 NEWSLETTER
NEWSLETTER
Amazon SageMaker es un servicio de aprendizaje automático (ML) completamente administrado. Con SageMaker, los científicos de datos y los desarrolladores pueden crear y entrenar modelos de aprendizaje automático de forma rápida y sencilla, y luego implementarlos directamente en un entorno alojado listo para la producción. Sagemaker proporciona una instancia de notebook de creación de Jupyter integrada para acceder fácilmente a sus fuentes de datos para exploración y análisis, de modo que no tenga que administrar servidores. También proporciona algoritmos de ML comunes que están optimizados para ejecutarse de manera eficiente contra datos extremadamente grandes en un entorno distribuido.
SageMaker requiere que los datos de entrenamiento para un modelo de ML estén presentes en Amazon Simple Storage Service (Amazon S3), Amazon Elastic File System (Amazon EFS) o Amazon FSx for Lustre (para obtener más información, consulte Acceder a los datos de entrenamiento). Para entrenar un modelo utilizando datos almacenados fuera de los tres servicios de almacenamiento admitidos, primero se deben ingerir los datos en uno de estos servicios (normalmente, Amazon S3). Esto requiere la creación de una canalización de datos (utilizando herramientas como Amazon SageMaker Data Wrangler) para mover datos a Amazon S3. Sin embargo, este enfoque puede crear un desafío de administración de datos en términos de administrar el ciclo de vida de este medio de almacenamiento de datos, diseñar controles de acceso, auditoría de datos, etc., todo con el fin de organizar los datos de capacitación durante la duración del trabajo de capacitación. En tales situaciones, puede ser deseable tener acceso a los datos para SageMaker en los medios de almacenamiento efímero adjuntos a las instancias de capacitación efímeras sin el almacenamiento intermedio de datos en Amazon S3.
Esta publicación muestra una manera de hacer esto usando Copo de nieve como fuente de datos y descargando los datos directamente desde Snowflake a una instancia de trabajo de SageMaker Training.
Descripción general de la solución
usamos el Conjunto de datos de vivienda de California como un conjunto de datos de entrenamiento para esta publicación y entrenar un modelo ML para predecir el valor medio de la casa para cada distrito. Agregamos estos datos a Snowflake como una nueva tabla. Creamos un contenedor de entrenamiento personalizado que descarga datos directamente desde la tabla Snowflake a la instancia de entrenamiento en lugar de descargar primero los datos en un depósito S3. Una vez que los datos se descargan en la instancia de entrenamiento, el script de entrenamiento personalizado realiza tareas de preparación de datos y luego entrena el modelo de ML usando el Estimador XGBoost. Todo el código para esta publicación está disponible en el repositorio de GitHub.
Figura 1: Arquitectura
La siguiente figura representa la arquitectura de alto nivel de la solución propuesta para usar Snowflake como fuente de datos para entrenar modelos ML con SageMaker.
Los pasos del flujo de trabajo son los siguientes:
- Configure un cuaderno de SageMaker y un rol de AWS Identity and Access Management (IAM) con los permisos adecuados para permitir que SageMaker acceda a Amazon Elastic Container Registry (Amazon ECR), Secrets Manager y otros servicios dentro de su cuenta de AWS.
- Almacene las credenciales de su cuenta de Snowflake en AWS Secrets Manager.
- Ingiera los datos en una tabla en su cuenta de Snowflake.
- Cree una imagen de contenedor personalizada para el entrenamiento del modelo ML y envíela a Amazon ECR.
- Inicie un trabajo de capacitación de SageMaker para entrenar el modelo ML. La instancia de entrenamiento recupera las credenciales de Snowflake de Secrets Manager y luego usa estas credenciales para descargar el conjunto de datos directamente de Snowflake. Este es el paso que elimina la necesidad de que los datos se descarguen primero en un depósito S3.
- El modelo de aprendizaje automático entrenado se almacena en un depósito de S3.
requisitos previos
Para implementar la solución provista en esta publicación, debe tener una cuenta de AWS, un cuenta copo de nieve y familiaridad con SageMaker.
