 NEWSLETTER
NEWSLETTER
Los modelos de difusión de texto a imagen han logrado avances significativos en la generación de imágenes complejas y fieles a partir de las condiciones de entrada. Entre ellos, los modelos de transformadores de difusión (DiTs) han surgido como particularmente poderosos, siendo SoRA de OpenAI una aplicación notable. Los DiTs, construidos apilando múltiples bloques de transformadores, utilizan las propiedades de escala de los transformadores para lograr un rendimiento mejorado a través de una expansión flexible de parámetros. Si bien los DiTs superan a los modelos de difusión basados en UNet en calidad de imagen, enfrentan desafíos de implementación debido a su gran cantidad de parámetros y alta complejidad computacional. Por ejemplo, generar una imagen con una resolución de 256 × 256 utilizando el modelo DiT XL/2 requiere más de 17 segundos y 105 Gflops en una GPU NVIDIA A100. Esta demanda computacional hace que la implementación de DiTs en dispositivos de borde con recursos limitados sea poco práctica, lo que impulsa a los investigadores a explorar métodos de implementación eficientes, en particular a través de la cuantificación de modelos.
VQ4DiT: cuantificación vectorial post-entrenamiento eficiente para transformadores de difusión
Los modelos de difusión de texto a imagen han logrado avances significativos en la generación de imágenes complejas y fieles a partir de las condiciones de entrada. Entre ellos, los modelos de transformadores de difusión (DiTs) han surgido como particularmente poderosos, siendo SoRA de OpenAI una aplicación notable. Los DiTs, construidos apilando múltiples bloques de transformadores, utilizan las propiedades de escala de los transformadores para lograr un rendimiento mejorado a través de una expansión flexible de parámetros. Si bien los DiTs superan a los modelos de difusión basados en UNet en calidad de imagen, enfrentan desafíos de implementación debido a su gran cantidad de parámetros y alta complejidad computacional. Por ejemplo, generar una imagen con una resolución de 256 × 256 utilizando el modelo DiT XL/2 requiere más de 17 segundos y 105 Gflops en una GPU NVIDIA A100. Esta demanda computacional hace que la implementación de DiTs en dispositivos de borde con recursos limitados sea poco práctica, lo que impulsa a los investigadores a explorar métodos de implementación eficientes, en particular a través de la cuantificación de modelos.
Los intentos anteriores de abordar los desafíos de implementación de los modelos de difusión se han centrado principalmente en las técnicas de cuantificación de modelos. La cuantificación posterior al entrenamiento (PTQ) se ha utilizado ampliamente debido a su rápida implementación sin un ajuste fino extenso. La cuantificación vectorial (VQ) ha demostrado ser prometedora en la compresión de modelos CNN a anchos de bits extremadamente bajos. Sin embargo, estos métodos enfrentan limitaciones cuando se aplican a DiT. Los métodos PTQ reducen significativamente la precisión del modelo en anchos de bits muy bajos, como la cuantificación de 2 bits. Los métodos VQ tradicionales solo calibran el libro de códigos sin ajustar las asignaciones, lo que conduce a resultados subóptimos debido a la asignación incorrecta de subvectores de peso y gradientes inconsistentes en el libro de códigos.
