 NEWSLETTER
NEWSLETTER
Sponsored content
Image from NVIDIA
As data scientists, we are constantly looking for tools and frameworks that allow us to process and analyze data efficiently. In this blog post, we will explore OpenUSD, a powerful framework that goes beyond its traditional use in computer graphics and offers interesting possibilities for data science processes.
OpenUSD or universal scene descriptionprovides a versatile and extensible platform for managing and processing complex data models. It can represent a wide range of data types and enhance data sets across multiple domains.
Let’s dive into what data scientists need to know about OpenUSD and how it can improve their workflows.
Common Data Modeling
OpenUSD features a unified data model that enables data scientists to efficiently represent and manipulate complex three-dimensional data structures. With USD, object data can be organized into hierarchical scene graphs. This hierarchical structure is particularly useful when working with large-scale data sets or complex data dependencies.
Joining the OpenUSD ecosystem also enables easy data sharing and reuse. Data sources in OpenUSD can be more easily integrated into an aggregated view that can encompass content from other file formats.
File Format Plugins
USD file format plugins provide a way to leverage the power of OpenUSD while maintaining existing datasets in their current formats. File format plugins can read and translate a file format into OpenUSD data on the fly.
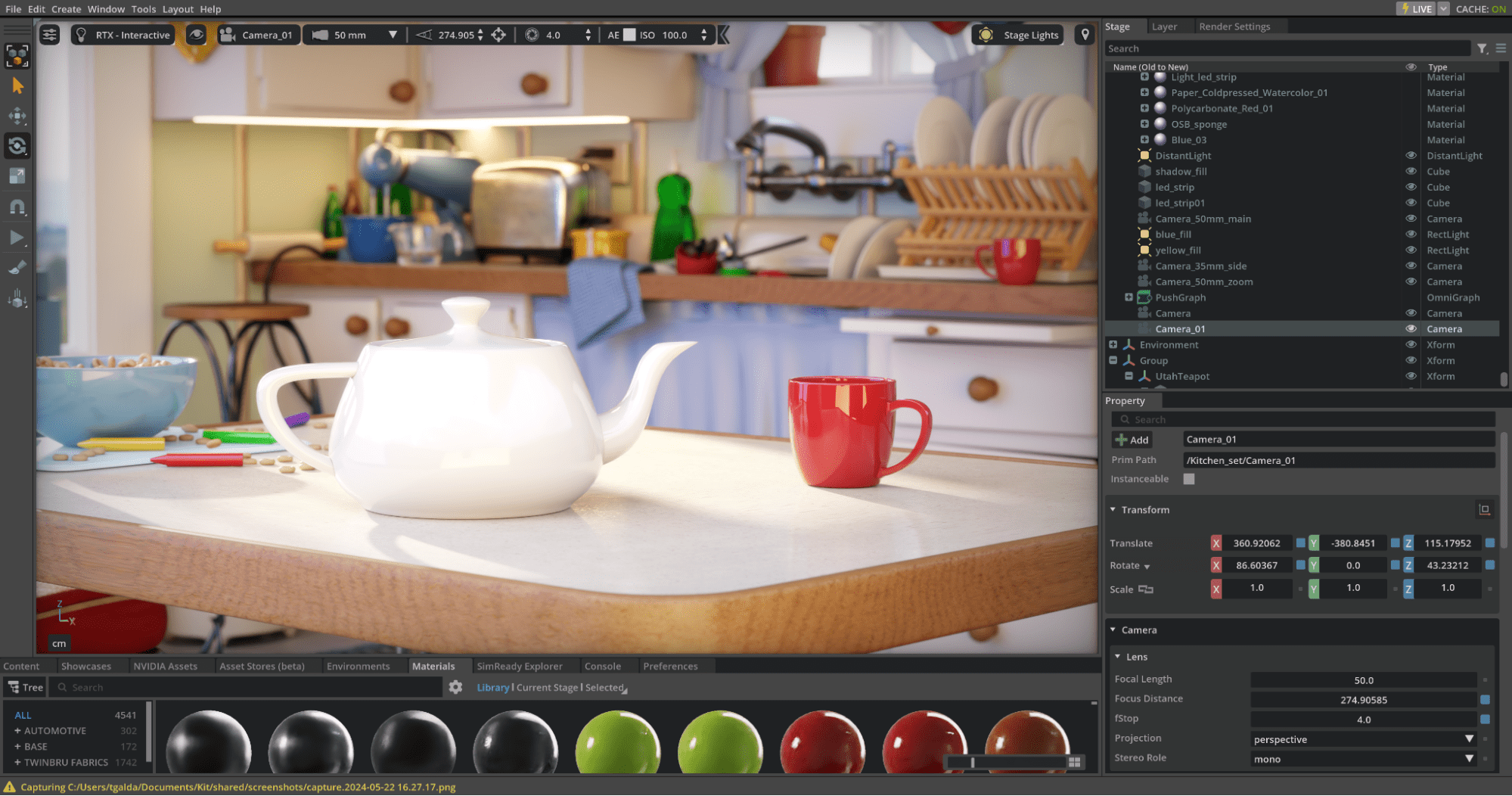
For example, in 3D data science, Wavefront OBJ files are popular for 3D mesh data and there are large datasets using this format. OBJ file format plugin like the plugin recently released in open source by AdobeYou can reference existing OBJ data and compose it in OpenUSD to add or override attributes or use it for scene assembly. kitchen.usd shows an example of a kitchen scene setup using OBJ models for a teapot and a table. The teapot's position in the scene is overridden to rotate and move it on the table.
