
In a world increasingly driven by the intersection of language and technology, the demand for versatile and powerful language models has never been greater. Traditional large language models (LLMs) have excelled in textual comprehension or coding tasks but seldom managed to strike a harmonious balance between the two. This imbalance has left a gap in the market for models that can seamlessly navigate textual reasoning and coding proficiency. Enter Lemur and Lemur-chat, two groundbreaking contributions to the realm of open pre-trained and supervised fine-tuned LLMs that aim to bridge this gap.
Creating language models that can proficiently handle both text and code has been a long-standing challenge. Existing LLMs have typically been specialized for textual comprehension or coding tasks, but seldom both. This specialization has left developers and researchers grappling with the need to choose between models that excel in one area while falling short in the other. Consequently, a pressing need has arisen for LLMs that can offer a multifaceted skill set encompassing understanding, reasoning, planning, coding, and context grounding.
While some solutions exist in the form of traditional LLMs, their limitations have remained evident. The industry has lacked models that can truly balance the intricate demands of both textual and code-related tasks. This has created a void in the landscape of language model agents, where an integrated approach to understanding, reasoning, and coding is essential.
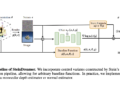
The Lemur project, spearheaded by XLang Lab in collaboration with Salesforce Research, seeks to address this critical gap in language model technology. Lemur and Lemur-chat represent a pioneering effort to develop open, pretrained, and supervised fine-tuned LLMs that excel in both text and code-related tasks. The cornerstone of this endeavor is the extensive pretraining of Llama 2 on a vast corpus of ~100 billion lines of code-intensive data. This pre-training phase is followed by supervised fine-tuning on ~300,000 instances of public instructional and dialog data. The result is a language model with enhanced coding and grounding abilities while retaining competitive textual reasoning and knowledge performance.
The performance metrics of Lemur and Lemur-chat are a testament to their prowess. Lemur stands out as it surpasses other open-source language models on coding benchmarks, demonstrating its coding proficiency. Simultaneously, it maintains its competitive edge in textual reasoning and knowledge-based tasks, showcasing its versatile skill set. Meanwhile, Lemur-chat significantly outperforms other open-source supervised fine-tuned models across various dimensions, indicating its exceptional capabilities in bridging the gap between text and code in conversational contexts.
The Lemur project represents a collaborative research effort with contributions from both XLang Lab and Salesforce Research, with support from generous gifts from Salesforce Research, Google Research, and Amazon AWS. While the journey towards a balanced open-source language model is ongoing, Lemur’s contributions have already begun reshaping the language model technology landscape. By offering a model that excels in both text and code-related tasks, Lemur provides a powerful tool for developers, researchers, and organizations seeking to navigate the increasingly intricate intersection of language and technology.
In conclusion, the Lemur project stands as a beacon of innovation in the world of language models. Its ability to harmoniously balance text and code-related tasks has addressed a longstanding challenge in the field. As Lemur continues to evolve and set new benchmarks, it promises to drive further research on agent models and establish a more powerful and balanced foundation for open-source language models. With Lemur, the future of language model technology is brighter and more versatile than ever before.
Check out the Github, HugginFace Page, and Reference Article. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 29k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
Niharika is a Technical consulting intern at Marktechpost. She is a third year undergraduate, currently pursuing her B.Tech from Indian Institute of Technology(IIT), Kharagpur. She is a highly enthusiastic individual with a keen interest in Machine learning, Data science and AI and an avid reader of the latest developments in these fields.





{kind=link}