
In the evolving landscape of manufacturing, the transformative power of ai and machine learning (ML) is evident, driving a digital revolution that streamlines operations and boosts productivity. However, this progress introduces unique challenges for enterprises navigating data-driven solutions. Industrial facilities grapple with vast volumes of unstructured data, sourced from sensors, telemetry systems, and equipment dispersed across production lines. Real-time data is critical for applications like predictive maintenance and anomaly detection, yet developing custom ML models for each industrial use case with such time series data demands considerable time and resources from data scientists, hindering widespread adoption.
Generative ai using large pre-trained foundation models (FMs) such as Claude can rapidly generate a variety of content from conversational text to computer code based on simple text prompts, known as zero-shot prompting. This eliminates the need for data scientists to manually develop specific ML models for each use case, and therefore democratizes ai access, benefitting even small manufacturers. Workers gain productivity through ai-generated insights, engineers can proactively detect anomalies, supply chain managers optimize inventories, and plant leadership makes informed, data-driven decisions.
Nevertheless, standalone FMs face limitations in handling complex industrial data with context size constraints (typically less than 200,000 tokens), which poses challenges. To address this, you can use the FM’s ability to generate code in response to natural language queries (NLQs). Agents like ai” target=”_blank” rel=”noopener”>PandasAI come into play, running this code on high-resolution time series data and handling errors using FMs. PandasAI is a Python library that adds generative ai capabilities to pandas, the popular data analysis and manipulation tool.
However, complex NLQs, such as time series data processing, multi-level aggregation, and pivot or joint table operations, may yield inconsistent Python script accuracy with a zero-shot prompt.
To enhance code generation accuracy, we propose dynamically constructing multi-shot prompts for NLQs. Multi-shot prompting provides additional context to the FM by showing it several examples of desired outputs for similar prompts, boosting accuracy and consistency. In this post, multi-shot prompts are retrieved from an embedding containing successful Python code run on a similar data type (for example, high-resolution time series data from Internet of Things devices). The dynamically constructed multi-shot prompt provides the most relevant context to the FM, and boosts the FM’s capability in advanced math calculation, time series data processing, and data acronym understanding. This improved response facilitates enterprise workers and operational teams in engaging with data, deriving insights without requiring extensive data science skills.
Beyond time series data analysis, FMs prove valuable in various industrial applications. Maintenance teams assess asset health, capture images for Amazon Rekognition-based functionality summaries, and anomaly root cause analysis using intelligent searches with Retrieval Augmented Generation (RAG). To simplify these workflows, AWS has introduced Amazon Bedrock, enabling you to build and scale generative ai applications with state-of-the-art pre-trained FMs like Claude v2. With Knowledge Bases for Amazon Bedrock, you can simplify the RAG development process to provide more accurate anomaly root cause analysis for plant workers. Our post showcases an intelligent assistant for industrial use cases powered by Amazon Bedrock, addressing NLQ challenges, generating part summaries from images, and enhancing FM responses for equipment diagnosis through the RAG approach.
Solution overview
The following diagram illustrates the solution architecture.
The workflow includes three distinct use cases:
Use case 1: NLQ with time series data
The workflow for NLQ with time series data consists of the following steps:
- We use a condition monitoring system with ML capabilities for anomaly detection, such as Amazon Monitron, to monitor industrial equipment health. Amazon Monitron is able to detect potential equipment failures from the equipment’s vibration and temperature measurements.
- We collect time series data by processing Amazon Monitron data through Amazon Kinesis Data Streams and Amazon Data Firehose, converting it into a tabular CSV format and saving it in an Amazon Simple Storage Service (Amazon S3) bucket.
- The end-user can start chatting with their time series data in Amazon S3 by sending a natural language query to the Streamlit app.
- The Streamlit app forwards user queries to the Amazon Bedrock Titan text embedding model to embed this query, and performs a similarity search within an Amazon OpenSearch Service index, which contains prior NLQs and example codes.
- After the similarity search, the top similar examples, including NLQ questions, data schema, and Python codes, are inserted in a custom prompt.
- PandasAI sends this custom prompt to the Amazon Bedrock Claude v2 model.
- The app uses the PandasAI agent to interact with the Amazon Bedrock Claude v2 model, generating Python code for Amazon Monitron data analysis and NLQ responses.
