 NEWSLETTER
NEWSLETTER
With the widespread adoption of generative artificial intelligence (ai) solutions, organizations are trying to use these technologies to make their teams more productive. One exciting use case is enabling natural language interactions with relational databases. Rather than writing complex SQL queries, you can describe in plain language what data you want to retrieve or manipulate. The large language model (LLM) can understand the intent behind your natural language input and data topography and automatically generate the appropriate SQL code. This allows analysts to be more productive by not having to context switch into rigid query syntax, while also opening up relational databases to less technical users.
In this post, we show you how to set up and deploy a solution to chat with your databases using natural language, allowing users to gain insights into their data without writing any code or SQL queries.
Benefits of text-to-SQL generative ai and the Mixtral 8x7B model
Consider Michelle, a business analyst responsible for preparing weekly sales reports by running complex SQL queries on their data warehouse to aggregate numbers by product, region, and time period. In the past, this manual process took 2–3 hours per week working with the analyst team to write these queries by hand. Now with text-to-SQL generative ai, Michelle simply describes the report she needs in plain English, such as “Show total revenue last week for shoes in the Western region grouped by sub-category.” The ai assistant automatically generates the required SQL query, runs it on the data warehouse, and returns a formatted report in seconds.
By eliminating the SQL bottleneck, Michelle saves hours per week, now spent on more impactful analysis instead of query writing. She can iterate faster and answer questions on demand. Other business users like Michelle gain similar productivity benefits from this conversational access to relational data. The generative ai tool essentially turns self-service analytics aspirations into reality by allowing business teams to leave the SQL to the machines.
For this implementation, Mixtral 8x7B MoE was used. Mixtral 8x7B is a state-of-the-art Sparse Mixture of Experts (MoE) foundation model released by Mistral ai. It supports multiple use cases such as text summarization, classification, text generation, and code generation. It is an 8x model, which means it contains eight distinct groups of parameters. The model has about 45 billion total parameters and supports a context length of 32,000 tokens. MoE is a type of neural network architecture that consists of multiple “experts,” where each expert is a neural network. In the context of transformer models, MoE replaces some feed-forward layers with sparse MoE layers. These layers have a certain number of experts, and a router network selects which experts process each token at each layer. MoE models enable more compute-efficient and faster inference compared to dense models. Compared to traditional LLMs, Mixtral 8x7B offers the advantage of faster decoding at the speed of a smaller parameter-dense model despite containing more parameters. It also outperforms other open-access models on certain benchmarks and supports a longer context length.
You can currently deploy Mixtral 8x7B on amazon SageMaker JumpStart with one click. amazon SageMaker JumpStart provides a simplified way to access and deploy over 100 different open source and third-party foundation models. Instead of having to manually integrate, optimize, and configure each foundation model yourself, SageMaker JumpStart handles those complex tasks for you. With just a few clicks, you can deploy state-of-the-art models from Hugging Face, Cohere, AI21 Labs, Stability ai, and more using optimized containers and SageMaker endpoints. SageMaker JumpStart eliminates the heavy lifting involved in foundation model deployment. You get access to a huge catalog of prebuilt models that you can quickly put to use for inference. It’s a scalable, cost-effective way to implement powerful ai solutions without machine learning (ML) expertise.
