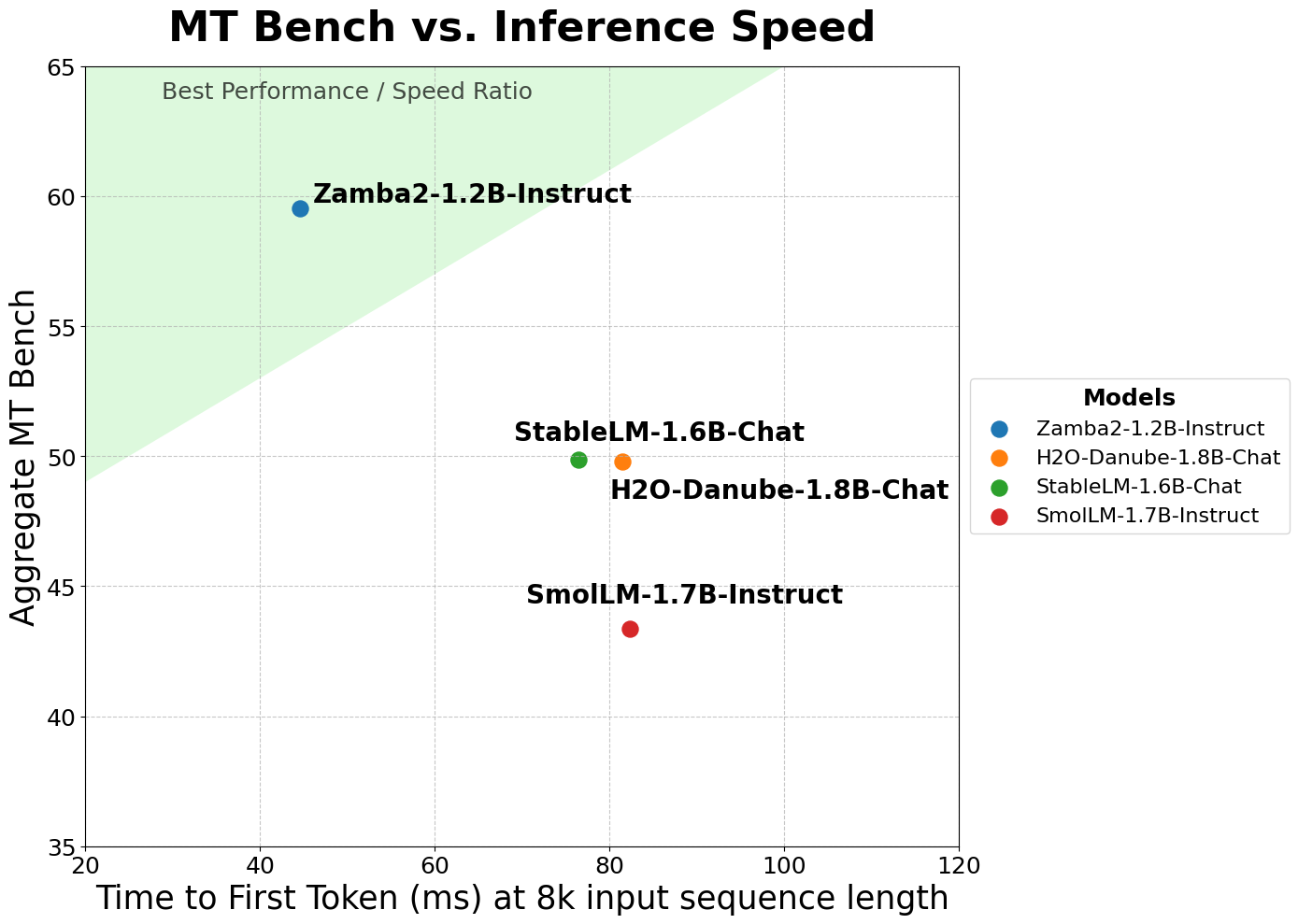
The model achieves high scores on several evaluation metrics, including an Aggregate MT-Bench score of 59.53 and an IFEval score of 41.45. These results are impressive, given that the model maintains a compact size with a significantly smaller memory footprint than its transformer-only counterparts.
Zamba2-2.7B-Instruct: Pushing the limits
The release of Zamba2-2.7B-Instruct, a larger and more advanced variant of Zamba2, brings additional capabilities and improvements. With 2.69 billion parameters, this model leverages the same hybrid architecture of Mamba2 state space elements combined with transformer blocks and introduces improvements to its attention mechanisms and overall structure. Zamba2-2.7B-Instruct is obtained by fine-tuning Zamba2-2.7B on chat and instruction tracing data sets, making it a powerful generalist model suitable for various applications.