- After the Amazon Bedrock Claude v2 model returns the Python code, PandasAI runs the Python query on the Amazon Monitron data uploaded from the app, collecting code outputs and addressing any necessary retries for failed runs.
- The Streamlit app collects the response via PandasAI, and provides the output to users. If the output is satisfactory, the user can mark it as helpful, saving the NLQ and Claude-generated Python code in OpenSearch Service.
Use case 2: Summary generation of malfunctioning parts
Our summary generation use case consists of the following steps:
- After the user knows which industrial asset shows anomalous behavior, they can upload images of the malfunctioning part to identify if there is something physically wrong with this part according to its technical specification and operation condition.
- The user can use the Amazon Recognition DetectText API to extract text data from these images.
- The extracted text data is included in the prompt for the Amazon Bedrock Claude v2 model, enabling the model to generate a 200-word summary of the malfunctioning part. The user can use this information to perform further inspection of the part.
Use case 3: Root cause diagnosis
Our root cause diagnosis use case consists of the following steps:
- The user obtains enterprise data in various document formats (PDF, TXT, and so on) related with malfunctioning assets, and uploads them to an S3 bucket.
- A knowledge base of these files is generated in Amazon Bedrock with a Titan text embeddings model and a default OpenSearch Service vector store.
- The user poses questions related to the root cause diagnosis for malfunctioning equipment. Answers are generated through the Amazon Bedrock knowledge base with a RAG approach.
Prerequisites
To follow along with this post, you should meet the following prerequisites:
Deploy the solution infrastructure
To set up your solution resources, complete the following steps:
- Deploy the AWS CloudFormation template ai-in-industrial-operations/blob/main/cloudformation/opensearchsagemaker.yml” target=”_blank” rel=”noopener”>opensearchsagemaker.yml, which creates an OpenSearch Service collection and index, Amazon SageMaker notebook instance, and S3 bucket. You can name this AWS CloudFormation stack as:
genai-sagemaker. - Open the SageMaker notebook instance in JupyterLab. You will find the following ai-in-industrial-operations” target=”_blank” rel=”noopener”>GitHub repo already downloaded on this instance: ai-in-industrial-operations/tree/main” target=”_blank” rel=”noopener”>unlocking-the-potential-of-generative-ai-in-industrial-operations.
