 NEWSLETTER
NEWSLETTER
Large language models (LLMs) have demonstrated exceptional capabilities in understanding human language, reasoning, and knowledge acquisition, suggesting their potential to serve as autonomous agents. However, training high-performance web agents based on open LLM within online environments, such as WebArena, faces several critical challenges. The first challenge is the insufficiency of predefined training tasks in online benchmarks. The next challenge is to evaluate the success of arbitrary web browsing tasks due to the scarcity and high cost of feedback signals. Finally, the absence of a predefined training set requires online exploration, leading to a drift in policy distribution and potential catastrophic forgetting, which can decrease agent performance over time.
Existing methods include adopting LLM as agents and reinforcement learning (RL) for LLM. Current research on LLM as Agents has two main categories: training-free and training-based approaches. While some studies have used powerful LLMs such as GPT-4 to generate proofs, the accuracy of these methods remains insufficient for complex tasks. Researchers have explored RL techniques to address this challenge, which use sequential decision making to control devices and interact with complex environments. Existing RL-based methods, such as AgentQ, which uses DPO for policy updates and critical actor architectures, have shown promise in complex device control tasks. However, limited and sparse feedback signals are often binary of success or failure after multiple rounds of interaction in web-based tasks.
Researchers from Tsinghua University and Zhipu ai have proposed WEBRL, a self-evolving online curriculum RL framework designed to train high-performance web agents using open LLMs. Addresses key challenges in building LLM web agents, including sparsity of training tasks, sparse feedback signals, and drift in policy distribution in online learning. Additionally, it uses three key components:
- A self-evolving curriculum that generates new tasks from failed attempts.
- A robust outcome-monitored reward model (ORM)
- Adaptive RL strategies to ensure consistent improvements.
Additionally, WEBRL bridges the gap between open and proprietary LLM-based web agents, creating a form of more accessible and powerful autonomous web interaction systems.
WEBRL uses a self-evolving online curriculum that leverages the trial and error process inherent in exploration to address the shortage of web agent training tasks. In each training phase, WEBRL autonomously generates new tasks from failed attempts in the previous phase, providing a progressive learning trajectory. It also incorporates a KL divergence term between the reference and actor policies in its learning algorithm to reduce the change in policy distribution induced by curriculum-based RL. This limitation on policy updates promotes stability and prevents catastrophic forgetting. Furthermore, WEBRL implements an augmented experience replay buffer with a novel actor trust filtering strategy.
The results obtained for Llama-3.1-8B trained using WEBRL achieve an average accuracy of 42.4%, outperforming all baseline approaches including instruction and training alternatives. WEBRL excels in specific tasks such as Gitlab (46.7%) and CMS (54.3%), showing its ability to address complex web tasks effectively. Furthermore, it outperforms imitation learning-based methods such as SFT and Filtered BC. Furthermore, it consistently outperforms DigiRL, a previous state-of-the-art method that performs policy updates on a fixed, predefined set of tasks, which may not align with the model's current skill level. WEBRL addresses this by using self-evolving curricular learning, adjusting task complexity based on model capabilities, promoting broader exploration, and supporting continuous improvement.
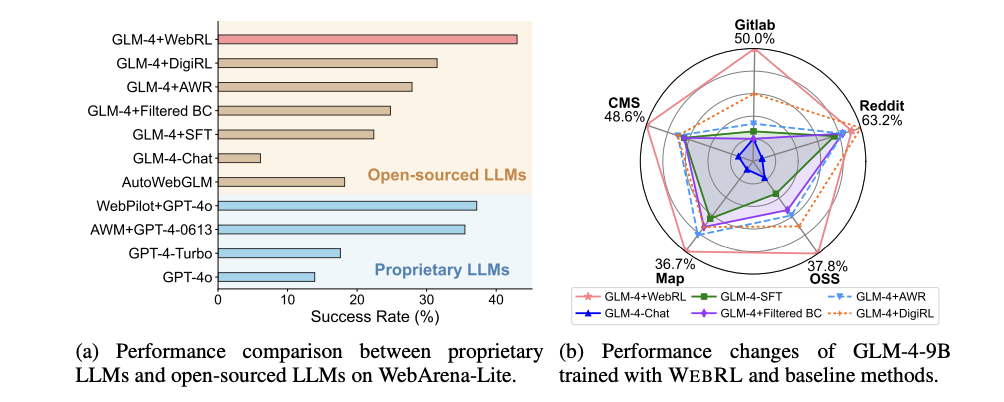
In this paper, researchers have presented WEBRL, a novel self-evolving online curriculum RL framework for training LLM-based web agents. Addresses critical challenges in building effective LLM web agents, including sparsity of training tasks, sparsity of feedback signals, and drift in policy distribution in online learning. The results demonstrate that WEBRL enables LLM-based web agents to outperform existing state-of-the-art approaches, including proprietary LLM APIs, and these findings help improve the capabilities of open source LLMs for web-based tasks. paving the way for more accessible and powerful autonomous web interaction systems. The successful application of WEBRL on different LLM architectures, such as Llama-3.1 and GLM-4, validates the robustness and adaptability of the proposed framework.
look at the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. If you like our work, you will love our information sheet.. Don't forget to join our SubReddit over 55,000ml.
(Sponsorship opportunity with us) Promote your research/product/webinar to over 1 million monthly readers and over 500,000 community members

Sajjad Ansari is a final year student of IIT Kharagpur. As a technology enthusiast, he delves into the practical applications of ai with a focus on understanding the impact of ai technologies and their real-world implications. Its goal is to articulate complex ai concepts in a clear and accessible way.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}