Configurar un SageMaker Notebook y un rol de IAM
Usamos AWS CloudFormation para crear un cuaderno SageMaker llamado aws-aiml-blogpost-sagemaker-snowflake-example y un rol de IAM llamado SageMakerSnowFlakeExample. Elegir Pila de lanzamiento para la región en la que desea implementar recursos.
Almacene las credenciales de Snowflake en Secrets Manager
Guarde sus credenciales de Snowflake como un secreto en Secrets Manager. Para obtener instrucciones sobre cómo crear un secreto, consulte Create an AWS Secrets Manager secret.
- Nombra el secreto
snowflake_credentials. Esto es necesario porque el código ensnowflake-load-dataset.ipynbespera que el secreto se llame así. - Cree el secreto como un par clave-valor con dos claves:
- nombre de usuario – Su nombre de usuario de Snowflake.
- contraseña – La contraseña asociada con su nombre de usuario de Snowflake.
Ingerir los datos en una tabla en su cuenta de Snowflake
Para ingerir los datos, complete los siguientes pasos:
- En la consola de SageMaker, elija Cuadernos en el panel de navegación.
- Seleccione el cuaderno aws-aiml-blogpost-sagemaker-snowflake-example y elija Abrir JupyterLab.

Figura 2: Abra JupyterLab
- Elegir
snowflake-load-dataset.ipynbpara abrirlo en JupyterLab. Este cuaderno ingerirá el Conjunto de datos de vivienda de California a una mesa Snowflake. - En el cuaderno, edite el contenido de la siguiente celda para reemplazar los valores del marcador de posición con el que coincida con su cuenta de copo de nieve:
- En el menú Ejecutar, elija Ejecutar todas las celdas para ejecutar el código en este cuaderno. Esto descargará el conjunto de datos localmente en el cuaderno y luego lo incorporará en la tabla Snowflake.
Figura 3: Notebook ejecutar todas las celdas
El siguiente fragmento de código en el cuaderno ingiere el conjunto de datos en Snowflake. Ver el snowflake-load-dataset.ipynb cuaderno para el código completo.
- Cierre el cuaderno después de que todas las celdas se ejecuten sin ningún error. Tus datos ya están disponibles en Snowflake. La siguiente captura de pantalla muestra la
california_housingtabla creada en Snowflake.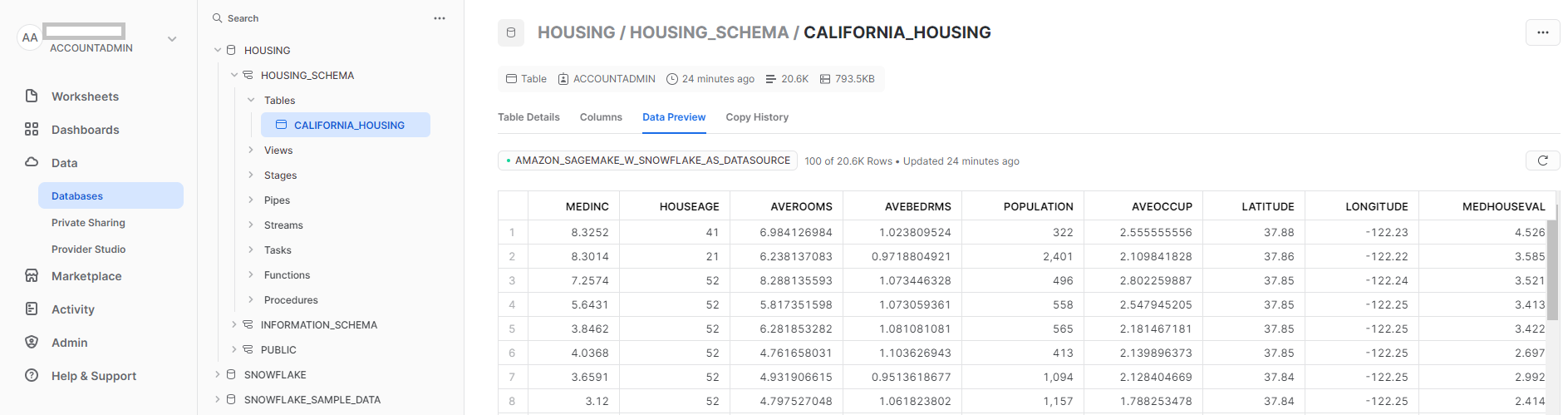
Figura 4: Mesa de copos de nieve
ejecutar el sagemaker-snowflake-example.ipynb computadora portátil
Este cuaderno crea un contenedor de entrenamiento personalizado con una conexión de Snowflake, extrae datos de Snowflake en el almacenamiento efímero de la instancia de entrenamiento sin almacenarlo en Amazon S3 y realiza el entrenamiento del modelo XGBoost de Distributed Data Parallel (DDP) en los datos. El entrenamiento de DDP no es necesario para el entrenamiento de modelos en un conjunto de datos tan pequeño; se incluye aquí para ilustrar otra función de SageMaker lanzada recientemente.
