
Supongamos que desea raspar los sitios web de la competencia para obtener la información de su página de precios. ¿Qué vas a hacer? Copiar y pegar o ingresar datos manualmente es demasiado lento, requiere mucho tiempo y es propenso a errores. Puede automatizarlo fácilmente usando Python.
Veamos cómo raspar páginas web usando python en este tutorial.
¿Cuáles son las diferentes bibliotecas de web scraping de Python?
Python es popular para el web scraping debido a la abundancia de bibliotecas de terceros que pueden desechar estructuras HTML complejas, analizar texto e interactuar con formularios HTML. Aquí, hemos enumerado algunas de las principales bibliotecas de raspado web de Python.
- Urllib3 es una poderosa biblioteca de cliente HTTP para Python. Esto facilita la realización de solicitudes HTTP mediante programación. Maneja encabezados HTTP, reintentos, redireccionamientos y otros detalles de bajo nivel, lo que la convierte en una excelente biblioteca para el web scraping. También es compatible con la verificación SSL, la agrupación de conexiones y el proxy.
- HermosaSopa le permite analizar documentos HTML y XML. Puede navegar fácilmente a través del árbol de documentos HTML y extraer etiquetas, metatítulos, atributos, texto y otro contenido mediante la API. BeautifulSoup también es conocido por su sólido manejo de errores.
- Sopa Mecánica automatiza la interacción entre un navegador web y un sitio web de manera eficiente. Proporciona una API de alto nivel para web scraping que simula el comportamiento humano. Con MechanicalSoup, puede interactuar con formularios HTML, hacer clic en botones e interactuar con elementos como un usuario real.
- Peticiones es una biblioteca de Python simple pero poderosa para realizar solicitudes HTTP. Está diseñado para ser fácil de usar e intuitivo, con una API limpia y consistente. Con Solicitudes, puede enviar fácilmente solicitudes GET y POST, y manejar cookies, autenticación y otras funciones HTTP. También es muy utilizado en web scraping debido a su sencillez y facilidad de uso.
- Selenio le permite automatizar navegadores web como Chrome, Firefox y Safari y simular la interacción humana con los sitios web. Puede hacer clic en botones, completar formularios, desplazarse por las páginas y realizar otras acciones. También se utiliza para probar aplicaciones web y automatizar tareas repetitivas.
- pandas permite almacenar y manipular datos en varios formatos, incluidas las bases de datos CSV, Excel, JSON y SQL. Con Pandas, puede limpiar, transformar y analizar fácilmente los datos extraídos de los sitios web.
Extraiga texto de cualquier página web con un solo clic. Diríjase al raspador del sitio web de Nanonets, agregue la URL y haga clic en “Raspar” y descargue el texto de la página web como un archivo al instante. Pruébelo gratis ahora.
¿Cómo extraer datos de sitios web usando python?
Echemos un vistazo al proceso paso a paso del uso de Python para extraer datos del sitio web.
Paso 1: elija el sitio web y la URL de la página web
El primer paso es seleccionar el sitio web que desea raspar. Para este tutorial en particular, raspamos https://www.imdb.com/. Intentaremos extraer datos sobre las películas mejor calificadas en el sitio web.
Paso 2: inspeccionar el sitio web
Ahora el siguiente paso es comprender la estructura del sitio web. Entiende cuáles son los atributos de los elementos que son de tu interés. Haga clic derecho en el sitio web para seleccionar “Inspeccionar”. Esto abrirá el código HTML. Utilice la herramienta de inspección para ver el nombre de todos los elementos que se utilizarán en el código.
