

Have you thought about how you can improve the performance of your ML models without developing new models? That’s where transfer learning comes in. In this article, we will provide an overview of transfer learning along with its benefits and challenges.
What is transfer learning?
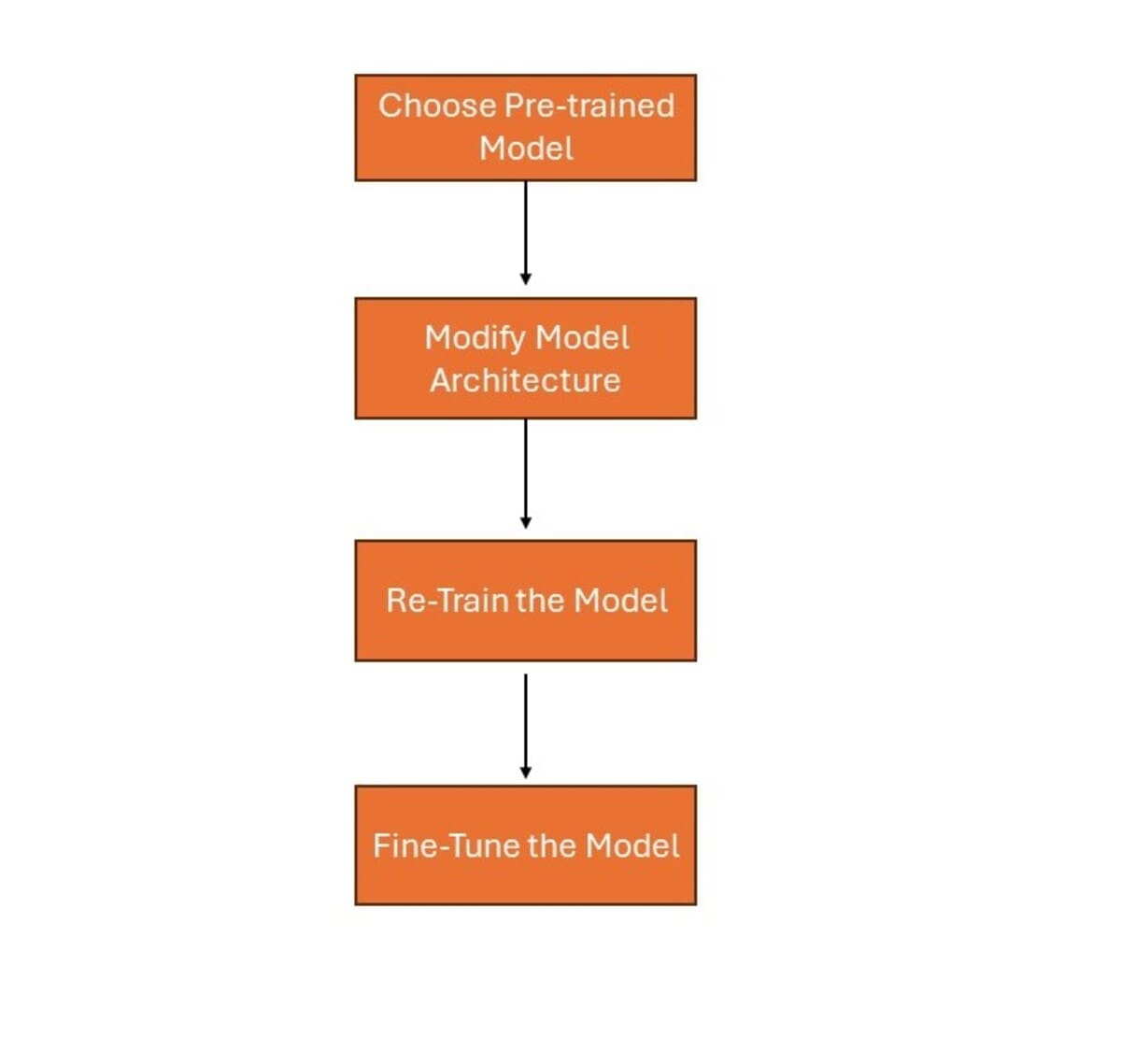
Transfer learning means that a model trained for one task can be used for another similar task. Then, you can use a previously trained model and make changes to it based on the required task. Let us discuss the stages of transfer learning.