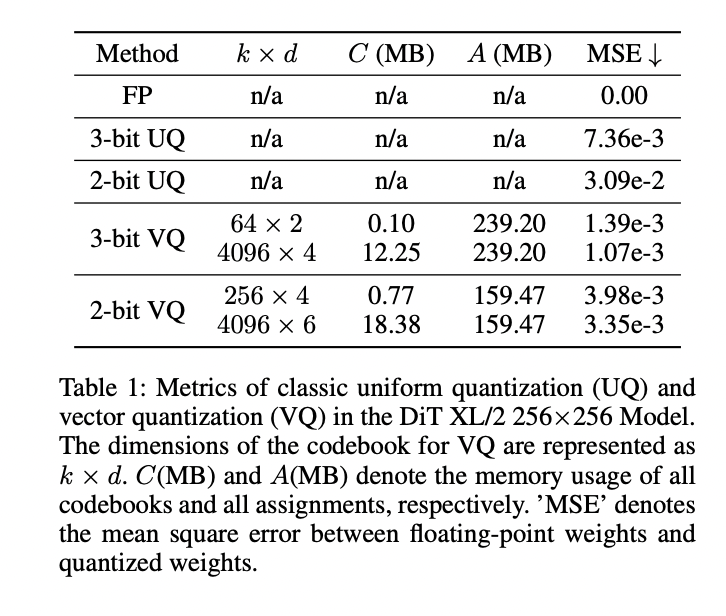
La aplicación de la cuantificación uniforme clásica (UQ) y VQ al modelo DiT XL/2 revela desafíos significativos para lograr un rendimiento óptimo con anchos de bits extremadamente bajos. Si bien VQ supera a UQ en términos de error de cuantificación, aún enfrenta problemas con la degradación del rendimiento, especialmente en niveles de cuantificación de 2 y 3 bits. El equilibrio entre el tamaño del libro de códigos, el uso de memoria y el error de cuantificación presenta un problema de optimización complejo. El ajuste fino de DiT cuantificados en grandes conjuntos de datos como ImageNet es computacionalmente intensivo y consume mucho tiempo. Además, la acumulación de errores de cuantificación en estos modelos a gran escala conduce a resultados subóptimos, incluso después del ajuste fino. El problema clave radica en los gradientes conflictivos para los subvectores con la misma asignación, lo que dificulta las actualizaciones adecuadas de las palabras de código.
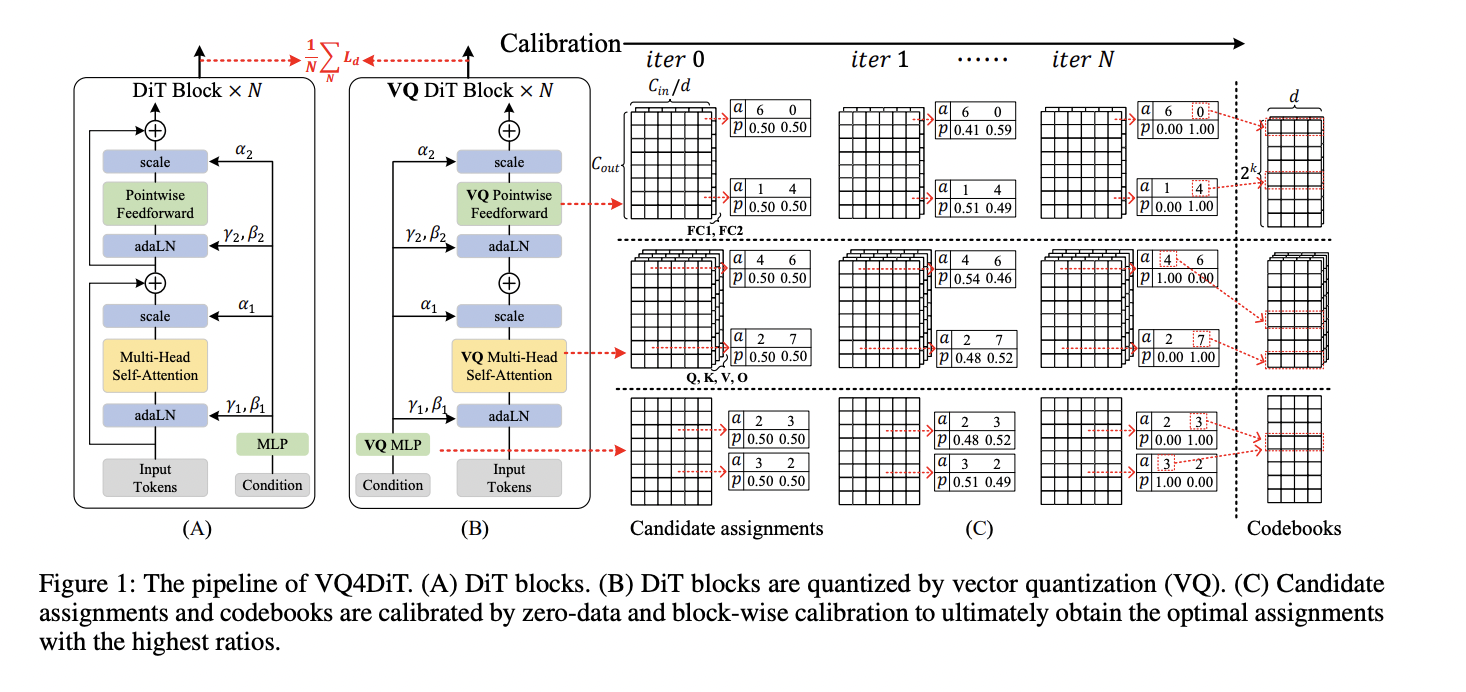
Para superar las limitaciones de los métodos de cuantificación existentes, los investigadores de la Universidad de Zhejiang y vivo Mobile Communication Co., Ltd han desarrollado un Post-Entrenamiento Eficiente. Cuantización vectorial para transformadores de difusión (VQ4DiT). Este enfoque robusto cuantifica de forma eficiente y precisa los DiT sin necesidad de un conjunto de datos de calibración. VQ4DiT descompone los pesos de cada capa en un libro