- Run the notebook from the following directory in this repository: ai-in-industrial-operations/blob/main/SagemakerNotebook/nlq-vector-rag-embedding.ipynb”>unlocking-the-potential-of-generative-ai-in-industrial-operations/SagemakerNotebook/nlq-vector-rag-embedding.ipynb. This notebook will load the OpenSearch Service index using the SageMaker notebook to store key-value pairs from the ai-in-industrial-operations/blob/main/data/iot_nlq_sample.yml” target=”_blank” rel=”noopener”>existing 23 NLQ examples.
- Upload documents from the data folder ai-in-industrial-operations/tree/main/data/assetpartdoc” target=”_blank” rel=”noopener”>assetpartdoc in the GitHub repository to the S3 bucket listed in the CloudFormation stack outputs.
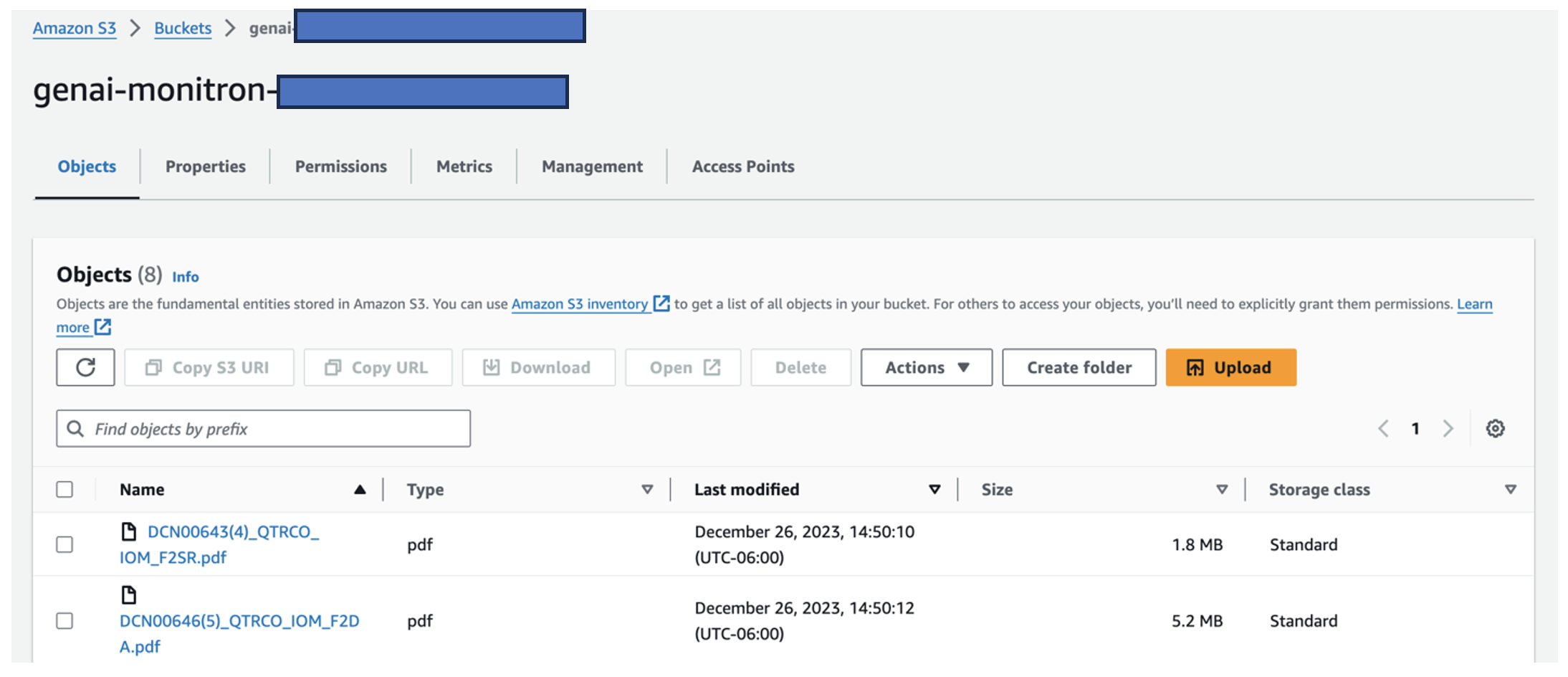
Next, you create the knowledge base for the documents in Amazon S3.
- On the Amazon Bedrock console, choose Knowledge base in the navigation pane.
- Choose Create knowledge base.
- For Knowledge base name, enter a name.
- For Runtime role, select Create and use a new service role.
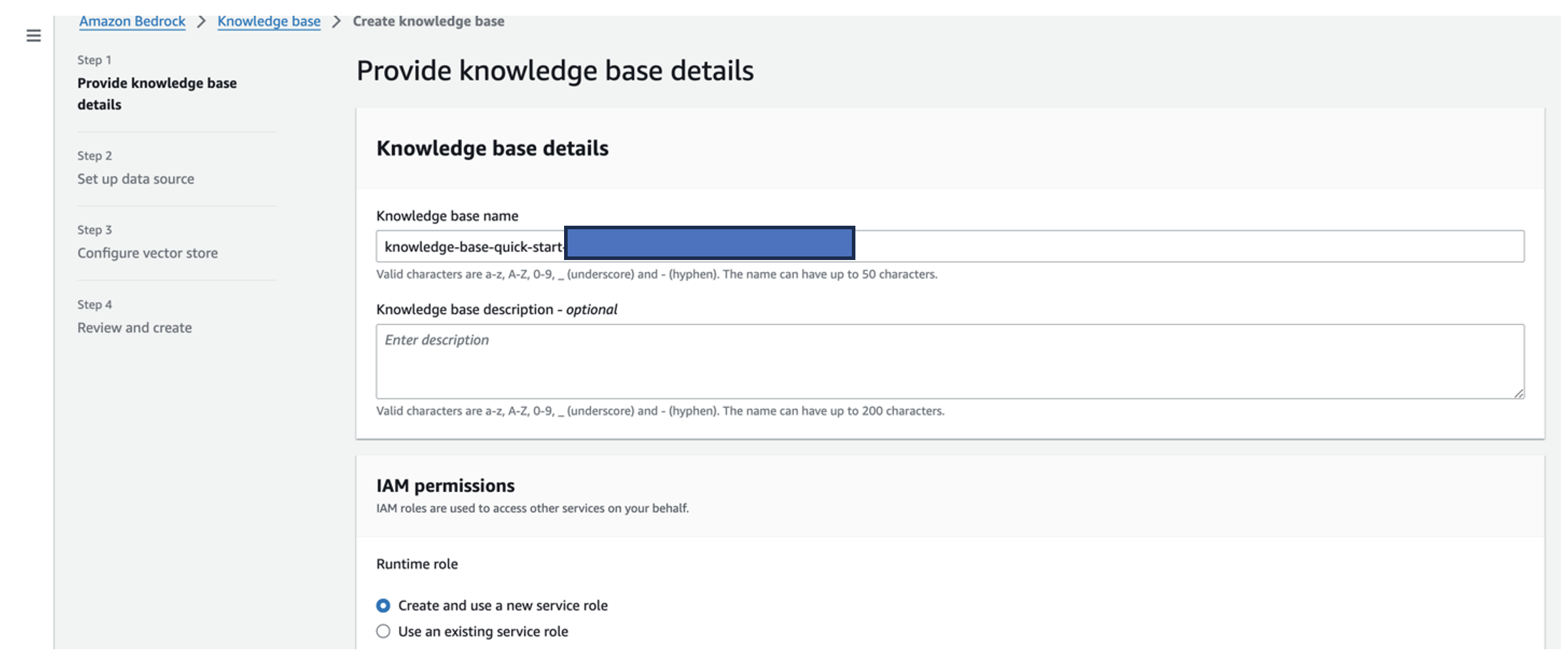
- For Data source name, enter the name of your data source.
- For S3 URI, enter the S3 path of the bucket where you uploaded the root cause documents.
- Choose Next.
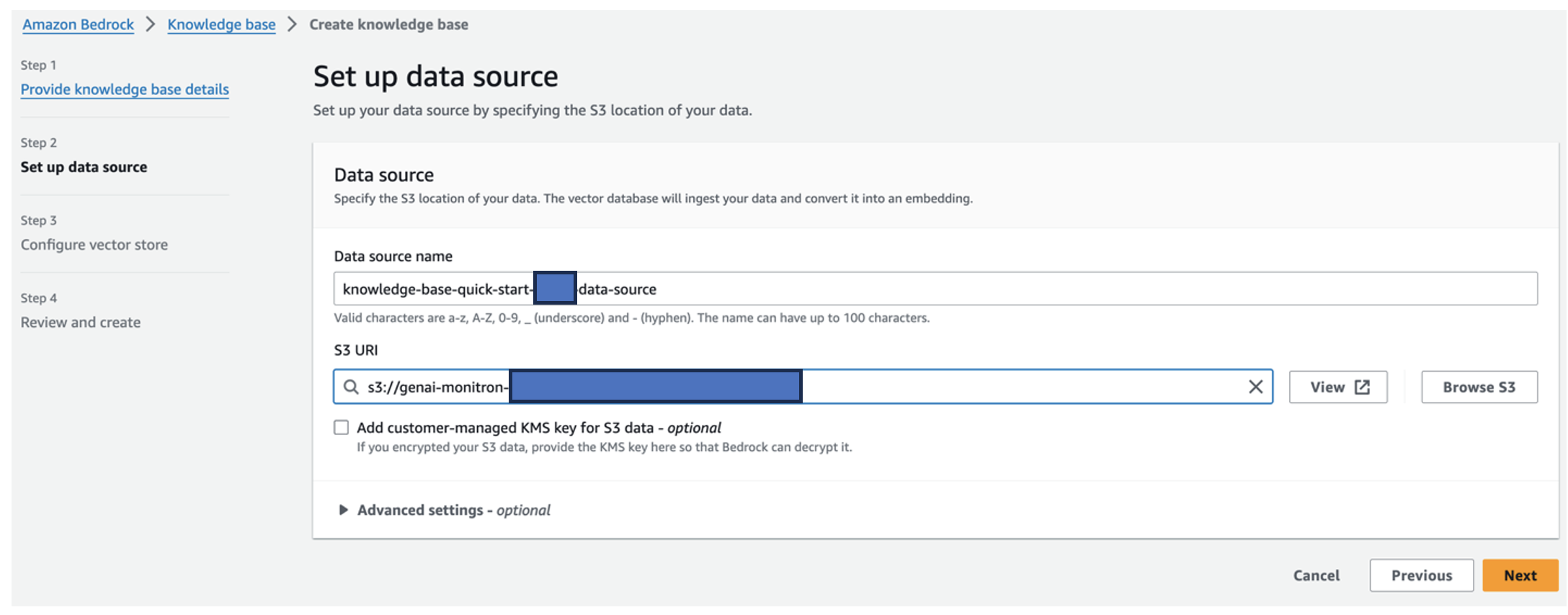 The Titan embeddings model is automatically selected.