kitchen.usd
#usda 1.0
(
defaultPrim = "World"
metersPerUnit = 1.0
upAxis = "Z"
)
def Xform "World"
{
def "teapot" (prepend references = @utah_teapot.obj@)
{
float3 xformOp:rotateXYZ = (0, 0, 0)
float3 xformOp:scale = (1, 1, 1)
double3 xformOp:translate = (0, 0, 0)
uniform token() xformOpOrder = ("xformOp:translate", "xformOp:rotateXYZ", "xformOp:scale")
}
}
This also applies to non-3D data.
Composability
OpenUSD excels as a composable scene description. This is done in two main ways: scene aggregation and progressive refinement. Scene aggregation involves referencing many 3D assets from different sources and non-destructively assembling them to form a larger scene. You can make changes to the referenced 3D assets and the assemblies will also pick up the change. Progressive refinement allows you to start with a basic, loosely detailed asset and progressively add additional layers that non-destructively add detail to the asset to further refine it from basic to fine.
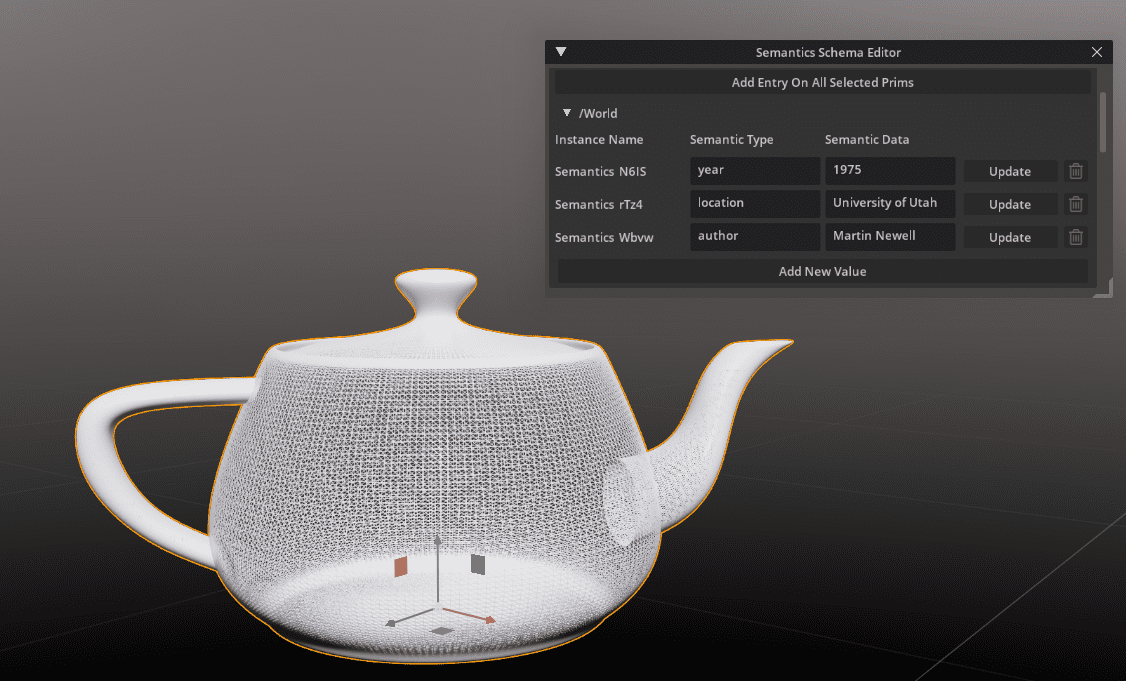
Looking back at the OBJ mesh example from earlier, we can start with just the OBJ mesh data and use OpenUSD to add physical material properties, semantic labels, and other ancillary aspects such as geospatial attribution. In this example, the refinement is composed using sublayers for the different types of details I want to add to my asset.
teapot.usd
#usda 1.0
(
defaultPrim = "World"
metersPerUnit = 1.0
upAxis = "Z"
subLayers = (
@./semantic_labels.usd@
@./materials.usd@
@./utah_teapot.obj@
)
)
def Xform "World"
{
}
Creating datasets this way makes them extremely portable and modular. It also allows you to improve the fidelity and quality of your data sources.