de códigos y conjuntos de asignaciones candidatas, inicializando cada asignación candidata con una proporción igual. Luego, emplea una estrategia de calibración de datos cero y por bloques para calibrar simultáneamente los libros de códigos y los conjuntos de asignaciones candidatas. Este método minimiza el error cuadrático medio entre las salidas de los modelos de punto flotante y cuantificados en cada paso de tiempo y bloque DiT, lo que garantiza que el modelo cuantificado mantenga un rendimiento similar al de su contraparte de punto flotante y, al mismo tiempo, evita el colapso de la calibración debido a errores de cuantificación acumulativos.

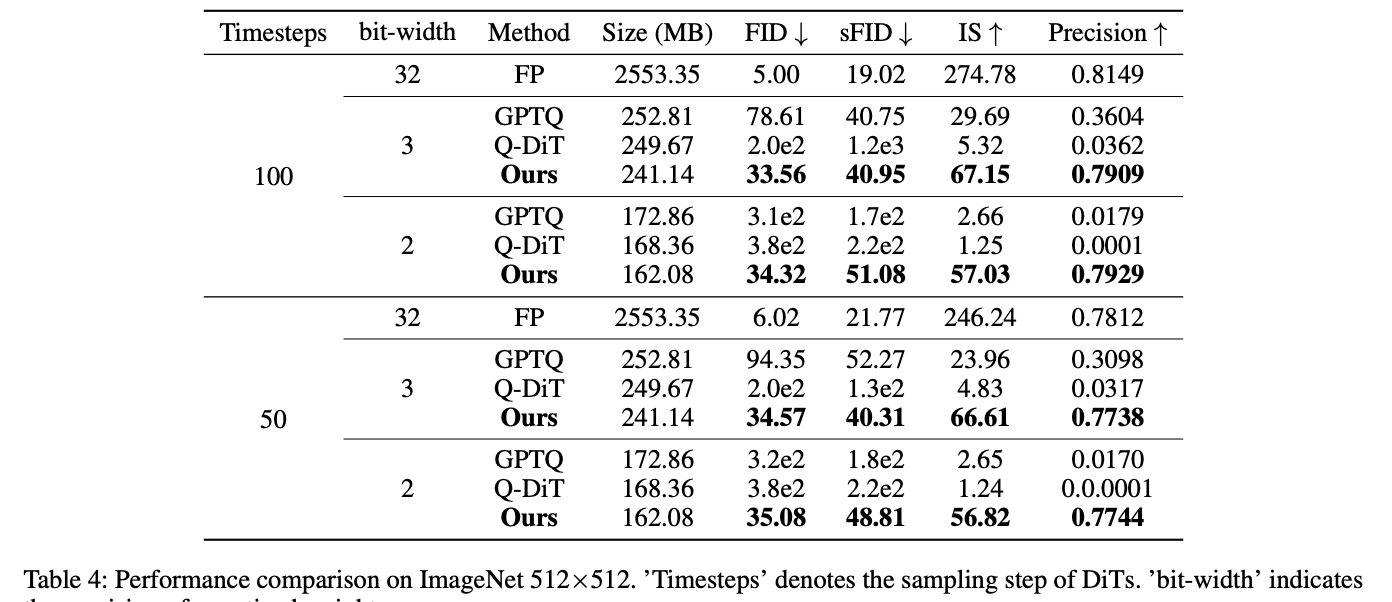
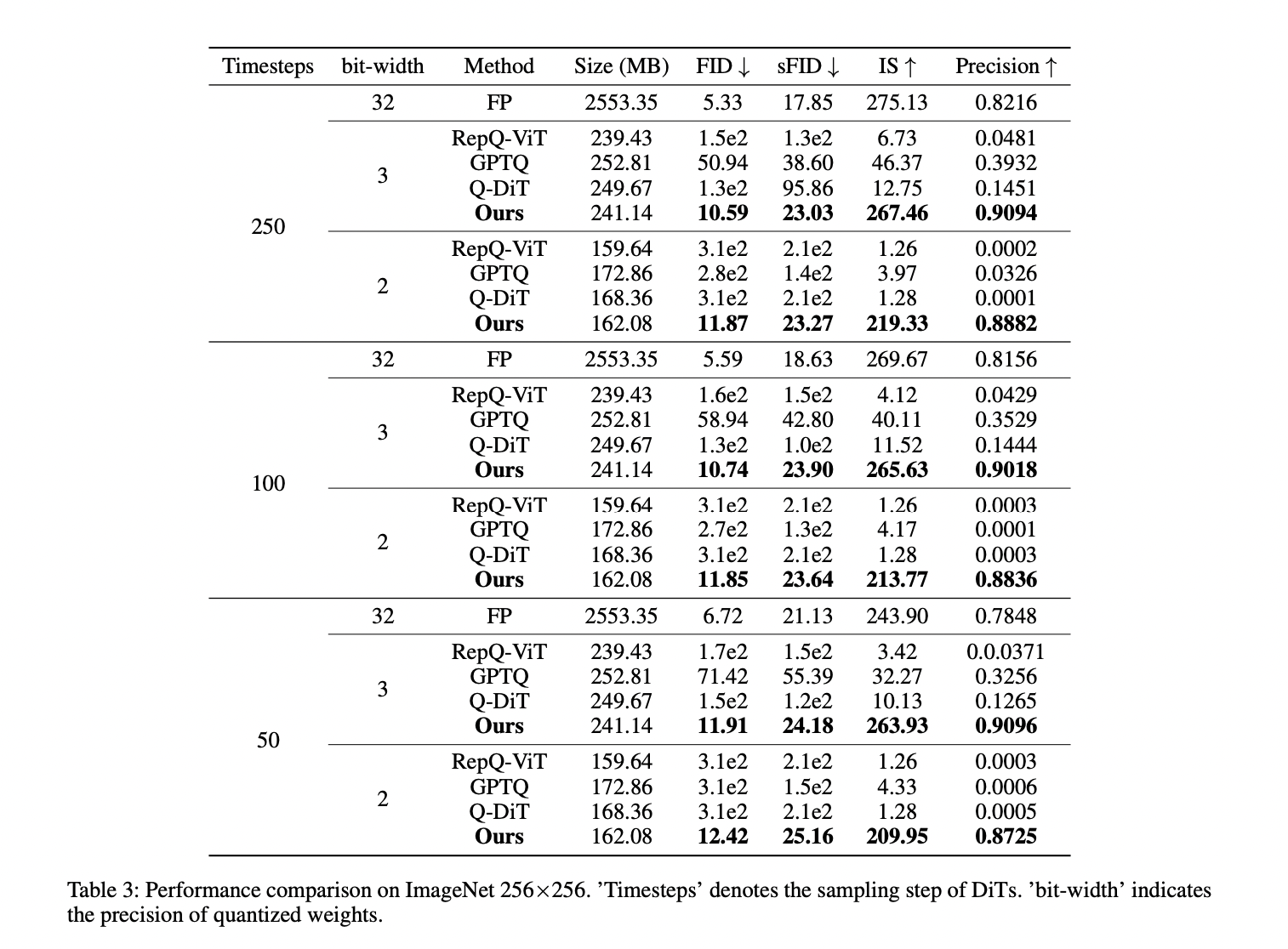
El modelo DiT XL/2, cuantificado con VQ4DiT, demuestra un rendimiento superior en conjuntos de datos ImageNet de 256×256 y 512×512 en varios intervalos de tiempo de muestra y anchos de bits de ponderación. Con una resolución de 256×256, VQ4DiT supera a otros métodos, incluidos RepQ-ViT, GPTQ y Q-DiT, especialmente con una cuantificación de 3 bits. VQ4DiT mantiene un rendimiento cercano al modelo de punto flotante, con aumentos mínimos en FID y disminuciones en IS. Con una cuantificación de 2 bits, donde otros algoritmos colapsan, VQ4DiT continúa generando imágenes de alta calidad con solo una ligera disminución en la precisión. Se observan resultados similares con una resolución de 512×512, lo que indica la capacidad de VQ4DiT para producir imágenes de alta calidad y alta resolución con un uso mínimo de memoria, lo que lo hace ideal para implementar DiT en dispositivos de borde.
