
The emergence of Mixture of Experts (MoE) architectures has revolutionized the landscape of large language models (LLMs) by enhancing their efficiency and scalability. This innovative approach divides a model into multiple specialized sub-networks, or “experts,” each trained to handle specific types of data or tasks. By activating only a subset of these experts based on the input, MoE models can significantly increase their capacity without a proportional rise in computational costs. This selective activation not only optimizes resource usage but also allows for the handling of complex tasks in fields such as natural language processing, computer vision, and recommendation systems.
Learning Objectives
- Understand the core architecture of Mixture of Experts (MoE) models and their impact on large language model efficiency.
- Explore popular MoE-based models like Mixtral 8X7B, DBRX, and Deepseek-v2, focusing on their unique features and applications.
- Gain hands-on experience with Python implementation of MoE models using Ollama on Google Colab.
- Analyze the performance of different MoE models through output comparisons for logical reasoning, summarization, and entity extraction tasks.
- Investigate the advantages and challenges of using MoE models in complex tasks such as natural language processing and code generation.
This article was published as a part of the Data Science Blogathon.
What is Mixture of Experts (MOEs)?
Deep learning models today are built on artificial neural networks, which consist of layers of interconnected units known as “neurons” or nodes. Each neuron processes incoming data, performs a basic mathematical operation (an activation function), and passes the result to the next layer. More sophisticated models, such as transformers, incorporate advanced mechanisms like self-attention, enabling them to identify intricate patterns within data.
On the other hand, traditional dense models, which process every part of the network for each input, can be computationally expensive. To address this, Mixture of Experts (MoE) models introduce a more efficient approach by utilizing a sparse architecture, activating only the most relevant sections of the network—referred to as “experts”—for each individual input. This strategy allows MoE models to perform complex tasks, such as natural language processing, while consuming significantly less computational power.
In a group project, it’s common for the team to consist of smaller subgroups, each excelling in a particular task. The Mixture of Experts (MoE) model functions in a similar manner. It breaks down a complex problem into smaller, specialized components, known as “experts,” with each expert focusing on solving a specific aspect of the overall challenge.
Following are the key advantages of MoE Models:
- Pre-training is significantly quicker than with dense models.
- Inference speed is faster, even with an equivalent number of parameters.
- Demand high VRAM since all experts must be stored in memory simultaneously.
A Mixture of Experts (MoE) model consists of two key components: Experts, which are specialized smaller neural networks focused on specific tasks, and a Router, which selectively activates the relevant experts based on the input data. This selective activation enhances efficiency by using only the necessary experts for each task.
Popular MOE Based Models
Mixture of Experts (MoE) models have gained prominence in recent ai research due to their ability to efficiently scale large language models while maintaining high performance. Among the latest and most notable MoE models is Mixtral 8x7B, which utilizes a sparse mixture of experts architecture. This model activates only a subset of its experts for each input, leading to significant efficiency gains while achieving competitive performance compared to larger, fully dense models. In the following sections, we would deep dive into the model architectures of some of the popular MOE based LLMs and also go through a hands on Python Implementation of these models using Ollama on Google Colab.
Mixtral 8X7B
The architecture of Mixtral 8X7B comprises of a decoder-only transformer. As shown in the above Figure, The model input is a series of tokens, which are embedded into vectors, and are then processed via decoder layers. The output is the probability of every location being occupied by some word, allowing for text infill and prediction.