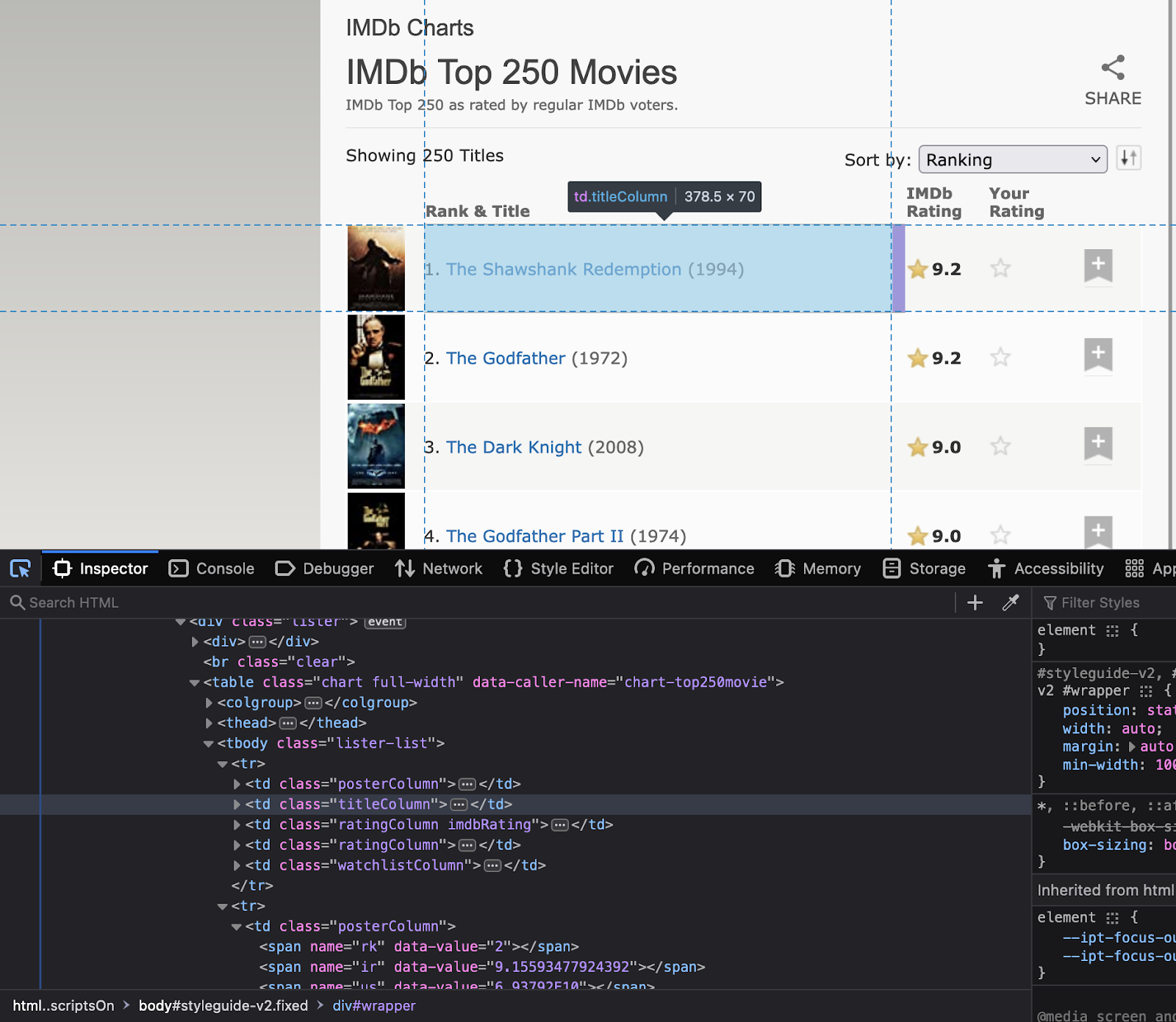
Tenga en cuenta los nombres de clase y los identificadores de estos elementos, ya que se utilizarán en el código de Python.
Paso 3: Instalación de las bibliotecas importantes
Como se discutió anteriormente, Python tiene varias bibliotecas de web scraping. Hoy, usaremos las siguientes bibliotecas:
- peticiones – para realizar solicitudes HTTP al sitio web
- HermosaSopa – para analizar el código HTML
- pandas – para almacenar los datos raspados en un marco de datos
- tiempo – para agregar un retraso entre las solicitudes para evitar abrumar el sitio web con solicitudes
Instale las bibliotecas usando el siguiente comando
pip install requests beautifulsoup4 pandas timePaso 4: escribir el código de Python
Ahora es el momento de escribir el código principal de Python. El código realizará los siguientes pasos:
- Uso de solicitudes para enviar una solicitud HTTP GET
- Usando BeautifulSoup para analizar el código HTML
- Extraer los datos requeridos del código HTML
- Almacene la información en un marco de datos de pandas
- Agregue un retraso entre las solicitudes para evitar abrumar el sitio web con solicitudes
Aquí está el código de Python para raspar las películas mejor calificadas de IMDb:
import requests
from bs4 import BeautifulSoup
import pandas as pd
import time
# URL of the website to scrape
url = "https://www.imdb.com/chart/top"
# Send an HTTP GET request to the website
response = requests.get(url)
# Parse the HTML code using BeautifulSoup
soup = BeautifulSoup(response.content, 'html.parser')
# Extract the relevant information from the HTML code
movies = []
for row in soup.select('tbody.lister-list tr'):
title = row.find('td', class_='titleColumn').find('a').get_text()
year = row.find('td', class_='titleColumn').find('span', class_='secondaryInfo').get_text()[1:-1]
rating = row.find('td', class_='ratingColumn imdbRating').find('strong').get_text()
movies.append([title, year, rating])
# Store the information in a pandas dataframe
df = pd.DataFrame(movies, columns=['Title', 'Year', 'Rating'])
# Add a delay between requests to avoid overwhelming the website with requests
time.sleep(1)Paso 5: exportar los datos extraídos
Ahora, exportemos los datos como un archivo CSV. Usaremos la biblioteca pandas.