Este estudio presenta VQ4DiTun método de cuantificación vectorial post-entrenamiento único y robusto para DiTs, que aborda desafíos clave en la cuantificación eficiente. Al equilibrar el tamaño del libro de códigos con el error de cuantificación y resolver direcciones de gradiente inconsistentes, VQ4DiT logra asignaciones y libros de códigos óptimos a través de un proceso de calibración de bloque y de datos cero. Este enfoque innovador calcula conjuntos de asignaciones candidatas para cada subvector y calibra progresivamente el libro de códigos y las asignaciones de cada capa. Los resultados experimentales demuestran la efectividad de VQ4DiT en la cuantificación de pesos de DiT con una precisión de 2 bits mientras se preservan las capacidades de generación de imágenes de alta calidad. Este avance mejora significativamente el potencial para implementar DiTs en dispositivos de borde con recursos limitados, abriendo nuevas posibilidades para la generación de imágenes eficiente y de alta calidad en varias aplicaciones.
Los intentos anteriores de abordar los desafíos de implementación de los modelos de difusión se han centrado principalmente en las técnicas de cuantificación de modelos. La cuantificación posterior al entrenamiento (PTQ) se ha utilizado ampliamente debido a su rápida implementación sin un ajuste fino extenso. La cuantificación vectorial (VQ) ha demostrado