Solution overview
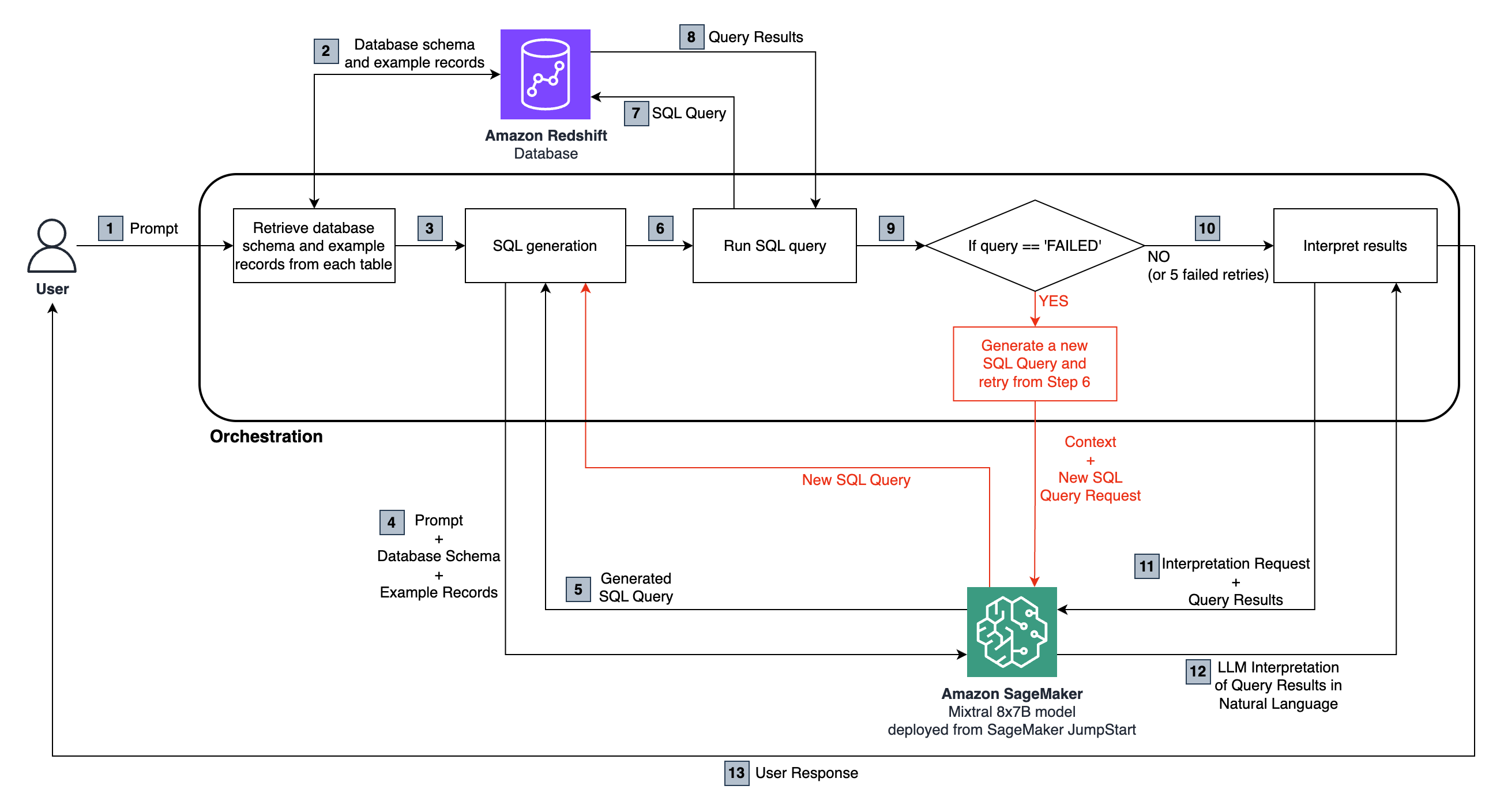
The following diagram illustrates the solution architecture.
At a high level, the overall solution consists of three core components:
The end-to-end flow is as follows:
- The user asks a natural language question, which is passed to the Mixtral 8x7B Instruct model, hosted in SageMaker.
- The LLM analyzes the question and uses the schema fetched from the connected amazon Redshift database to generate a SQL query.
- The SQL query is run against the database. In case of an error, a retry workflow is run.
- Tabular results received are passed back to the LLM to interpret and convert them into a natural language response to the user’s original question.
Prerequisites
To launch an endpoint to host Mixtral 8x7B from SageMaker JumpStart, you may need to request a service quota increase to access an ml.g5.48xlarge instance for endpoint usage. You can request service quota increases through the AWS Management Console, AWS Command Line Interface (AWS CLI), or API to allow access to those additional resources.