 Author's image
Author's image
- Choose a pre-trained model:Select a model that has been trained on a large dataset for a task similar to the one you want to work on.
- Modify the model architecture: Adjust the final layers of the pre-trained model according to your specific task. Also, add new layers if necessary.
- Retrain the model: Train the modified model on your new dataset. This allows the model to learn the details of your specific task. It also benefits from the features it learned during the original training.
- Fine-tuning the model: Unfreeze some of the previously trained layers and continue training your model. This allows the model to better adapt to the new task by fine-tuning its weights.
Benefits of transfer learning
Transfer learning offers several important advantages:
- Save time and resourcesFine-tuning requires less time and computational resources as the pre-trained model was initially trained for a large number of iterations for a specific dataset. This process has already captured essential features, thus reducing the workload for the new task.
- Improve performance:Pre-trained models have learned from large datasets, so they generalize better. This leads to better performance on new tasks, even when the new dataset is relatively small. The knowledge gained from initial training helps achieve higher accuracy and better results.
- Needs less dataOne of the main benefits of transfer learning is its effectiveness with smaller data sets. The pre-trained model has already acquired useful information about patterns and features. Therefore, it can perform fairly even if it is given little new data.
Types of transfer learning
Transfer learning can be classified into three types:
Feature Extraction
Feature extraction involves using the features learned by a model on new data. For example, in image classification, we can use features from a pre-defined convolutional neural network to find meaningful features in images. Below is an example using a Keras pre-trained VGG16 model for image feature extraction:
import numpy as np
from tensorflow.keras.applications import VGG16
from tensorflow.keras.preprocessing import image
from tensorflow.keras.applications.vgg16 import preprocess_input
# Load pre-trained VGG16 model (without the top layers for classification)
base_model = VGG16(weights="imagenet", include_top=False)
# Function to extract features from an image
def extract_features(img_path):
img = image.load_img(img_path, target_size=(224, 224)) # Load image and resize
x = image.img_to_array(img) # Convert image to numpy array
x = np.expand_dims(x, axis=0) # Add batch dimension
x = preprocess_input(x) # Preprocess input according to model's requirements
features = base_model.predict(x) # Extract features using VGG16 model
return features.flatten() # Flatten to a 1D array for simplicity
# Example usage
image_path="path_to_your_image.jpg"
image_features = extract_features(image_path)
print(f"Extracted features shape: {image_features.shape}")
Fine tuning
Fine-tuning involves modifying the feature extraction steps and aspects of a new model to match the specific task. This method is most useful with a medium-sized dataset and when you want to improve a particular capability of the model related to a task. For example, in NLP, a standard BERT model can be fine-tuned or further trained on a small amount of medical texts to achieve better medical entity recognition. Here is an example of using BERT for sentiment analysis with fine-tuning on a custom dataset:
from transformers import BertTokenizer, BertForSequenceClassification, AdamW
import torch
from torch.utils.data import DataLoader, TensorDataset
# Example data (replace with your dataset)
texts = ("I love this product!", "This is not what I expected.", ...)
labels = (1, 0, ...) # 1 for positive sentiment, 0 for negative sentiment, etc.
