 NEWSLETTER
NEWSLETTER
In February 2024, Reddit reached a $ 60 million agreement with Google to allow the search giant to use data on the platform to train its artificial intelligence models. Notably absent from the discussions were Reddit users, whose data were sold.
The agreement reflected the reality of the modern Internet: large –technology companies have practically all our online data and will decide what to do with that data. As expected, many platforms monetize their data, and the fastest growing way of achieving it today is to sell it to ai companies, which are massive technological companies that use the data to train increasingly powerful models.
The vain decentralized platform, which began as a class project at the MIT, has the mission of returning power to users. The company has created a fully owned network of the user that allows people to load their data and govern how they are used. IA developers can present users of ideas for new models, and if users agree to contribute their training data, they obtain a proportional property in the models.
The idea is to give everyone a participation in artificial intelligence systems that will give our society more and more form and at the same time unlock new data groups to advance technology.
“These data are necessary to create better ai systems,” says Vana co -founder, Anna Kazlauskas '19. “We have created a decentralized system to obtain better data, which are within large technological companies today, while allowing users to retain maximum property.”
From economics to the block chain
Many high school students have photos of pop stars or athletes on the walls of their room. Kazlauskas had a photo of former United States Treasury Secretary, Janet Yellen.
Kazlauskas arrived at Mit probably becoming an economist, but ended up being one of the five students to join the Mitcoin Club in 2015, and that experience took her to the world of block chains and cryptocurrency.
From his bedroom in MacGregor House, he began to extract the ethhereum from the cryptocurrency. Even occasionally he toured the garbage containers of the campus in search of discarded computer chips.
“I was interested in everything related to computer science and networks,” says Kazlauskas. “That involved, from a blockchain perspective, distributed systems and how they can change economic power to people, as well as artificial intelligence and the economy.”
Kazlauskas met Art Abal, who later attended Harvard University, in the old emerging companies of the media laboratory class, and the couple decided to work in new ways to obtain data to train ai systems.
“Our question was: how could a lot of people contribute to these ai systems using a distributed network?” Kazlauskas remembers.
Kazlauskas and Abal were trying to address the status quo, where most models are trained by scraping public data on the Internet. Large technological companies also buy large data sets from other companies.
The founders approach evolved over the years and was informed by Kazlauskas's experience working in the Blockchain Financial Company zeal after graduation. But Kazlauskas accredits her time at MIT for helping her to think about these problems, and the instructor of emerging companies, Ramesh Raskar, still helps vain to think about the research questions of today.
“It was great to have an open opportunity to build, hack and explore,” says Kazlauskas. “I think Ethos in MIT is really important. It's just about building things, seeing what works and continuing it.”
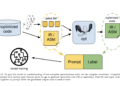
Today, Vana takes advantage of a little known law that allows users of most of the large technological platforms to export their data directly. Users can load that information on digital wallets encrypted in vain and disburse it to train models as they seem better.
IA engineers can suggest ideas for new open source models, and people can group their data to help train the model. In the world of Blockchain, data groups are called Data Daos, which represents a decentralized autonomous organization. Data can also be used to create custom models and agents.
In vain, the data is used in a way that preserves the user's privacy because the system does not expose identifiable information. Once the model is created, users keep the property so that every time it is used, they are rewarded proportionally depending on how much their data helped to train it.
“From the perspective of a developer, you can now build these hyperpersonalized health applications that take into account exactly what he ate, how he slept, how he exercises,” says Kazlauskas. “These applications are not possible today due to those walled gardens of large technological companies.”
ai from Crowdsourced, owned by users
Last year, an automatic learning engineer proposed using vain user data to train an ai model that could generate Reddit publications. More than 140,000 vain users contributed their Reddit data, which contained publications, comments, messages and more. Users decided the terms in which the model could be used, and maintained the property of the model after their creation.
Vana has enabled similar initiatives with data contributed to the user of the social media platform x; Sleep data of sources such as Oura rings; And more. There are also collaborations that combine data groups to create broader ai applications.
“Let's say users have spotify data, Reddit data and fashion data,” Kazlauskas explains. “In general, Spotify will not collaborate with such companies, and in reality there is a regulation against that. But users can do it if they give access, so these multiplatform data sets can be used to create really powerful models.”
Vana has more than 1 million users and more than 20 live data damage. Users have proposed more than 300 additional data groups in the vain system, and Kazlauskas says that many will enter production this year.
“I think there are many promises in generalized ai models, personalized medicine and new consumption applications, because it is difficult to combine all this data or get access to it first,” says Kazlauskas.
Data groups are allowing user groups to achieve something with which even the most powerful technology companies fight today.
“Today, large technology companies have built these data ghosts, so the best data sets are not available to anyone,” says Kazlauskas. “It is a collective action problem, where my data alone is not so valuable, but a group of data with tens of thousands or millions of people is really valuable. Vana allows these groups to be built. It is a profit for benefit: users benefit from the increase in ai because they are owners of the models. Then they do not end in scenarios in which it does not have a single company that controls a company All-Powerful.
(Tagstotranslate) vain network





{kind=link}