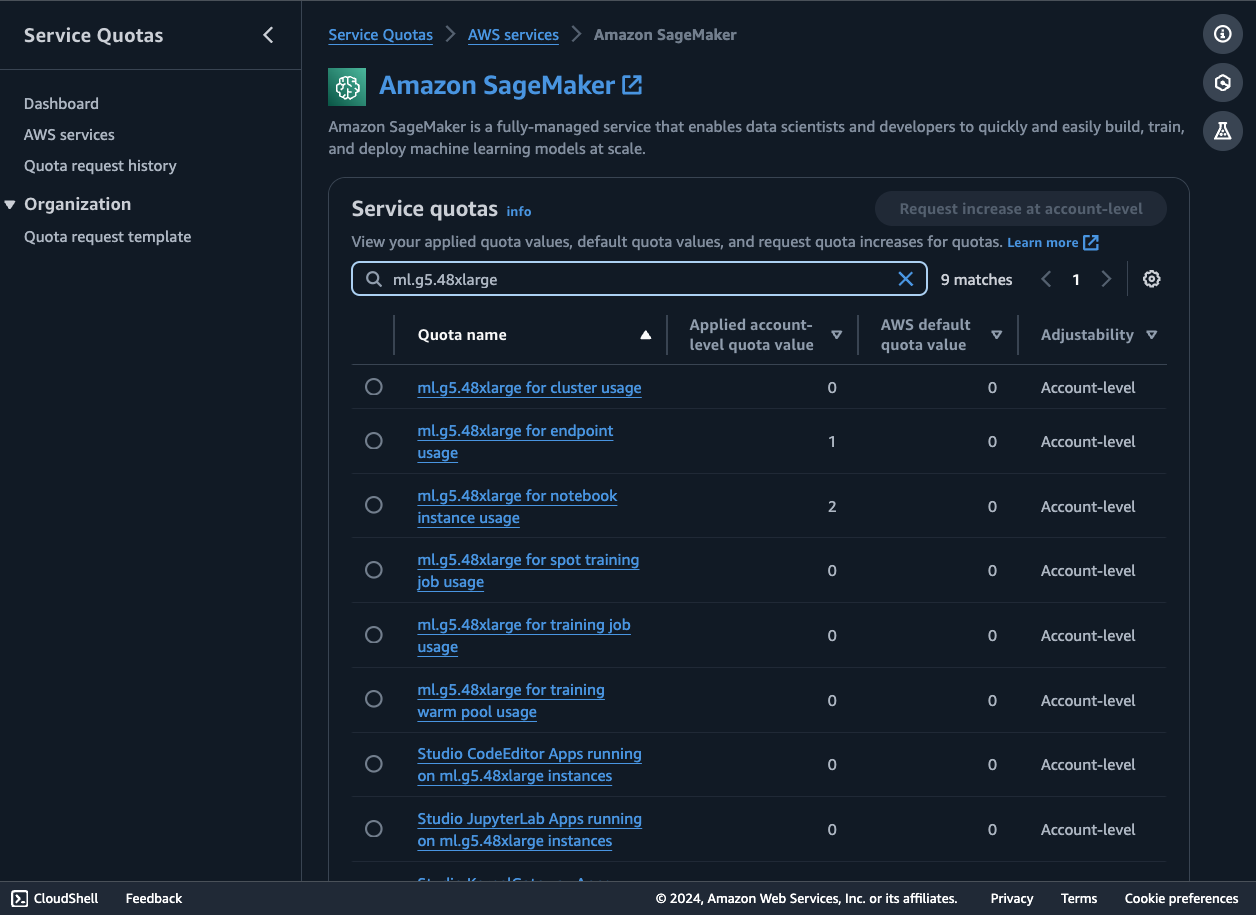
To follow along with this example, you also need access to a relational data source. amazon Redshift is used as the primary data source in this post with the TICKIT database. This database helps analysts track sales activity for the fictional TICKIT website, where users buy and sell tickets online for sporting events, shows, and concerts. In particular, analysts can identify ticket movement over time, success rates for sellers, and the best-selling events, venues, and seasons. You can also experiment with other AWS data sources like amazon RDS, Athena, or your own relational databases. Make sure to have the connection details for your data source available, such as database URL, user name, and password.
To follow the demo using amazon Redshift, you first need to set up a Redshift cluster if you don’t already have one. Use the amazon Redshift console or AWS CLI to launch a cluster with your desired node type and number of nodes. When the cluster is available, create a new database and tables in it to hold your sample relational data. You can load data from amazon Simple Storage Service (amazon S3) or directly insert rows. When storing data in amazon S3, make sure that all public access is blocked and the data is encrypted at rest and in transit. For more information, refer to Security best practices for amazon S3. Finally, make sure to note the cluster endpoint, database name, and credentials to connect. With a Redshift cluster provisioned and loaded with data, you will have an ideal relational backend ready to pair for natural language access.