The Titan embeddings model is automatically selected. - Select Quick create a new vector store.
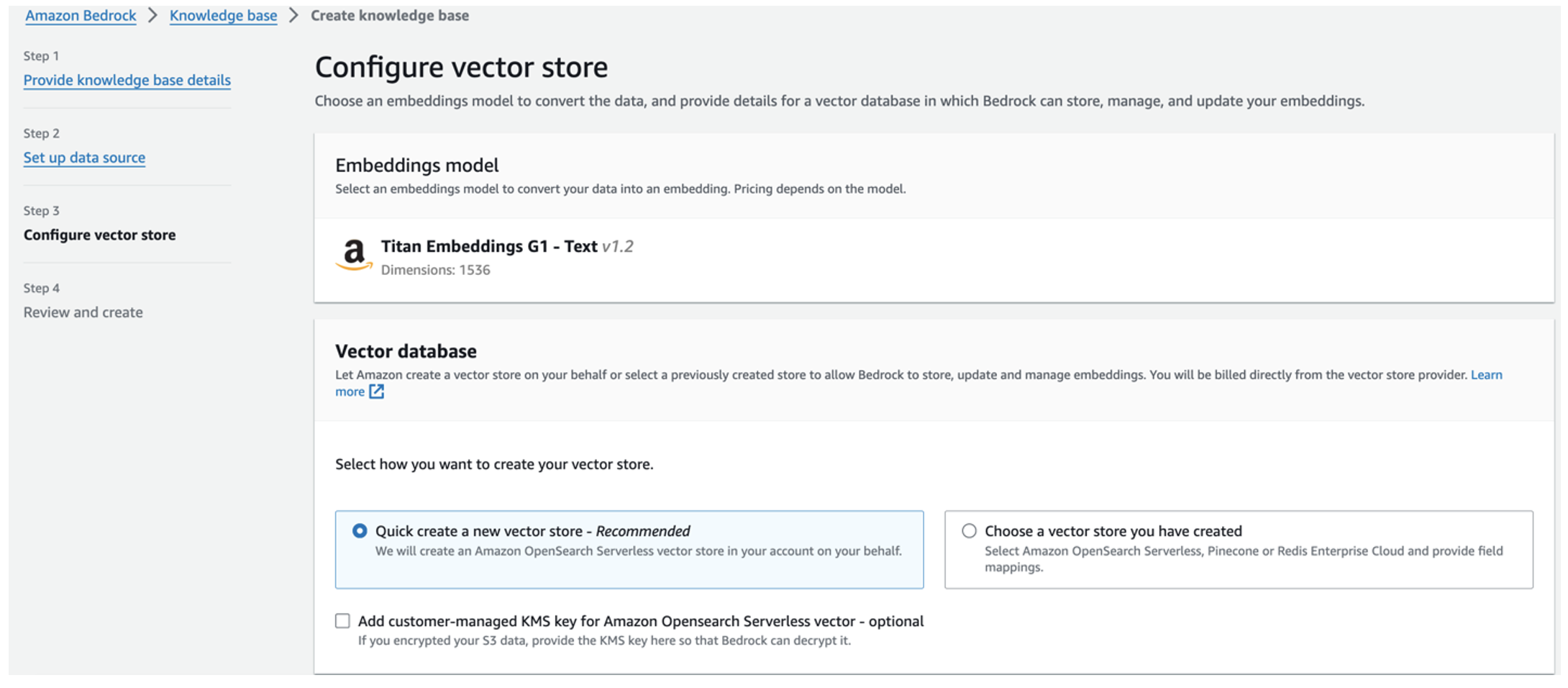
- Review your settings and create the knowledge base by choosing Create knowledge base.
- After the knowledge base is successfully created, choose Sync to sync the S3 bucket with the knowledge base.