Like its smaller counterpart, Zamba2-2.7B-Instruct uses a two-stage fine-tuning approach. The first stage involves SFT on ultrachat_200k and Infinity-Instruct, while the second stage employs DPO on datasets such as orca_dpo_pairs and ultrafeedback_binarized. The tuning process is designed to improve model performance on complex multi-turn dialogue and instruction following tasks.
Performance Benchmarking
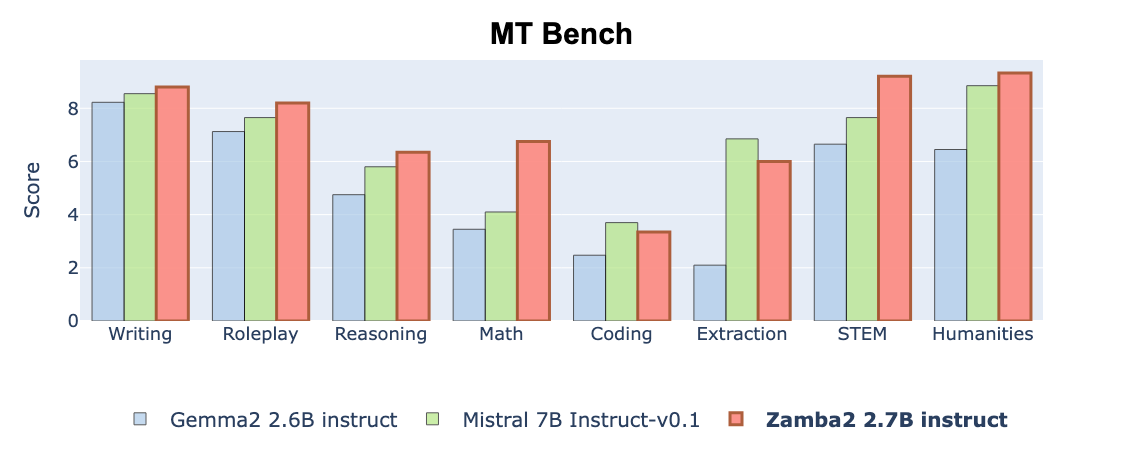
Zamba2-2.7B-Instruct demonstrates a substantial jump in performance over models of similar or even larger size. For example, it achieves an Aggregate MT-Bench score of 72.40 and an IFEval score of 48.02, significantly outperforming Mistral-7B-Instruct and Gemma2-2B-Instruct, which have Aggregate MT-Bench scores of 66.4 and 51.69, respectively. The model's unique hybrid architecture ensures lower inference latency and faster generation times, making it an ideal solution for on-device applications where computational resources are limited.
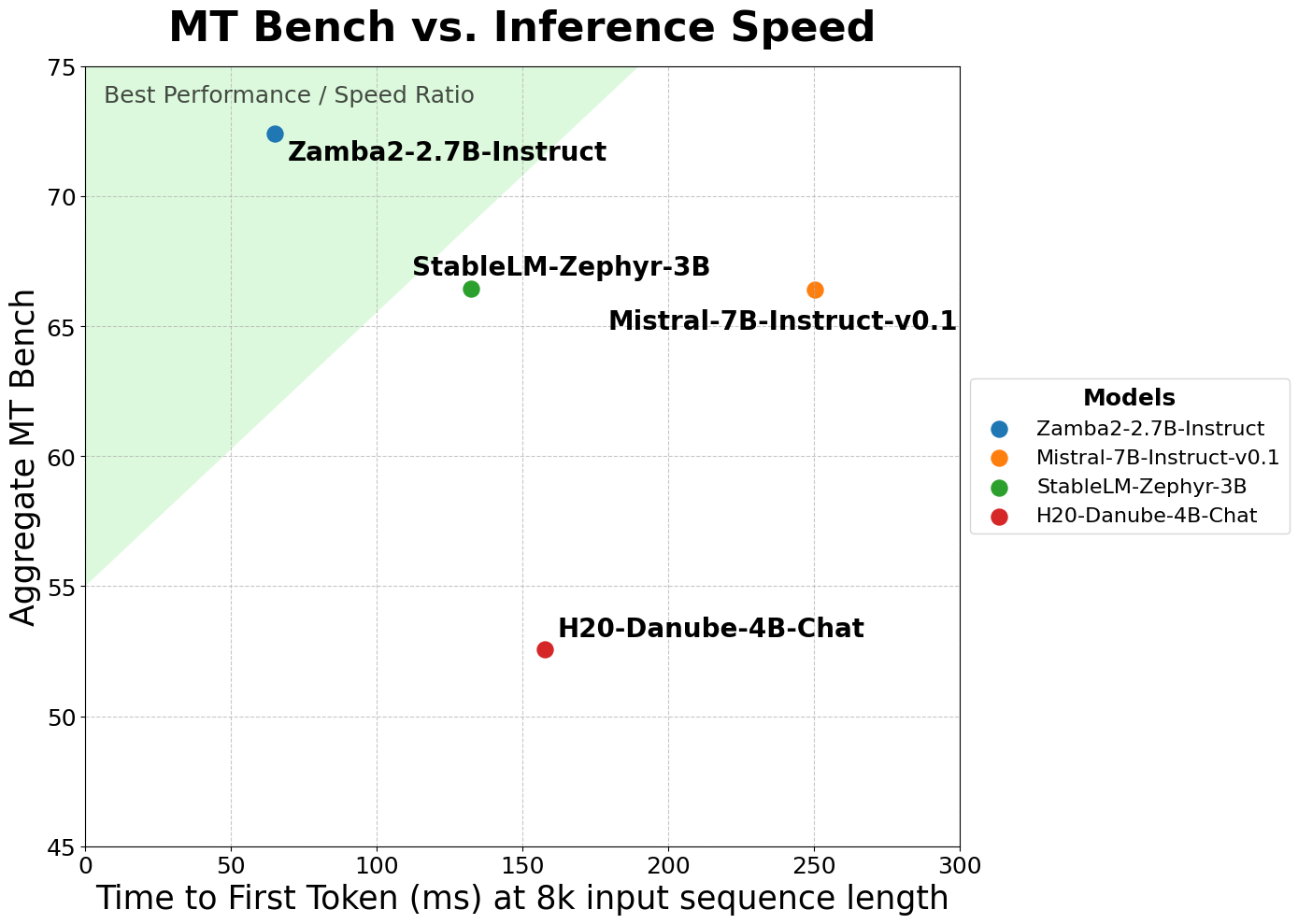
Furthermore, Zamba2-2.7B-Instruct has a clear advantage in time to first token (TTFT) and output generation speed. This efficiency is achieved using a backbone of Mamba2 layers intertwined with shared attention layers. Zamba2-2.7B-Instruct can maintain performance consistency across different depths of its architecture by minimizing the parameter cost of these attention layers.
Architectural innovations
Both models in the Zamba2 series implement innovative design options that differentiate them from others in their category. The backbone of the architecture consists of Mamba2 layers intertwined with shared attention layers, minimizing the overall parameter cost. This hybrid structure and the application of LoRA projection matrices allow each shared block to specialize in its unique position while maintaining relatively small additional parameter overhead.
These design innovations result in powerful and efficient models, giving users the best of both worlds: high performance and low computational requirements. This makes the Zamba2 series particularly suitable for deployment in scenarios with limited memory and computing resources, such as mobile and edge devices.