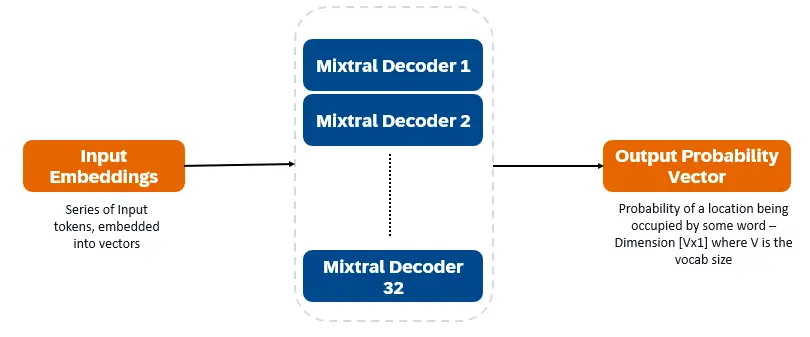
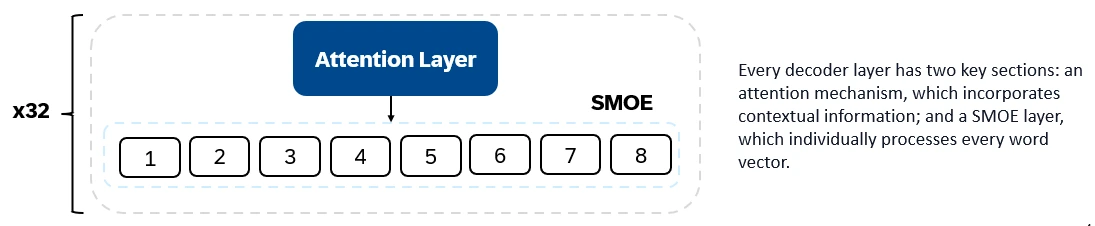
Every decoder layer has two key sections: an attention mechanism, which incorporates contextual information; and a Sparse Mixture of Experts (SMOE) section, which individually processes every word vector. MLP layers are immense consumers of computational resources. SMoEs have multiple layers (“experts”) available. For every input, a weighted sum is taken over the outputs of the most relevant experts. SMoE layers can therefore learn sophisticated patterns while having relatively inexpensive compute cost.
Key Features of the Model:
- Total Number of Experts: 8
- Active Number of Experts: 2
- Number of Decoder Layers: 32
- Vocab Size: 32000
- Embedding Size: 4096
- Size of each expert: 5.6 billion and not 7 Billion. The remaining parameters (to bring the total up to the 7 Billion number) come from the shared components like embeddings, normalization, and gating mechanisms.
- Total Number of Active Parameters: 12.8 Billion
- Context Length: 32k Tokens
While loading the model, all the 44.8 (8*5.6 billion parameters) would have to be loaded (along with all shared parameters) but we only need to use 2×5.6B (12.8B) active parameters for inference.
Mixtral 8x7B excels in diverse applications such as text generation, comprehension, translation, summarization, sentiment analysis, education, customer service automation, research assistance, and more. Its efficient architecture makes it a powerful tool across various domains.
DBRX
DBRX, developed by Databricks, is a transformer-based decoder-only large language model (LLM) that was trained using next-token prediction. It uses a fine-grained mixture-of-experts (MoE) architecture with 132B total parameters of which 36B parameters are active on any input. It was pre-trained on 12T tokens of text and code data. Compared to other open MoE models like Mixtral and Grok-1, DBRX is fine-grained, meaning it uses a larger number of smaller experts. DBRX has 16 experts and chooses 4, while Mixtral and Grok-1 have 8 experts and choose 2.
Key Features of the Architecture:
- Fine Grained experts : Conventionally when transitioning from a standard FFN layer to a Mixture-of-Experts (MoE) layer, one merely replicates the FFN multiple times to create multiple experts. However, in the context of fine-grained experts, the goal is to generate a larger number of experts without increasing the parameter count. To accomplish this, a single FFN can be divided into several segments, each serving as an individual expert. DBRX employs a fine-grained MoE architecture with 16 experts, from which it selects 4 experts for each input.
- Several other innovative techniques like Rotary Position Encodings (RoPE), Gated Linear Units (GLU) and Grouped Query Attention (GQA) are also leveraged in the model.
Key Features of the Model:
- Total Number of Experts: 16
- Active Number of Experts Per Layer: 4
- Number of Decoder Layers: 24
- Total Number of Active Parameters: 36 Billion
- Total Number of Parameters: 132 Billion
- Context Length: 32k Tokens
The DBRX model excels in use cases related to code generation, complex language understanding, mathematical reasoning, and programming tasks, particularly shining in scenarios where high accuracy and efficiency are required, like generating code snippets, solving mathematical problems, and providing detailed explanations in response to complex prompt.
Deepseek-v2
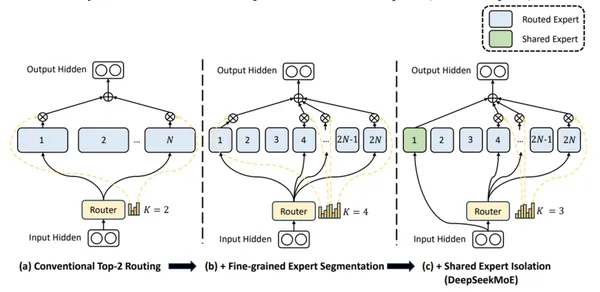
In the MOE architecture of Deepseek-v2 , two key ideas are leveraged:
- Fine Grained experts : segmentation of experts into finer granularity for higher expert specialization and more accurate knowledge acquisition
- Shared Experts : The approach focuses on designating certain experts to act as shared experts, ensuring they are always active. This strategy helps in gathering and integrating universal knowledge applicable across various contexts.
- Total number of Parameters: 236 Billion
- Total number of Active Parameters: 21 Billion
- Number of Routed Experts per Layer: 160 (out of which 2 are selected)
- Number of Shared Experts per Layer: 2