# Load pre-trained BERT model and tokenizer
model_name="bert-base-uncased"
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForSequenceClassification.from_pretrained(model_name, num_labels=2) # Example: binary classification
# Tokenize input texts and create DataLoader
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt")
dataset = TensorDataset(inputs('input_ids'), inputs('attention_mask'), torch.tensor(labels))
dataloader = DataLoader(dataset, batch_size=16, shuffle=True)
# Fine-tuning parameters
optimizer = AdamW(model.parameters(), lr=1e-5)
# Fine-tune BERT model
model.train()
for epoch in range(3): # Example: 3 epochs
for batch in dataloader:
optimizer.zero_grad()
input_ids, attention_mask, target = batch
outputs = model(input_ids, attention_mask=attention_mask, labels=target)
loss = outputs.loss
loss.backward()
optimizer.step()
Domain adaptation
Domain adaptation allows us to understand how knowledge gained from the source domain on which the previously trained model was trained can be used in a different target domain. This is necessary when the source and target domains differ in features, data distribution, or even language. For example, in sentiment analysis we can apply a sentiment classifier learned from product reviews to social media posts because both use very different language. Here is an example where sentiment analysis is used, adapting product reviews to social media posts:
# Function to adapt text style
def adapt_text_style(text):
# Example: replace social media language with product review-like language
adapted_text = text.replace("excited", "positive").replace("#innovation", "new technology")