I can share the mesh with all attributes or I can mute or delete the layers that are not relevant for different pipelines. SimReady Specification and Dataset It is an example of these principles in practice today.
Custom channeling
OpenUSD's Hydra framework gives data scientists the ability to create custom pipelines to process and analyze data. Hydra enables the implementation of business logic as a customizable chain of execution scenario indices. This decoupling of data processing from specific execution environments allows data scientists to leverage the power of USD in their own data science workflows.
Extensibility
One of the key advantages of OpenUSD is its extensibility. Data scientists can extend the capabilities of OpenUSD by creating their own scene delegates and render delegates. This means that any scene graph capable of responding to queries made by scene delegates can be used, providing flexibility to integrate various data sources and formats.
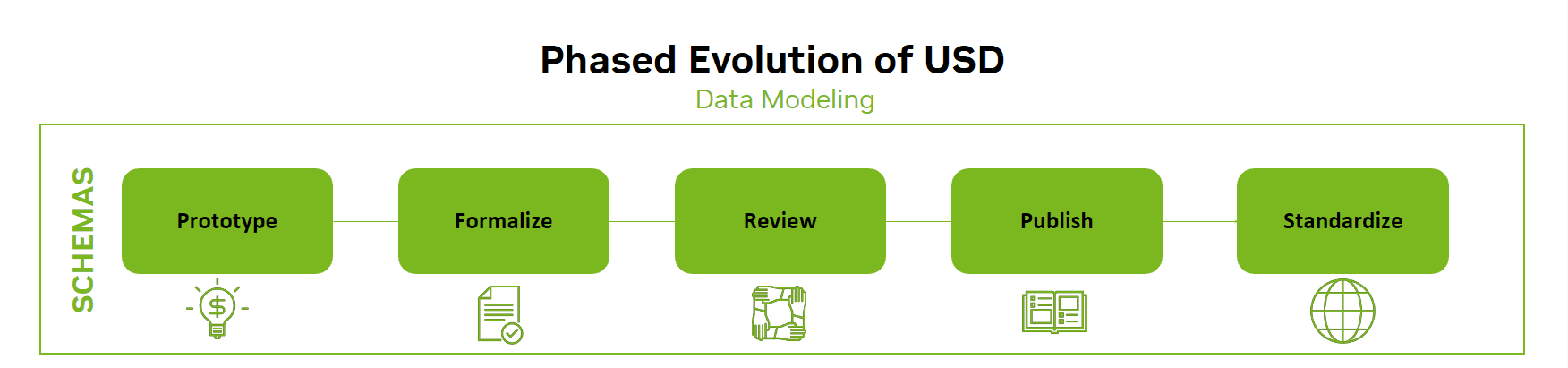
OpenUSD is also extensible through custom methods. schemesAs data scientists begin to map concepts from their data models to OpenUSD, they may discover that not all concepts can be mapped directly, and that a translation to an existing concept in OpenUSD may not be adequate. When data scientists identify a gap in conceptual data mapping, they can formalize the novel concept into a new schema that can be leveraged immediately.
As the schema matures, data scientists are encouraged to share their schemas with other organizations and institutions and to guide the schema through the entire design process so that it can be reviewed, published, and standardized. A good example of this is the semantic scheme proposal from NVIDIA to standardize semantic labeling of 3D assets for synthetic data generation.
Procedural processing with Hydra 2.0
Hydra 2.0 Hydra 2.0 takes OpenUSD capabilities to the next level by introducing procedural scene index processing. This allows data scientists to process chains of scene indexes across multiple pipeline steps, enabling more complex and customizable workflows. With Hydra 2.0, data scientists can iterate and optimize their pipelines, making it easier to experiment with different data processing techniques. Scene index plugins are also portable, so you can share your modular business logic across OpenUSD applications.
OpenUSD offers data scientists a powerful and versatile framework for managing and processing complex data models. Its unified data model, extensibility, and generality make it an invaluable framework for data science workflows and processes. With extensibility in both common data modeling through schema plugins and runtime cores in Hydra 2.0, OpenUSD enables data scientists to efficiently process and analyze large-scale data sets, enabling faster and more scalable computations. As data scientists, it is essential to explore and leverage tools like OpenUSD to unleash the full potential of our data-driven efforts.
A growing number of tools and applications OpenUSD import and export is now supported. Developers can learn how to add OpenUSD support to their applications at NVIDIA OpenUSD Documentationwhich includes getting started, guided learning, and technical references to get you started.
To access more resources and get started with OpenUSD, visit the NVIDIA website. Description of the universal scene page. Get started with NVIDIA Omniverse by downloading the standard license for free.
The Alliance for OpenUSD (AOUSD) is an open, non-profit organization dedicated to promoting 3D content interoperability through OpenUSD.
Learn more and become a Member today.





{kind=link}