
Disaggregated systems are a new type of architecture designed to meet the high resource demands of modern applications such as social networking, search, and in-memory databases. The systems aim to overcome the physical constraints of traditional servers by pooling and managing resources such as memory and CPU across multiple machines. Flexibility, better resource utilization, and cost-effectiveness make this approach suitable for a scalable cloud infrastructure, but this distributed design presents significant challenges. Non-uniform memory access (NUMA) and remote access to resources creates latency and performance issues, which are difficult to optimize. Shared resource contention, memory locality issues, and scalability limits further complicate the use of disaggregated systems, leading to unpredictable application performance and resource management difficulties.
Currently, resource contention in memory hierarchies and locality optimizations through ONE and NUMA aware techniques In modern systems they face significant drawbacks. UMA does not consider the impact of remote memory and therefore cannot be effective on large-scale architectures. However, NUMA-based techniques are aimed at small scenarios or simulations rather than the real world. As single-core performance stagnated, multi-core systems became standard, introducing scheduling and scaling challenges. Technologies like NumaConnect unifies resources with shared memory and cache coherence, but is highly dependent on workload characteristics. Application classification schemes, such as animal classes, simplify the categorization of workloads, but lack adaptability and do not address variability in resource sensitivity.
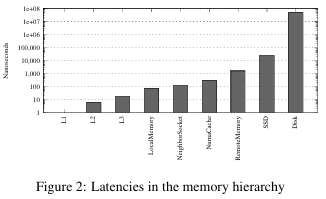
To address the challenges posed by complex NUMA topologies on application performance, researchers from Umeå University, Swedenproposed a NUMA-compliant resource mapping algorithm for virtualized environments in disaggregated systems. The researchers conducted detailed research to explore resource contention in shared environments. The researchers looked at cache contention, latency differences in the memory hierarchy, and NUMA distances, all of which influence performance.
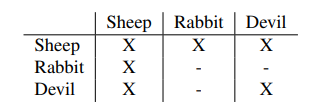
The NUMA-compatible algorithm optimized resource allocation by pinning virtual cores and migrating memory, thereby reducing memory splitting between nodes and minimizing application interference. Applications were classified (e.g., “sheep,” “rabbit,” “devil”) and carefully placed based on compatibility matrices to minimize contention. Response time, clock frequency and power usage were tracked in real time along with PCI and MPI to allow necessary changes in resource allocation. Evaluations performed on a six-node disaggregated system demonstrated that significant application performance improvements could be achieved with memory-intensive workloads compared to default schedulers.
The researchers conducted experiments with several Types of virtual machines: small, medium, large and huge running workloads like neo4j, sock store, SPECjvm2008and Streamto simulate real-world applications. The shared memory algorithm optimized the mapping of virtual to physical resources, reduced the NUMA distance and resource contention, and ensured affinity between cores and memory. It differed from the default. linux programmerwhere the main allocations are random and the performance is variable. The algorithm provided stable assignments and minimized interference.

The results showed significant performance improvements with the variants of the shared memory algorithm. (SM-IPC and SM-MPI)achieving up to 241x improvement in cases like Derby and neo4j. While the basic scheduler exhibited unpredictable performance with higher standard deviation rates 0.4shared memory algorithms maintained consistent performance with lower ratios 0.04. Besides, virtual machine The size affected the performance of the basic scheduler but had little effect on the shared memory algorithms, reflecting their efficiency in allocating resources in various environments.
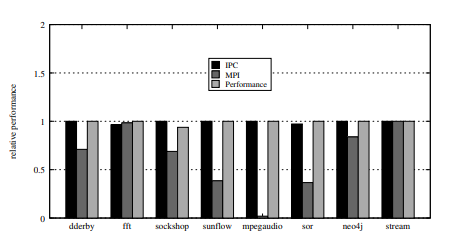
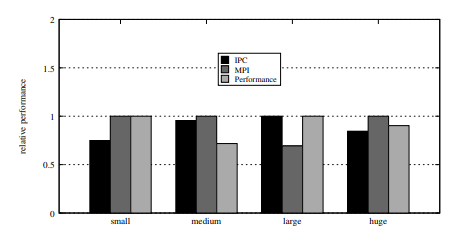
In conclusion, the algorithm proposed by the researchers allows the composition of resources from disaggregated servers, resulting in up to a 50x improvement in application performance compared to default linux programmer. The results showed that the algorithm increases resource efficiency, application co-location, and user capacity. This method can act as a foundation for future advances in resource mapping and performance optimization in NUMA disaggregated systems.
Verify he Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on <a target="_blank" href="https://twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. Don't forget to join our SubReddit over 60,000 ml.
UPCOMING FREE ai WEBINAR (JANUARY 15, 2025): <a target="_blank" href="https://info.gretel.ai/boost-llm-accuracy-with-sd-and-evaluation-intelligence?utm_source=marktechpost&utm_medium=newsletter&utm_campaign=202501_gretel_galileo_webinar”>Increase LLM Accuracy with Synthetic Data and Assessment Intelligence–<a target="_blank" href="https://info.gretel.ai/boost-llm-accuracy-with-sd-and-evaluation-intelligence?utm_source=marktechpost&utm_medium=newsletter&utm_campaign=202501_gretel_galileo_webinar”>Join this webinar to learn practical information to improve LLM model performance and accuracy while protecting data privacy..
Divyesh is a Consulting Intern at Marktechpost. He is pursuing a BTech in Agricultural and Food Engineering from the Indian Institute of technology Kharagpur. He is a data science and machine learning enthusiast who wants to integrate these leading technologies in agriculture and solve challenges.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}