# Export the data to a CSV file
df.to_csv('top-rated-movies.csv', index=False)Paso 6: Verifique los datos extraídos
Abra el archivo CSV para verificar que los datos se hayan extraído y almacenado correctamente.
Esperamos que este tutorial lo ayude a extraer datos de páginas web fácilmente.
Extraiga texto de cualquier página web con un solo clic. Diríjase al raspador del sitio web de Nanonets, agregue la URL y haga clic en “Raspar” y descargue el texto de la página web como un archivo al instante. Pruébelo gratis ahora.
¿Cómo analizar el texto del sitio web?
Puede analizar fácilmente el texto del sitio web usando BeautifulSoup o lxml. Aquí están los pasos involucrados junto con el código.
- Enviaremos una solicitud HTTP a la URL y obtendremos el contenido HTML de la página web.
- Una vez que tenga la estructura HTMl, usaremos el método find() de BeautifulSoup para ubicar una etiqueta o atributo HTML específico.
- Y luego extraiga el contenido del texto con el atributo de texto.
Aquí hay un código de cómo analizar texto de un sitio web usando BeautifulSoup:
import requests
from bs4 import BeautifulSoup
# Send an HTTP request to the URL of the webpage you want to access
response = requests.get("https://www.example.com")
# Parse the HTML content using BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Extract the text content of the webpage
text = soup.get_text()
print(text)¿Cómo raspar formularios HTML usando Python?
Para raspar formularios HTML usando Python, puede usar una biblioteca como BeautifulSoup, lxml o mechanize. Estos son los pasos generales:
- Envíe una solicitud HTTP a la URL de la página web con el formulario que desea raspar. El servidor responde a la solicitud devolviendo el contenido HTML de la página web.
- Una vez que haya accedido al contenido HTML, puede usar un analizador HTML para ubicar el formulario que desea raspar. Por ejemplo, puede usar el método find() de BeautifulSoup para ubicar la etiqueta del formulario.
- Una vez que haya localizado el formulario, puede extraer los campos de entrada y sus valores correspondientes utilizando el analizador HTML. Por ejemplo, puede usar el método find_all() de BeautifulSoup para ubicar todas las etiquetas de entrada dentro del formulario y luego extraer sus atributos de nombre y valor.
- A continuación, puede utilizar estos datos para enviar el formulario o realizar un procesamiento de datos adicional.
Aquí hay un ejemplo de cómo raspar un formulario HTML usando Mechanize:
import mechanize
# Create a mechanize browser object
browser = mechanize.Browser()
# Send an HTTP request to the URL of the webpage with the form you want to scrape
browser.open("https://www.example.com/form")
# Select the form to scrape
browser.select_form(nr=0)
# Extract the input fields and their corresponding values
for control in browser.form.controls:
print(control.name, control.value)
# Submit the form
browser.submit()Extraiga texto de cualquier página web con un solo clic. Diríjase al raspador del sitio web de Nanonets, agregue la URL y haga clic en “Raspar” y descargue el texto de la página web como un archivo al instante. Pruébelo gratis ahora.
Comparación de todas las bibliotecas de web scraping de Python
Comparemos todas las bibliotecas de raspado web de Python. Todos ellos cuentan con un excelente soporte de la comunidad, pero difieren en la facilidad de uso y sus casos de uso, como se menciona al comienzo del blog.