ser prometedora en la compresión de modelos CNN a anchos de bits extremadamente bajos. Sin embargo, estos métodos enfrentan limitaciones cuando se aplican a DiT. Los métodos PTQ reducen significativamente la precisión del modelo en anchos de bits muy bajos, como la cuantificación de 2 bits. Los métodos VQ tradicionales solo calibran el libro de códigos sin ajustar las asignaciones, lo que conduce a resultados subóptimos debido a la asignación incorrecta de subvectores de peso y gradientes inconsistentes en el libro de códigos.
La aplicación de la cuantificación uniforme clásica (UQ) y VQ al modelo DiT XL/2 revela desafíos significativos para lograr un rendimiento óptimo con anchos de bits extremadamente bajos. Si bien VQ supera a UQ en términos de error de cuantificación, aún enfrenta problemas con la degradación del rendimiento, especialmente en niveles de cuantificación de 2 y 3 bits. El equilibrio entre el tamaño del libro de códigos, el uso de memoria y el error de cuantificación presenta un problema de optimización complejo. El ajuste fino de DiT cuantificados en grandes conjuntos de datos como ImageNet es computacionalmente intensivo y consume mucho tiempo. Además, la acumulación de errores de cuantificación en estos modelos a gran escala conduce a resultados subóptimos, incluso después del ajuste fino. El problema clave radica en los gradientes conflictivos para los subvectores con la misma asignación, lo que dificulta las actualizaciones adecuadas de las palabras de código.