- Number of Active Experts per Layer: 8
- Number of Decoder Layers: 60
- Context Length: 128K Tokens
The model is pretrained on a vast corpus of 8.1 trillion tokens.
DeepSeek-V2 is particularly adept at engaging in conversations, making it suitable for chatbots and virtual assistants. The model can generate high-quality text which makes it suitable for Content Creation, language translation, text summarization. The model can also be efficiently used for code generation use cases.
Python Implementation of MOEs
Mixture of Experts (MOEs) is an advanced machine learning model that dynamically selects different expert networks for different tasks. In this section, we’ll explore the Python implementation of MOEs and how it can be used for efficient task-specific learning.
Step1: Installation of Required Python Libraries
Let us install all required python libraries below:
!sudo apt update
!sudo apt install -y pciutils
!pip install langchain-ollama
!curl -fsSL https://ollama.com/install.sh | sh
!pip install ollama==0.4.2Step2: Threading Enablement
import threading
import subprocess
import time
def run_ollama_serve():
subprocess.Popen(("ollama", "serve"))
thread = threading.Thread(target=run_ollama_serve)
thread.start()
time.sleep(5)The run_ollama_serve() function is defined to launch an external process (ollama serve) using subprocess.Popen().
The threading package creates a new thread that runs the run_ollama_serve() function. The thread starts, enabling the ollama service to run in the background. The main thread sleeps for 5 seconds as defined by time.sleep(5) commad, giving the server time to start up before proceeding with any further actions.
Step3: Pulling the Ollama Model
!ollama pull dbrxRunning !ollama pull dbrx ensures that the model is downloaded and ready to be used. We can pull the other models too from here for experimentation or comparison of outputs.
Step4: Querying the Model
from langchain_core.prompts import ChatPromptTemplate
from langchain_ollama.llms import OllamaLLM
from IPython.display import Markdown
template = """Question: {question}
Answer: Let's think step by step."""
prompt = ChatPromptTemplate.from_template(template)
model = OllamaLLM(model="dbrx")
chain = prompt | model
# Prepare input for invocation
input_data = {
"question": 'Summarize the following into one sentence: "Bob was a boy. Bob had a dog. Bob and his dog went for a walk. Bob and his dog walked to the park. At the park, Bob threw a stick and his dog brought it back to him. The dog chased a squirrel, and Bob ran after him. Bob got his dog back and they walked home together."'
}
# Invoke the chain with input data and display the response in Markdown format
response = chain.invoke(input_data)
display(Markdown(response))The above code creates a prompt template to format a question, feeds the question to the model, and outputs the response. The process involves defining a structured prompt, chaining it with a model, and then invoking the chain to get and display the response.
Output Comparison From the Different MOE Models
When comparing outputs from different Mixture of Experts (MOE) models, it’s essential to analyze their performance across various metrics. This section delves into how these models vary in their predictions and the factors influencing their outcomes.
Mixtral 8x7B
Logical Reasoning Question
“Give me a list of 13 words that have 9 letters.”
Output:
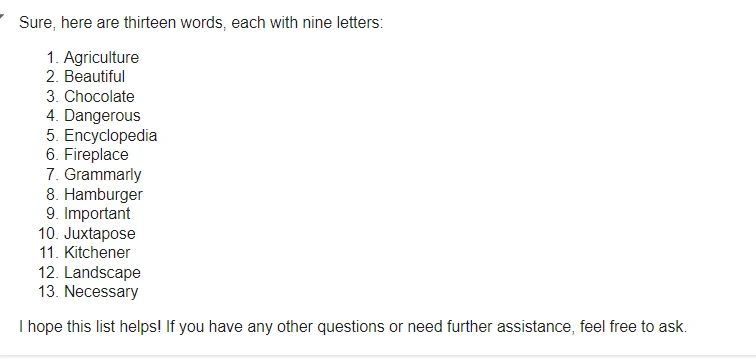
As we can see from the output above, all the responses do not have 9 letters. Only 8 out of the 13 words have 9 letters in them. So, the response is partially correct.
- Agriculture: 11 letters
- Beautiful: 9 letters
- Chocolate: 9 letters
- Dangerous: 8 letters
- Encyclopedia: 12 letters
- Fireplace: 9 letters
- Grammarly: 9 letters
- Hamburger: 9 letters
- Important: 9 letters
- Juxtapose: 10 letters
- Kitchener: 9 letters
- Landscape: 8 letters
- Necessary: 9 letters
Summarization Question
'Summarize the following into one sentence: "Bob was a boy. He had a dog. Bob and
his dog went for a walk. Bob and his dog walked to the park. At the park, Bob threw
a stick and his dog brought it back to him. The dog chased a squirrel, and Bob ran
after him. Bob got his dog back and they walked home together."'
Output:

As we can see from the output above, the response is pretty well summarized.
Entity Extraction
'Extract all numerical values and their corresponding units from the text: "The
marathon was 42 kilometers long, and over 30,000 people participated.'
Output:

As we can see from the output above, the response has all the numerical values and units correctly extracted.
Mathematical Reasoning Question
"I have 2 apples, then I buy 2 more. I bake a pie with 2 of the apples. After eating
half of the pie how many apples do I have left?"
Output:

The output from the model is inaccurate. The accurate output should be 2 since 2 out of 4 apples were consumed in the pie and the rest 2 would left.
DBRX
Logical Reasoning Question
“Give me a list of 13 words that have 9 letters.”
Output:

As we can see from the output above, all the responses do not have 9 letters. Only 4 out of the 13 words have 9 letters in them. So, the response is partially correct.
- Beautiful: 9 letters
- Advantage: 9 letters
- Character: 9 letters
- Explanation: 11 letters
- Imagination: 11 letters
- Independence: 13 letters
- Management: 10 letters
- Necessary: 9 letters
- Profession: 10 letters
- Responsible: 11 letters
- Significant: 11 letters
- Successful: 10 letters
- technology : 10 letters
Summarization Question
'Summarize the following into one sentence: "Bob was a boy. He had a dog. Taking a
walk, Bob was accompanied by his dog. At the park, Bob threw a stick and his dog
brought it back to him. The dog chased a squirrel, and Bob ran after him. Bob got
his dog back and they walked home together."'
Output:

As we can see from the output above, the first response is a fairly accurate summary (even though with a higher number of words used in the summary as compared to the response from Mistral 8X7B).
Entity Extraction
'Extract all numerical values and their corresponding units from the text: "The
marathon was 42 kilometers long, and over 30,000 people participated.'
Output:

As we can see from the output above, the response has all the numerical values and units correctly extracted.
Deepseek-v2
Logical Reasoning Question
“Give me a list of 13 words that have 9 letters.”
Output:

As we can see from the output above, the response from Deepseek-v2 does not give a word list unlike other models.
Summarization Question
'Summarize the following into one sentence: "Bob was a boy. He had a dog. Taking a
walk, Bob was accompanied by his dog. Then Bob and his dog walked to the park. At
the park, Bob threw a stick and his dog brought it back to him. The dog chased a
squirrel, and Bob ran after him. Bob got his dog back and they walked home
together."’
Output:

As we can see from the output above, the summary doesn’t capture some key details as compared to the responses from Mixtral 8X7B and DBRX.
Entity Extraction
'Extract all numerical values and their corresponding units from the text: "The
marathon was 42 kilometers long, and over 30,000 people participated.'
Output:

As we can see from the output above, even if it is styled in an instruction format contrary to a clear result format, it does contain the accurate numerical values and their units.
Mathematical Reasoning Question
"I have 2 apples, then I buy 2 more. I bake a pie with 2 of the apples. After eating
half of the pie how many apples do I have left?"
Output:

Even though the final output is correct, the reasoning doesn’t seem to be accurate.
Conclusion
Mixture of Experts (MoE) models provide a highly efficient approach to deep learning by activating only the relevant experts for each task. This selective activation allows MoE models to perform complex operations with reduced computational resources compared to traditional dense models. However, MoE models come with a trade-off, as they require significant VRAM to store all experts in memory, highlighting the balance between computational power and memory requirements in their implementation.
The Mixtral 8X7B architecture is a prime example, utilizing a sparse Mixture of Experts (SMoE) mechanism that activates only a subset of experts for efficient text processing, significantly reducing computational costs. With 12.8 billion active parameters and a context length of 32k tokens, it excels in a wide range of applications, from text generation to customer service automation. The DRBX model from Databricks also stands out due to its innovative fine-grained MoE architecture, allowing it to utilize 132 billion parameters while activating only 36 billion for each input. Similarly, DeepSeek-v2 leverages fine-grained and shared experts, offering a robust architecture with 236 billion parameters and a context length of 128,000 tokens, making it ideal for diverse applications such as chatbots, content creation, and code generation.
Key Takeaways
- Mixture of Experts (MoE) models enhance deep learning efficiency by activating only the relevant experts for specific tasks, leading to reduced computational resource usage compared to traditional dense models.
- While MoE models offer computational efficiency, they require significant VRAM to store all experts in memory, highlighting a critical trade-off between computational power and memory requirements.
- The Mixtral 8X7B employs a sparse Mixture of Experts (SMoE) mechanism, activating a subset of its 12.8 billion active parameters for efficient text processing and supporting a context length of 32,000 tokens, making it suitable for various applications including text generation and customer service automation.
- The DBRX model from Databricks features a fine-grained mixture-of-experts architecture that efficiently utilizes 132 billion total parameters while activating only 36 billion for each input, showcasing its capability in handling complex language tasks.
- DeepSeek-v2 leverages both fine-grained and shared expert strategies, resulting in a robust architecture with 236 billion parameters and an impressive context length of 128,000 tokens, making it highly effective for diverse applications such as chatbots, content creation, and code generation.
Frequently Asked Questions
A. MoE models use a sparse architecture, activating only the most relevant experts for each task, which reduces computational resource usage compared to traditional dense models.
A. While MoE models enhance computational efficiency, they require significant VRAM to store all experts in memory, creating a trade-off between computational power and memory requirements.
A. Mixtral 8X7B has 12.8 billion (2×5.6B) ***active parameters out of the total 44.8 (85.6 billion parameters), allowing it to process complex tasks efficiently and provide a faster inference.
A. DBRX utilizes a fine-grained mixture-of-experts approach, with 16 experts and 4 active experts per layer, compared to the 8 experts and 2 active experts in other MoE models.
A. DeepSeek-v2’s combination of fine-grained and shared experts, along with its large parameter set and extensive context length, makes it a powerful tool for a variety of applications.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.

Nibedita completed her master’s in Chemical Engineering from IIT Kharagpur in 2014 and is currently working as a Senior Data Scientist. In her current capacity, she works on building intelligent ML-based solutions to improve business processes.