To test that you successfully added data to your Redshift cluster, complete the following steps:
- On the amazon Redshift console, choose Clusters in the navigation pane.
- Choose the cluster you want to query.
- Navigate to the Query Editor tab to open the query editor.
- Run the following sample queries or write your own SQL queries:
-
- Find total sales on a given date:
- Find top 10 buyers:
The query editor allows saving, scheduling, and sharing queries. You can also view query plans, inspect run details, and monitor query performance.
Implement the solution
The code consists of a number of functions that are invoked by the logic shown in the solution diagram. We show you the relevant code blocks in this breakdown that match with the diagram. You can see the complete code for the solution in the GitHub repository.
To implement this solution, complete the following steps:
- Set up a Redshift cluster. For this post, we use an RA3 type cluster.
- Load the TICKIT sales dataset into the Redshift cluster. For instructions, see Load data from amazon S3 to amazon Redshift.
- To confirm that amazon Redshift access is private and restricted only to your VPC, refer to the steps in Enable private access to amazon Redshift from your client applications in another VPC.
- Set up a SageMaker domain, making sure it has the appropriate permissions to interact with amazon Redshift.
- Clone the following GitHub repository into SageMaker Studio Classic.
- The first step is to deploy the Mixtral 8x7B Instruct SageMaker endpoint. We use the default size ml.g5.48xlarge instance. Make sure that you have an ml.g5.48xlarge for endpoint usage service quota of at least 1.
- Set up the connectivity to the Redshift cluster. Make sure to replace these placeholders with your Redshift identifiers. For security purposes, you should have the credentials secured using AWS Secrets Manager. For instructions, see Enhance your security posture by storing amazon Redshift admin credentials without human intervention using AWS Secrets Manager integration
- Set up the natural language question and the prompt parameters for the model
The Redshift cluster is queried to generate the relevant database schema and example records, as shown in Step 2:
The generated SQL query is run on the Redshift cluster (Steps 6–8):
The query might fail because of errors in the LLM-generated SQL. This is why we have a debugging step, which can iterate for a certain number of times, asking the LLM to look at the amazon Redshift error message and the previous context (user question, DB schema, table samples, and past SQL query generated) and generate a new query addressing it. Guidance is provided to the model using prompt engineering and instructions to come up with a different query. The new query is then run on the cluster again. This process is configured to repeat up to five times in the sample code, or until the query successfully runs. If the query doesn’t run successfully within the number of retries specified, a failure message is returned back to the user. This step highlighted in red in the diagram.
If the query successfully runs, we pass the tabular results from amazon Redshift to the LLM to interpret them and, based on the initial question, provide an answer in natural language to be returned to the user (Steps 10–13):
Test the solution
Let’s explore an example run of the solution. We ask the question, “What are the top five seller names in San Diego, based on the number of tickets sold in 2008?” The following is the SQL query generated:
The following is the query response from amazon Redshift:
The following is the final answer provided by the LLM:
Best practices
Enhancing response efficiency in text-to-SQL systems involves incorporating several key best practices:
- Caching parsed SQL – To improve response times and avoid reprocessing repeated queries, parsed SQL and recognized query prompts can be cached from the system. This cache can be checked before invoking the LLM for each new text query.
- Monitoring – Usage logs and metrics around query parsing, SQL generation latency, and result set sizes should be collected. Monitoring this data enables optimization by revealing pain points—whether from inadequate training data, limitations in prompt engineering, or data model issues.
- Scheduled data refresh – To keep materialized view data current, refresh schedules using batch or incremental approaches are needed. The right balance mitigates the overhead of the refresh while making sure that text queries generate results using the latest data.
- Central data catalog – Maintaining a centralized data catalog provides a unified metadata layer across data sources, which is critical for guiding LLM SQL generation. This catalog enables selecting appropriate tables and schemas to handle text queries.
- Guardrails – Use prompt engineering to prevent the LLM from generating SQL that would alter tables or logic to prevent running queries that would alter any tables. One important recommendation is to use a user role that only has read privileges.
By considering these optimization dimensions, natural language-to-SQL solutions can scale efficiently while delivering intuitive data access. As with any generative ai system, keeping an eye on performance is key while enabling more users to benefit.