return adapted_text
# Example usage of domain adaptation
social_media_post = "Excited about the new tech! #innovation"
adapted_text = adapt_text_style(social_media_post)
print(f"Adapted text: {adapted_text}")
# Use sentiment classifier trained on product reviews
# Example: sentiment_score = sentiment_classifier.predict(adapted_text)
Pre-trained models
Pre-trained models are models that have already been trained on large datasets. They capture knowledge and patterns from a large amount of data. These models are used as a starting point for other tasks. Let’s discuss some of the most common pre-trained models used in machine learning applications.
VGG (Visual Geometry Group)
The architecture of VGG includes multiple layers of 3×3 convolutional filters and pooling layers. It is capable of identifying fine-grained features such as edges and shapes in images. By training on large datasets, VGG learns to recognize different objects within images. It can be used for object detection and image segmentation.
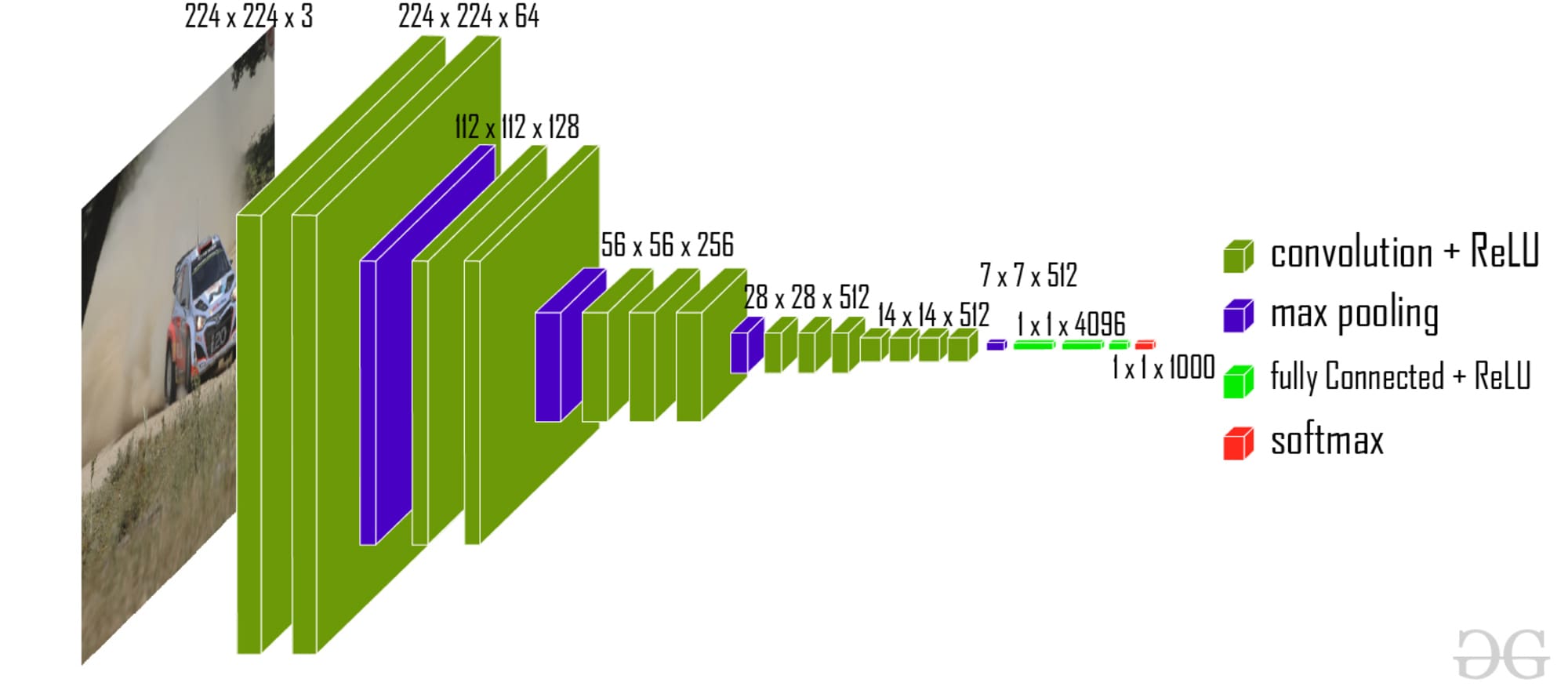 VGG-16 | CNN Model (Source: Geeks for Geeks)
VGG-16 | CNN Model (Source: Geeks for Geeks)
ResNet (Residual Network)
ResNet uses residual connections to train models. These connections facilitate the flow of gradients through the network. This avoids the vanishing gradient problem, which helps the network train efficiently. ResNet can train models with hundreds of layers successfully. ResNet is excellent for tasks like image classification and face recognition.