Figura 5: Abra el cuaderno de ejemplo SageMaker Snowflake
Crear un contenedor personalizado para entrenamiento
Ahora creamos un contenedor personalizado para el trabajo de entrenamiento del modelo ML. Tenga en cuenta que se requiere acceso raíz para crear un contenedor Docker. Este cuaderno de SageMaker se implementó con el acceso raíz habilitado. Si las políticas de su organización empresarial no permiten el acceso raíz a los recursos de la nube, es posible que desee utilizar el siguiente archivo de Docker y los scripts de shell para crear un contenedor de Docker en otro lugar (por ejemplo, su computadora portátil) y luego enviarlo a Amazon ECR. Usamos el contenedor basado en la imagen del contenedor SageMaker XGBoost 246618743249.dkr.ecr.us-west-2.amazonaws.com/sagemaker-xgboost:1.5-1 con las siguientes adiciones:
- El Conector de copo de nieve para Python para descargar los datos de la tabla Snowflake a la instancia de entrenamiento.
- Una secuencia de comandos de Python para conectarse a Secrets Manager para recuperar las credenciales de Snowflake.
El uso del conector Snowflake y la secuencia de comandos de Python garantiza que los usuarios que usan esta imagen de contenedor para el entrenamiento del modelo ML no tengan que escribir este código como parte de su secuencia de comandos de entrenamiento y puedan usar esta funcionalidad que ya está disponible para ellos.
El siguiente es el Dockerfile para el contenedor de entrenamiento:
La imagen del contenedor se crea y se envía a Amazon ECR. Esta imagen se usa para entrenar el modelo ML.
Entrene el modelo de ML mediante un trabajo de entrenamiento de SageMaker
Una vez que creamos con éxito la imagen del contenedor y la enviamos a Amazon ECR, podemos comenzar a usarla para el entrenamiento del modelo.
- Creamos un conjunto de scripts de Python para descargar los datos de Snowflake usando el Conector de copo de nieve para Pythonprepare los datos y luego use el
XGBoost Regressorpara entrenar el modelo ML. Es el paso de descargar los datos directamente a la instancia de entrenamiento lo que evita tener que usar Amazon S3 como almacenamiento intermedio para los datos de entrenamiento. - Facilitamos el entrenamiento paralelo de datos distribuidos al hacer que el código de entrenamiento descargue un subconjunto aleatorio de los datos de modo que cada instancia de entrenamiento descargue una cantidad igual de datos de Snowflake. Por ejemplo, si hay dos nodos de entrenamiento, cada nodo descarga una muestra aleatoria del 50 % de las filas de la tabla Snowflake. Consulte el siguiente código:
- Luego proporcionamos el script de capacitación al SDK de SageMaker
Estimatorjunto con el directorio de origen para que todos los scripts que creamos puedan proporcionarse al contenedor de entrenamiento cuando se ejecuta el trabajo de entrenamiento usando elEstimator.fitmétodo:Para obtener más información, consulte Preparar un guión de entrenamiento de Scikit-Learn.
- Después de completar el entrenamiento del modelo, el modelo entrenado está disponible como
model.tar.gzarchivo en el depósito predeterminado de SageMaker para la región:
¡Ahora puede implementar el modelo entrenado para obtener inferencias sobre nuevos datos! Para obtener instrucciones, consulte Crear su punto final e implementar su modelo.
