 NEWSLETTER
NEWSLETTER
artificial intelligence (ai) has made progress in developing agents capable of executing complex tasks on digital platforms. These agents, often powered by large language models (LLMs), have the potential to dramatically improve human productivity by automating tasks within operating systems. ai agents that can perceive, plan, and act within environments such as the Windows operating system (OS) offer immense value as personal and professional tasks increasingly move into the digital realm. The ability of these agents to interact across a variety of applications and interfaces means they can handle tasks that typically require human oversight, with the ultimate goal of making human-computer interaction more efficient.
A major problem in developing these agents is accurately evaluating their performance in environments that reflect real-world conditions. While effective in specific domains such as web browsing or text-based tasks, most existing benchmarks fail to capture the complexity and diversity of tasks that real users face daily on platforms such as Windows. These benchmarks either focus on limited types of interactions or suffer from slow processing times, making them unsuitable for large-scale evaluations. To overcome this gap, there is a need for tools that can test agents’ capabilities on more dynamic, multi-step tasks across diverse domains in a highly scalable manner. Furthermore, current tools cannot efficiently parallelize tasks, causing full evaluations to take days instead of minutes.
Several benchmarks have been developed to evaluate ai agents, including OSWorld, which primarily focuses on Linux-based tasks. While these platforms provide useful insights into agent performance, they do not scale well to multimodal environments such as Windows. Other frameworks, such as WebLinx and Mind2Web, evaluate agent capabilities in web-based environments but need more depth to comprehensively test agent behavior in more complex operating system-based workflows. These limitations highlight the need for a benchmark that captures the full scope of human-computer interaction on a widely used operating system such as Windows, while ensuring fast evaluation through cloud-based parallelization.
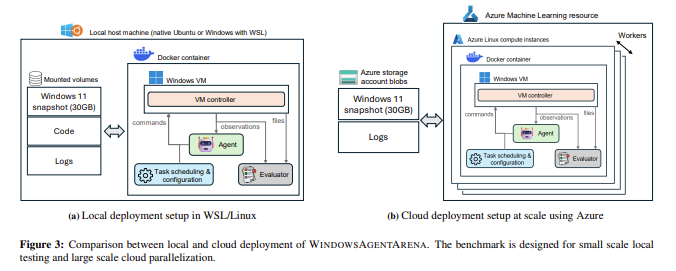
Researchers from Microsoft, Carnegie Mellon University and Columbia University presented the Windows Arena Agenta comprehensive, reproducible benchmark designed specifically for evaluating ai agents in a Windows operating system environment. This innovative tool allows agents to operate within a real Windows operating system, interacting with applications, tools, and web browsers, replicating tasks commonly performed by human users. By leveraging Azure’s scalable cloud infrastructure, the platform can parallelize evaluations, allowing a full benchmark run in just 20 minutes, in contrast to the multi-day evaluations that were typical of previous methods. This parallelization increases the speed of evaluations and ensures more realistic agent behavior by allowing them to interact with multiple tools and environments simultaneously.
The benchmark suite includes over 154 diverse tasks spanning multiple domains such as document editing, web browsing, system administration, encoding, and media consumption. These tasks are carefully designed to mirror everyday Windows workflows, with agents required to perform multi-step tasks such as creating document shortcuts, navigating file systems, and customizing settings in complex applications such as VSCode and LibreOffice Calc. WindowsAgentArena also features a new evaluation criteria that rewards agents based on task completion rather than simply following pre-recorded human demonstrations, allowing for more flexible and realistic task execution. The benchmark can be seamlessly integrated with Docker containers, providing a safe environment for testing and allowing researchers to scale their evaluations across multiple agents.
To demonstrate the effectiveness of WindowsAgentArena, researchers developed a new multimodal ai agent called NavigationNavi is designed to operate autonomously within the Windows operating system, using a combination of chain-of-thought prompts and multimodal perception to complete tasks. Researchers tested Navi on the WindowsAgentArena testbed, where the agent achieved a 19.5% success rate, significantly lower than the 74.5% success rate achieved by unassisted humans. While this performance highlights the challenges for ai agents to replicate human efficiency, it also underscores the potential for improvement as these technologies evolve. Navi also demonstrated strong performance on a secondary web-based testbed, Mind2Web, further demonstrating its adaptability across different environments.
The methods used to improve Navi’s performance are noteworthy. The agent relies on visual markers and screen analysis techniques, such as Mark Sets (SoMs), to understand and interact with the graphical aspects of the screen. These SoMs enable the agent to accurately identify buttons, icons, and text fields, making it more effective at completing tasks that involve multiple steps or require detailed navigation on the screen. Navi benefits from UIA tree analysis, a method that extracts visible elements from the Windows UI Automation tree, allowing for more precise interactions with the agent.
In conclusion, WindowsAgentArena is a significant advancement in evaluating ai agents in real-world OS environments. It addresses the limitations of previous benchmarks by offering a scalable, reproducible, and realistic testing platform that enables rapid and parallelized evaluations of agents in the Windows OS ecosystem. With its diverse set of tasks and innovative evaluation metrics, this benchmark offers researchers and developers the tools to push the boundaries of ai agent development. Navi’s performance, while not yet matching human efficiency, showcases the benchmark’s potential to accelerate progress in multimodal agent research. Its advanced perception techniques, such as SoMs and UIA analysis, further pave the way for more capable and efficient ai agents in the future.
Take a look at the Paper, Codeand Project pageAll credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram Channel and LinkedIn GrAbove!. If you like our work, you will love our fact sheet..
Don't forget to join our SubReddit of over 50,000 ml
FREE ai WEBINAR: 'SAM 2 for Video: How to Optimize Your Data' (Wednesday, September 25, 4:00 am – 4:45 am EST)
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary engineer and entrepreneur, Asif is committed to harnessing the potential of ai for social good. His most recent initiative is the launch of an ai media platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easily understandable to a wide audience. The platform has over 2 million monthly views, illustrating its popularity among the public.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}