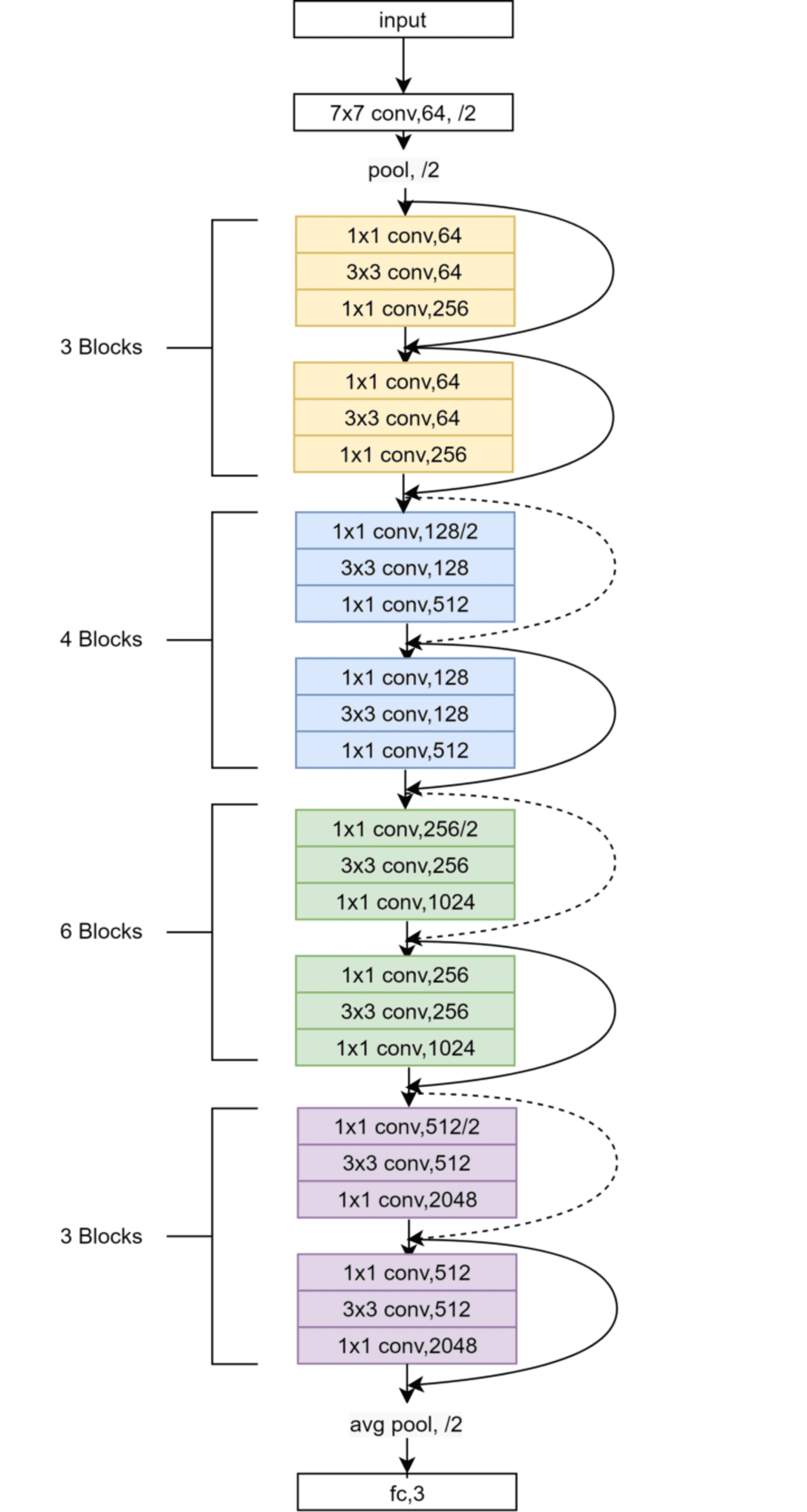 ResNet-50 Architecture (Source: Research work)
ResNet-50 Architecture (Source: Research work)
BERT (Bidirectional Encoder Representations from Transformers)
BERT is used for natural language processing applications. It uses a transformer-based model to understand the context of words in a sentence. It learns to guess missing words and understand the meaning of sentences. BERT can be used for sentiment analysis, question answering, and named entity recognition.
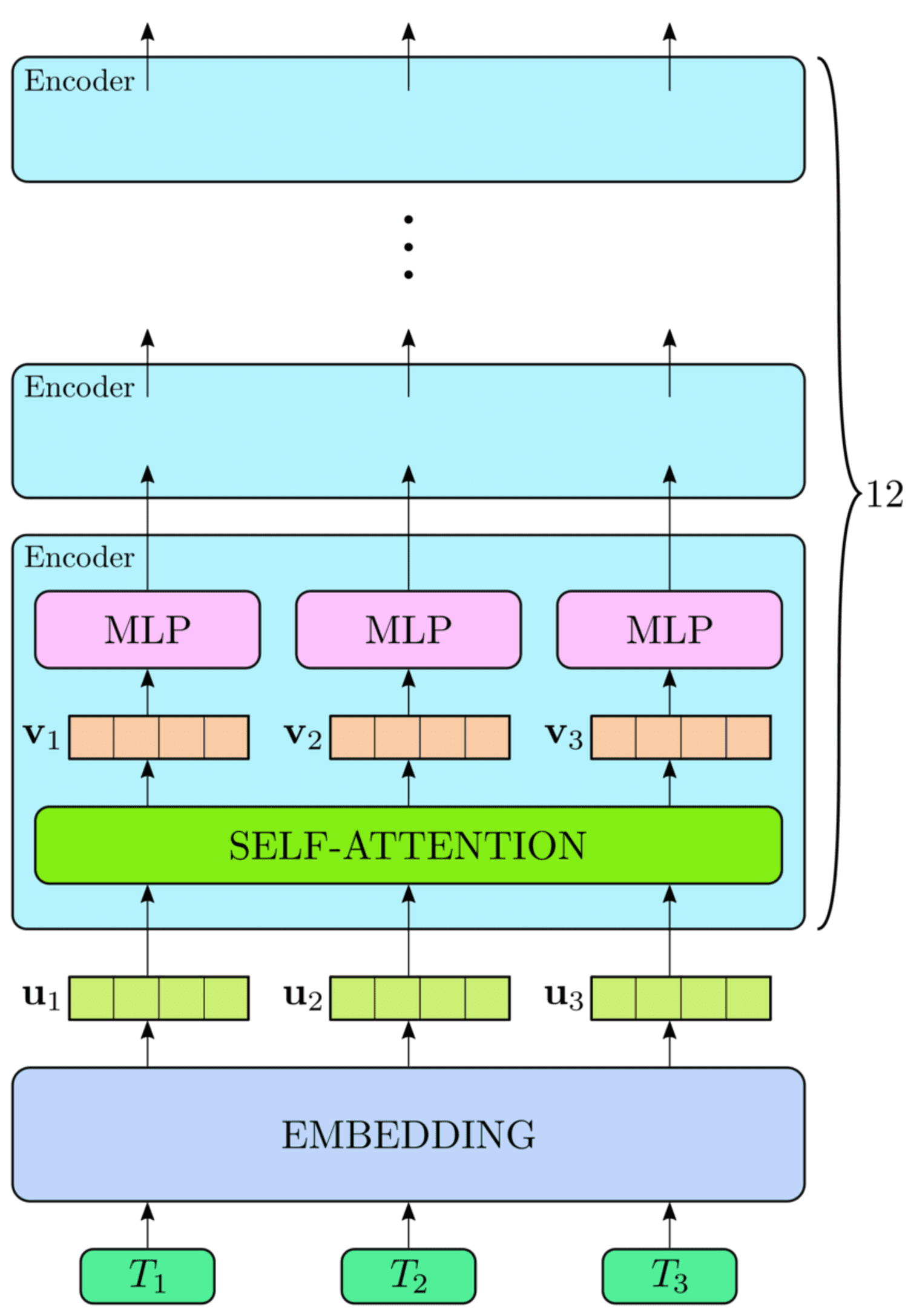 High-level view of the BERT architecture (Source: Research work)
High-level view of the BERT architecture (Source: Research work)
Fine-tuning techniques
Freezing layers
Layer freezing involves choosing certain layers from a previously trained model and preventing them from changing while training with new data. This is done to preserve the useful patterns and features that the model learned from its original training. Typically, we freeze the first few layers that capture general features like edges in images or basic structures in text.
Adjusting the learning rate
Fine-tuning the learning rate is important to balance what the model has learned and the new data. Typically, fine-tuning involves using a lower learning rate than the one used in initial training with large data sets. This helps the model adapt to the new data while still retaining most of its learned weights.
Challenges and considerations
Let's look at the challenges of transfer learning and how to address them.
- Dataset size and domain change:When fine-tuning, there needs to be a large amount of data for the task at hand while fine-tuning generalized models. The drawback of this approach is that in case the new dataset is small or significantly different from what the model is fit to in the beginning, more data can be included that is more relevant to what the model has already been trained on.
- Hyperparameter tuning:Changing hyperparameters is important when working with pre-trained models. These parameters depend on each other and determine the quality of the model. Techniques such as grid search or automated tools are used to search for the most optimal settings for hyperparameters that would yield high performance on validation data.
- Computing resourcesFine-tuning deep neural networks is computationally demanding because these models can have millions of parameters. To train and predict the outcome, powerful accelerators such as GPUs or TPUs are required. These demands are typically met by cloud computing platforms.
Ending
In conclusion, transfer learning is a cornerstone in the quest to improve model performance in various ai applications. By leveraging pre-trained models such as VGG, ResNet, BERT, and others, practitioners can efficiently leverage existing knowledge to tackle complex tasks in image classification, natural language processing, healthcare, autonomous systems, and more.
Jayita Gulati She is a machine learning enthusiast and technical writer driven by her passion for building machine learning models. She holds a Masters in Computer Science from the University of Liverpool.






{kind=link}