 NEWSLETTER
NEWSLETTER
The field of information retrieval has evolved rapidly due to the exponential growth of digital data. With the increasing volume of unstructured data, efficient methods for searching and retrieving relevant information have become more crucial than ever. Traditional keyword-based search techniques often need to capture the nuanced meaning of text, resulting in inaccurate or irrelevant search results. This problem becomes more pronounced with complex data sets that span multiple media types, such as text, images, and videos. The widespread adoption of smart devices and social platforms has further contributed to this increase in data, and estimates suggest that unstructured data could make up 80% of the total data volume by 2025. As such, there is a critical need for methodologies solid ones that can transform this data into meaningful knowledge.
One of the main challenges in information retrieval is dealing with the high dimensionality and dynamic nature of modern data sets. Existing techniques often need help to provide scalable and efficient solutions to handle multi-vector queries or integrate real-time updates. This is particularly problematic for applications that require rapid retrieval of contextually relevant results, such as recommender systems and large-scale search engines. While some progress has been made in improving retrieval mechanisms using latent semantic analysis (LSA) and deep learning models, these methods have yet to address semantic gaps between queries and documents.
Current information retrieval systems, such as Milvus, have attempted to provide support for large-scale vector data management. However, these systems are hampered by their reliance on static data sets and lack of flexibility to handle complex multi-vector queries. Traditional algorithms and libraries often rely heavily on main memory storage and cannot distribute data across multiple machines, limiting their scalability. This restricts its adaptability to real-world scenarios where data is constantly changing. As a result, existing solutions struggle to provide the accuracy and efficiency needed for dynamic environments.
The research team from the University of Washington presented Vector searcha novel document retrieval framework designed to address these limitations. VectorSearch integrates advanced language models, hybrid indexing techniques, and multi-vector query handling mechanisms to significantly improve retrieval accuracy and scalability. By leveraging both vector embeddings and traditional indexing methods, VectorSearch can efficiently manage large-scale data sets, making it a powerful tool for complex search operations. The framework incorporates optimized caching mechanisms and lookup algorithms, improving response times and overall performance. These capabilities differentiate it from conventional systems and offer a comprehensive solution for document recovery.
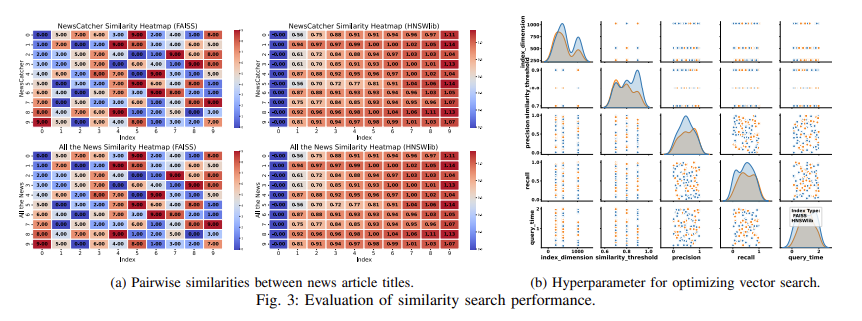
VectorSearch operates as a hybrid system that combines the strengths of multiple indexing techniques, such as FAISS for distributed indexing and HNSWlib for hierarchical search optimization. This approach enables seamless management of large-scale data sets across multiple machines. Furthermore, it introduces novel algorithms for multivector search, encoding documents in high-dimensional embeddings that capture semantic relationships between different data. Integrating these embeddings into a vector database allows the system to retrieve relevant documents based on user queries efficiently. Experiments on real-world datasets show that VectorSearch outperforms existing systems, with a recall rate of 76.62% and a precision rate of 98.68% at an index dimension of 1024.
VectorSearch performance evaluation revealed significant improvements in several metrics. The system achieved an average query time of 0.47 seconds when using the BERT-based boxless model and the FAISS indexing technique, which is significantly faster than traditional retrieval systems. This reduction in query time is attributed to the innovative use of hierarchical indexing and multi-vector query handling. Furthermore, the proposed framework supports real-time updates, allowing it to handle dynamically evolving datasets without extensive reindexing. These improvements make VectorSearch a versatile solution for applications ranging from web search engines to recommendation systems.
Key findings from the research include:
- High precision and recall: VectorSearch achieved a recall rate of 76.62% and a precision rate of 98.68% when using an index dimension of 1024, outperforming baseline models on several retrieval tasks.
- Reduced consultation time: The system significantly reduced query time, achieving an average of 0.47 seconds for high-dimensional data retrieval.
- Scalability: By integrating FAISS and HNSWlib, VectorSearch efficiently handles evolving and large-scale data sets, making it suitable for real-time applications.
- Support for dynamic data: The framework supports real-time updates, allowing you to maintain high performance even when data changes.

In conclusion, VectorSearch presents a solid solution to the challenges faced by existing information retrieval systems. By introducing a scalable and adaptable approach, the research team has created a framework that meets the demands of modern data-intensive applications. The integration of hybrid indexing techniques, multi-vector search operations, and advanced language models results in significant improvement in retrieval accuracy and efficiency. This research paves the way for future advances in the field and offers valuable insights into the development of next-generation document retrieval systems.
look at the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. If you like our work, you will love our information sheet..
Don't forget to join our SubReddit over 50,000ml.
We are inviting startups, companies and research institutions that are working on small language models to participate in this next Magazine/Report 'Small Language Models' by Marketchpost.com. This magazine/report will be published in late October/early November 2024. Click here to schedule a call!
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for social good. Their most recent endeavor is the launch of an ai media platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easily understandable to a wide audience. The platform has more than 2 million monthly visits, which illustrates its popularity among the public.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}