Conclusión
Python es una excelente opción para extraer datos de sitios web en tiempo real. Otra alternativa es utilizar herramientas automatizadas de extracción de sitios web como Nanonets. Puede utilizar la herramienta gratuita de texto a sitio web. Pero, si necesita automatizar el web scraping para proyectos más grandes, puede comunicarse con Nanonets.
Extraiga texto de cualquier página web con un solo clic. Diríjase al raspador del sitio web de Nanonets, agregue la URL y haga clic en “Raspar” y descargue el texto de la página web como un archivo al instante. Pruébelo gratis ahora.
preguntas frecuentes
¿Cómo usar el analizador HTML para raspado web usando Python?
Para usar un analizador HTML para web scraping en Python, puede usar una biblioteca como BeautifulSoup o lxml. Estos son los pasos generales:
- Envía una solicitud HTTP a la URL de la página web a la que deseas acceder. El servidor responde a la solicitud devolviendo el contenido HTML de la página web.
- Una vez que haya accedido al contenido HTML, puede usar un analizador HTML para extraer los datos que necesita. Por ejemplo, puede usar el método find() de BeautifulSoup para ubicar una etiqueta o atributo HTML específico y luego extraer el contenido del texto con el atributo de texto.
Aquí hay un ejemplo de cómo usar BeautifulSoup para web scraping:
pitón
solicitudes de importación
de bs4 importar BeautifulSoup
# Enviar una solicitud HTTP a la URL de la página web a la que desea acceder
respuesta = solicitudes.get(“https://www.ejemplo.com”)
# Analizar el contenido HTML usando BeautifulSoup
sopa = BeautifulSoup(response.content, “html.parser”)
# Extraer datos específicos de la página web
título = sopa.título
imprimir (título)
En este ejemplo, usamos BeautifulSoup para analizar el contenido HTML de la página web y extraer el título de la página usando el atributo de título.
¿Por qué se usa Web Scraping?
El raspado web se utiliza para raspar datos de sitios web utilizando herramientas o scripts automatizados. Se puede utilizar para múltiples propósitos.
- Extraer datos de varias páginas web y agregar los datos para realizar más análisis.
- Obtención de tendencias mediante el raspado de datos en tiempo real en varias marcas de tiempo.
- Seguimiento de las tendencias de precios de la competencia.
- Generación de clientes potenciales extrayendo correos electrónicos de sitios web.
Raspado web que solía extraer datos estructurados de sitios web HTML no estructurados. El web scraping implica el uso de herramientas o scripts automatizados de web scraping para analizar páginas web complejas.
El web scraping es legal cuando intenta analizar datos disponibles públicamente en un sitio web. En general, el web scraping para uso personal o con fines no comerciales es legal. Sin embargo, el raspado de datos que están protegidos por derechos de autor o que se consideran confidenciales o privados puede generar problemas legales.
En algunos casos, el web scraping puede violar los términos de servicio de un sitio web. Muchos sitios web incluyen términos que prohíben el raspado automático de su contenido. Si el propietario de un sitio web descubre que alguien está raspando su contenido, puede emprender acciones legales para detenerlo.
¿Por qué Python es bueno para el web scraping?
Python es un lenguaje de programación popular para web scraping porque ofrece varias ventajas:
- Python tiene una sintaxis simple y legible y es fácil de aprender para los principiantes.
- Python tiene una gran comunidad de desarrolladores que desarrollan herramientas para diversas tareas, como el web scraping.
- Python tiene muchas bibliotecas de web scraping como Beautiful Soup y Scrapy.
- Python puede realizar muchas tareas como raspar, extraer datos del sitio web para sobresalir, interactuar con formularios HTML y más.
- Python es escalable, lo que lo hace adecuado para raspar grandes volúmenes de datos.
¿Cuál es un ejemplo de web scraping?
El raspado web extrae datos de páginas web utilizando scripts o herramientas automatizados. Por ejemplo, el raspado web se usa para raspar correos electrónicos de sitios web para la generación de clientes potenciales. Otro ejemplo de web scraping es extraer información de precios de la competencia para mejorar su estructura de precios.
¿El web scraping necesita codificación?
Web scraping convierte datos de sitios web no estructurados en un formato estructurado. Además de usar codificación para raspar sitios web, puede usar herramientas de raspado web completamente sin código que no requieren codificación en absoluto.






{kind=link}