These are just a few of the different best practices that you can follow. For a deeper dive, see Generating value from enterprise data: Best practices for Text2SQL and generative ai.
Clean up
To clean up your resources, complete the steps in this section.
Delete the SageMaker endpoint
To delete a SageMaker model endpoint, follow these steps:
- On the SageMaker console, in the navigation pane, choose Inference, then choose Endpoints.
- On the Endpoints page, select the endpoint you want to delete.
- On the Actions menu, select Delete.
- On the confirmation page, choose Delete to delete the endpoint.

The endpoint deletion process will begin. You can check the endpoint status on the Endpoints page to confirm it has been deleted.
Delete the Redshift cluster
Complete the following steps to delete your Redshift cluster:
- On the amazon Redshift console, in the navigation pane, choose Clusters to display your list of clusters.
- Choose the cluster you want to delete.
- On the Actions menu, choose Delete.
- Confirm the cluster to be deleted, then choose Delete cluster.

The cluster status will be updated as the cluster is deleted. This process usually takes a few minutes.
Conclusion
The ability to query data through intuitive natural language interfaces unlocks huge potential for business users. Instead of struggling with complex SQL syntax, teams can self-serve the analytical insights they need, on demand. This improves time-to-value while allowing less technical users to access and extract meaning from enterprise data.
As highlighted in this post, the latest advances in generative ai make robust NLQ-to-SQL systems achievable. With foundation models such as Mixtral 8x7B running on SageMaker and tools and libraries for connecting to different data sources, organizations can now have an enterprise-grade solution to convert natural language queries into efficient SQL. By eliminating the traditional SQL bottleneck, generative NLQ-to-SQL systems give back countless hours each week for analysts and non-technical roles, driving greater business agility and democratization in self-service analytics.
As generative ai continues to mature rapidly, keeping up with the latest models and optimization techniques is critical. This post only scratched the surface of what will be possible in the near future as these technologies improve. Natural language interfaces for accessing and manipulating data still have huge runways for innovation ahead. To learn more about how AWS is helping customers make their ideas a reality, refer to the Generative ai Innovation Center.
About the Authors
 Jose Navarro is an ai/ML Solutions Architect at AWS, based in Spain. Jose helps AWS customers—from small startups to large enterprises—architect and take their end-to-end machine learning use cases to production. In his spare time, he loves to exercise, spend quality time with friends and family, and catch up on ai news and papers.
Jose Navarro is an ai/ML Solutions Architect at AWS, based in Spain. Jose helps AWS customers—from small startups to large enterprises—architect and take their end-to-end machine learning use cases to production. In his spare time, he loves to exercise, spend quality time with friends and family, and catch up on ai news and papers.
 Prashanth Ganapathy is a Senior Solutions Architect in the Small Medium Business (SMB) segment at AWS. He enjoys learning about AWS ai/ML services and helping customers meet their business outcomes by building solutions for them. Outside of work, Prashanth enjoys photography, travel, and trying out different cuisines.
Prashanth Ganapathy is a Senior Solutions Architect in the Small Medium Business (SMB) segment at AWS. He enjoys learning about AWS ai/ML services and helping customers meet their business outcomes by building solutions for them. Outside of work, Prashanth enjoys photography, travel, and trying out different cuisines.
 Uchenna Egbe is an Associate Solutions Architect at AWS. He spends his free time researching about herbs, teas, superfoods, and how to incorporate them into his daily diet.
Uchenna Egbe is an Associate Solutions Architect at AWS. He spends his free time researching about herbs, teas, superfoods, and how to incorporate them into his daily diet.
 Sebastian Bustillo is a Solutions Architect at AWS. He focuses on ai/ML technologies with a with a profound passion for generative ai and compute accelerators. At AWS, he helps customers unlock business value through generative ai, assisting with the overall process from ideation to production. When he’s not at work, he enjoys brewing a perfect cup of specialty coffee and exploring the world with his wife.
Sebastian Bustillo is a Solutions Architect at AWS. He focuses on ai/ML technologies with a with a profound passion for generative ai and compute accelerators. At AWS, he helps customers unlock business value through generative ai, assisting with the overall process from ideation to production. When he’s not at work, he enjoys brewing a perfect cup of specialty coffee and exploring the world with his wife.






{kind=link}