Limpiar
Para evitar incurrir en cargos futuros, elimine los recursos. Puede hacerlo eliminando la plantilla de CloudFormation utilizada para crear el rol de IAM y el cuaderno de SageMaker.

Figura 6: Limpieza
Deberá eliminar los recursos de Snowflake manualmente desde la consola de Snowflake.
Conclusión
En esta publicación, mostramos cómo descargar datos almacenados en una tabla Snowflake a una instancia de trabajo de SageMaker Training y cómo entrenar un modelo XGBoost usando un contenedor de entrenamiento personalizado. Este enfoque nos permite integrar Snowflake directamente como fuente de datos con una computadora portátil SageMaker sin tener los datos almacenados en Amazon S3.
Le animamos a aprender más explorando el SDK de Python de Amazon SageMaker y construir una solución utilizando la implementación de muestra provista en esta publicación y un conjunto de datos relevante para su negocio. Si tienes dudas o sugerencias, deja un comentario.
Sobre los autores
 Amit Arora es un arquitecto especialista en inteligencia artificial y aprendizaje automático en Amazon Web Services, que ayuda a los clientes empresariales a utilizar servicios de aprendizaje automático basados en la nube para escalar rápidamente sus innovaciones. También es profesor adjunto en el programa de análisis y ciencia de datos de MS en la Universidad de Georgetown en Washington DC.
Amit Arora es un arquitecto especialista en inteligencia artificial y aprendizaje automático en Amazon Web Services, que ayuda a los clientes empresariales a utilizar servicios de aprendizaje automático basados en la nube para escalar rápidamente sus innovaciones. También es profesor adjunto en el programa de análisis y ciencia de datos de MS en la Universidad de Georgetown en Washington DC.
 Divya Muralidharan es arquitecto de soluciones en Amazon Web Services. Le apasiona ayudar a los clientes empresariales a resolver problemas comerciales con tecnología. Tiene una Maestría en Ciencias de la Computación del Instituto de Tecnología de Rochester. Fuera de la oficina, pasa tiempo cocinando, cantando y cultivando plantas.
Divya Muralidharan es arquitecto de soluciones en Amazon Web Services. Le apasiona ayudar a los clientes empresariales a resolver problemas comerciales con tecnología. Tiene una Maestría en Ciencias de la Computación del Instituto de Tecnología de Rochester. Fuera de la oficina, pasa tiempo cocinando, cantando y cultivando plantas.
 sergey ermolin es Arquitecto Principal de Soluciones AIML en AWS. Anteriormente, fue arquitecto de soluciones de software para tecnologías de big data, análisis y aprendizaje profundo en Intel. Sergey, un veterano de Silicon Valley apasionado por el aprendizaje automático y la inteligencia artificial, ha estado interesado en las redes neuronales desde antes de la GPU, cuando las usó para predecir el comportamiento de envejecimiento de los cristales de cuarzo y los relojes atómicos de cesio en Hewlett-Packard. Sergey tiene un certificado MSEE y CS de Stanford y una licenciatura en física e ingeniería mecánica de la Universidad Estatal de California, Sacramento. Fuera del trabajo, Sergey disfruta de la elaboración del vino, el esquí, el ciclismo, la vela y el buceo. Sergey también es piloto voluntario de Vuelo de ángel.
sergey ermolin es Arquitecto Principal de Soluciones AIML en AWS. Anteriormente, fue arquitecto de soluciones de software para tecnologías de big data, análisis y aprendizaje profundo en Intel. Sergey, un veterano de Silicon Valley apasionado por el aprendizaje automático y la inteligencia artificial, ha estado interesado en las redes neuronales desde antes de la GPU, cuando las usó para predecir el comportamiento de envejecimiento de los cristales de cuarzo y los relojes atómicos de cesio en Hewlett-Packard. Sergey tiene un certificado MSEE y CS de Stanford y una licenciatura en física e ingeniería mecánica de la Universidad Estatal de California, Sacramento. Fuera del trabajo, Sergey disfruta de la elaboración del vino, el esquí, el ciclismo, la vela y el buceo. Sergey también es piloto voluntario de Vuelo de ángel.





{kind=link}