Para superar las limitaciones de los métodos de cuantificación existentes, los investigadores de la Universidad de Zhejiang y vivo Mobile Communication Co., Ltd han desarrollado un Post-Entrenamiento Eficiente. Cuantización vectorial para transformadores de difusión (VQ4DiT). Este enfoque robusto cuantifica de forma eficiente y precisa los DiT sin necesidad de un conjunto de datos de calibración. VQ4DiT descompone los pesos de cada capa en un libro de códigos y conjuntos de asignaciones candidatas, inicializando cada asignación candidata con una proporción igual. Luego, emplea una estrategia de calibración de datos cero y por bloques para calibrar simultáneamente los libros de códigos y los conjuntos de asignaciones candidatas. Este método minimiza el error cuadrático medio entre las salidas de los modelos de punto flotante y cuantificados en cada paso de tiempo y bloque DiT, lo que garantiza que el modelo cuantificado mantenga un rendimiento similar al de su contraparte de punto flotante y, al mismo tiempo, evita el colapso de la calibración debido a errores de cuantificación acumulativos.
El modelo DiT XL/2, cuantificado con VQ4DiT, demuestra un rendimiento superior en conjuntos de datos ImageNet de 256×256 y 512×512 en varios intervalos de tiempo de muestra y anchos de bits de ponderación. Con una resolución de 256×256, VQ4DiT supera a otros métodos, incluidos RepQ-ViT, GPTQ y Q-DiT, especialmente con una cuantificación de 3 bits. VQ4DiT mantiene un rendimiento cercano al modelo de punto flotante, con aumentos mínimos en FID y disminuciones en IS. Con una cuantificación de 2 bits, donde otros algoritmos colapsan, VQ4DiT continúa generando imágenes de alta calidad con solo una ligera disminución en la precisión. Se observan resultados similares con una resolución de 512×512, lo que indica la capacidad de VQ4DiT para producir imágenes de alta calidad y alta resolución con un uso mínimo de memoria, lo que lo hace ideal para implementar DiT en dispositivos de borde.
Este estudio presenta VQ4DiTun método de cuantificación vectorial post-entrenamiento único y robusto para DiTs, que aborda desafíos clave en la cuantificación eficiente. Al equilibrar el tamaño del libro de códigos con el error de cuantificación y resolver direcciones de gradiente inconsistentes, VQ4DiT logra asignaciones y libros de códigos óptimos a través de un proceso de calibración de bloque y de datos cero. Este enfoque innovador calcula conjuntos de asignaciones candidatas para cada subvector y calibra progresivamente el libro de códigos y las asignaciones de cada capa. Los resultados experimentales demuestran la efectividad de VQ4DiT en la cuantificación de pesos de DiT con una precisión de 2 bits mientras se preservan las capacidades de generación de imágenes de alta calidad. Este avance mejora significativamente el potencial para implementar DiTs en dispositivos de borde con recursos limitados, abriendo nuevas posibilidades para la generación de imágenes eficiente y de alta calidad en varias aplicaciones.
Echa un vistazo a la Papel. Todo el crédito por esta investigación corresponde a los investigadores de este proyecto. Además, no olvides seguirnos en twitter.com/Marktechpost”>Gorjeo y LinkedInÚnete a nuestro Canal de Telegram.
Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro SubReddit de más de 50.000 ml
Asjad es consultor en prácticas en Marktechpost. Está cursando la licenciatura en ingeniería mecánica en el Instituto Indio de Tecnología de Kharagpur. Asjad es un entusiasta del aprendizaje automático y del aprendizaje profundo que siempre está investigando las aplicaciones del aprendizaje automático en el ámbito de la atención médica.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}