Practical applications and future directions
With the release of Zamba2-1.2B-Instruct and Zamba2-2.7B-Instruct, Zyphra has made significant progress in ai-based instruction following models. These models have many potential applications, including chatbots, personal assistants, and other conversational artificial intelligence systems. Their high performance and low latency make them ideal for real-time interaction scenarios, while their small memory footprint ensures they can be deployed in resource-constrained environments.
Zyphra plans to continue developing the Zamba series, and future updates are likely to include further optimizations and expansions of the hybrid SSM and transformer architecture. These developments are expected to advance what is possible in natural language understanding and generation, solidifying Zyphra's position as a leader in ai research and development.
In conclusion, the launch of Zamba2-1.2B-Instruct and Zamba2-2.7B-Instruct marks a new milestone for Zyphra, offering models that combine cutting-edge performance with efficient use of computational resources. As the field of ai continues to evolve, Zyphra's innovations in hybrid architectures will likely serve as a foundation for future advances in ai and natural language processing.
look at the Zyphra/Zamba2-1.2B Instructions and Zyphra/Zamba2-2.7B Instructions. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. If you like our work, you will love our information sheet.. Don't forget to join our SubReddit over 50,000ml
Are you interested in promoting your company, product, service or event to over 1 million ai developers and researchers? Let's collaborate!
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for social good. Their most recent endeavor is the launch of an ai media platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easily understandable to a wide audience. The platform has more than 2 million monthly visits, which illustrates its popularity among the public.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}