 NEWSLETTER
NEWSLETTER
The development of multimodal large language models (MLLM) has provided new opportunities in artificial intelligence. However, significant challenges remain in the integration of visual, linguistic, and speech modalities. While many MLLMs work well with vision and text, incorporating speech remains a hurdle. Speech, a natural medium for human interaction, plays an essential role in dialogue systems, however, differences between modalities (spatial versus temporal data representations) create conflicts during training. Traditional systems that rely on separate automatic speech recognition (ASR) and text-to-speech (TTS) modules are often slow and impractical for real-time applications.
Researchers from NJU, Tencent Youtu Lab, XMU and CASIA have introduced VITA-1.5, a large multimodal language model that integrates vision, language and speech through a carefully designed three-stage training methodology. Unlike its predecessor, VITA-1.0, which relied on external TTS modules, VITA-1.5 employs an end-to-end framework, reducing latency and streamlining interaction. The model incorporates vision and speech encoders along with a speech decoder, allowing for near real-time interactions. Through progressive multimodal training, it addresses conflicts between modalities while maintaining performance. Researchers have also made training and inference code available to the public, encouraging innovation in the field.
Technical details and benefits
VITA-1.5 is designed to balance efficiency and capacity. It uses vision and audio encoders, employing dynamic patching for image inputs and downsampling techniques for audio. The speech decoder combines non-autoregressive (NAR) and auto-regressive (AR) methods to ensure smooth and high-quality speech generation. The training process is divided into three stages:
- Vision-Language Training: This stage focuses on vision alignment and understanding, using descriptive captions and visual question answering (QA) tasks to establish a connection between visual and linguistic modalities.
- Audio input tuning: The audio encoder is aligned to the language model using speech transcription data, enabling effective audio input processing.
- Audio output tuning: The speech decoder is trained with paired text-speech data, enabling coherent speech outputs and seamless speech-to-speech interactions.
These strategies effectively address modality conflicts, allowing VITA-1.5 to handle image, video, and voice data seamlessly. The integrated approach improves its usability in real time, eliminating common bottlenecks in traditional systems.
Results and insights
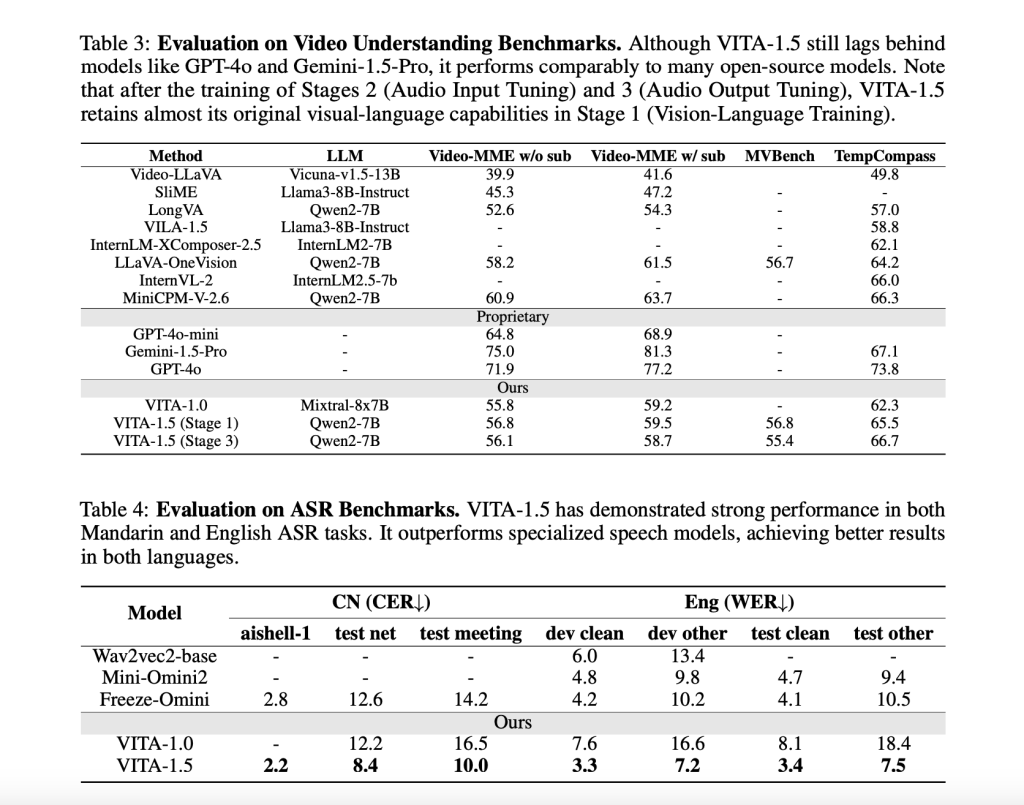
Evaluations of VITA-1.5 on various benchmarks demonstrate its strong capabilities. The model performs competitively on image and video understanding tasks, achieving results comparable to leading open source models. For example, on benchmarks like MMBench and MMStar, the VITA-1.5's vision and language capabilities are on par with proprietary models like GPT-4V. Additionally, it excels in speaking tasks, achieving low character error rates (CER) in Mandarin and word error rates (WER) in English. Importantly, the inclusion of audio processing does not compromise your visual reasoning abilities. The model's consistent performance across modalities highlights its potential for practical applications.
Conclusion
VITA-1.5 represents a thoughtful approach to solving the challenges of multimodal integration. By addressing conflicts between vision, language and speech modalities, it offers a coherent and efficient solution for real-time interactions. Its open source availability ensures that researchers and developers can leverage its foundations, advancing the field of multimodal ai. VITA-1.5 not only enhances current capabilities but also points toward a more integrated and interactive future for ai systems.
Verify he Paper and GitHub page. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on <a target="_blank" href="https://twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. Don't forget to join our SubReddit over 60,000 ml.
UPCOMING FREE ai WEBINAR (JANUARY 15, 2025): <a target="_blank" href="https://info.gretel.ai/boost-llm-accuracy-with-sd-and-evaluation-intelligence?utm_source=marktechpost&utm_medium=newsletter&utm_campaign=202501_gretel_galileo_webinar”>Increase LLM Accuracy with Synthetic Data and Assessment Intelligence–<a target="_blank" href="https://info.gretel.ai/boost-llm-accuracy-with-sd-and-evaluation-intelligence?utm_source=marktechpost&utm_medium=newsletter&utm_campaign=202501_gretel_galileo_webinar”>Join this webinar to learn practical information to improve LLM model performance and accuracy while protecting data privacy..
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his dual degree from the Indian Institute of technology Kharagpur. He is passionate about data science and machine learning, and brings a strong academic background and practical experience solving real-life interdisciplinary challenges.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}