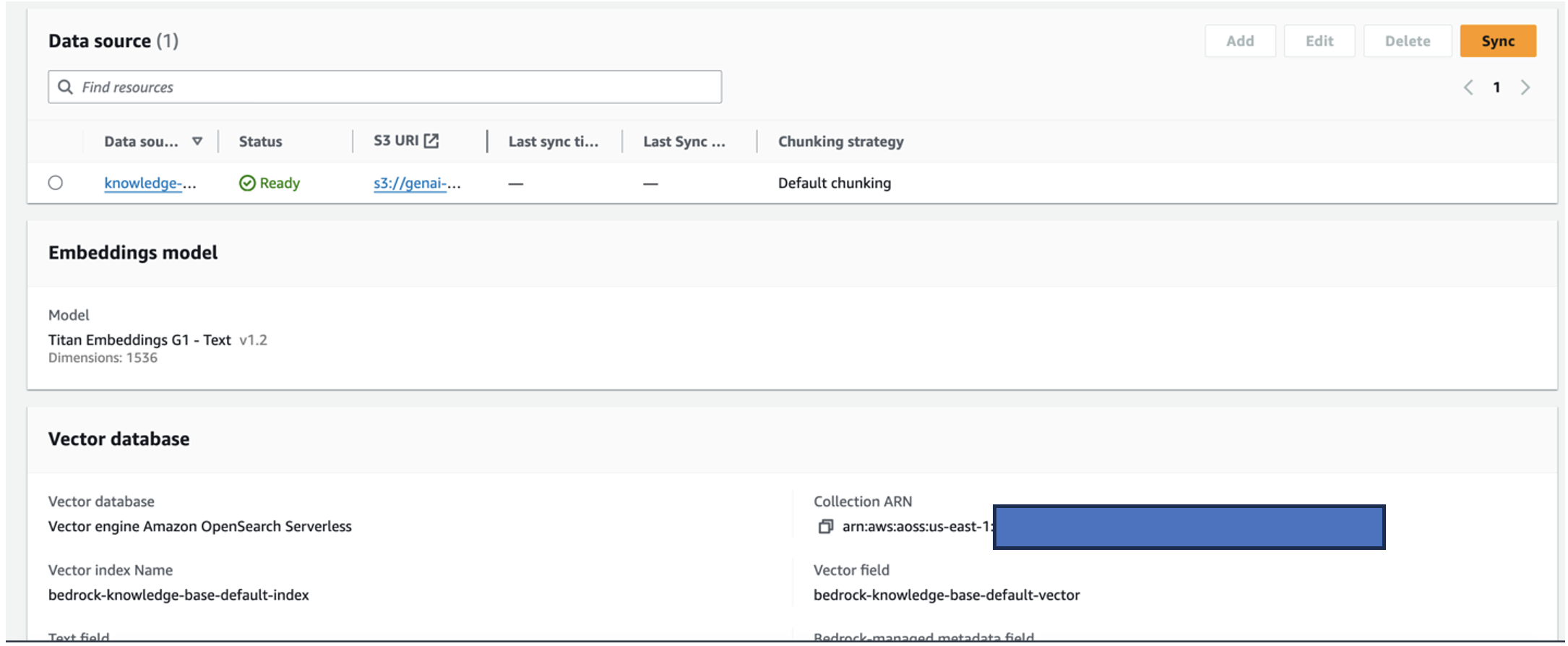
- After you set up the knowledge base, you can test the RAG approach for root cause diagnosis by asking questions like “My actuator travels slow, what might be the issue?”
The next step is to deploy the app with the required library packages on either your PC or an EC2 instance (Ubuntu Server 22.04 LTS).
- Set up your AWS credentials with the AWS CLI on your local PC. For simplicity, you can use the same admin role you used to deploy the CloudFormation stack. If you’re using Amazon EC2, attach a suitable IAM role to the instance.
- Clone ai-in-industrial-operations/tree/main” target=”_blank” rel=”noopener”>GitHub repo:
- Change the directory to
unlocking-the-potential-of-generative-ai-in-industrial-operations/srcand run thesetup.shscript in this folder to install the required packages, including LangChain and PandasAI:cd unlocking-the-potential-of-generative-ai-in-industrial-operations/src chmod +x ./setup.sh ./setup.sh - Run the Streamlit app with the following command:
source monitron-genai/bin/activate python3 -m streamlit run app_bedrock.py <REPLACE WITH YOUR BEDROCK KNOWLEDGEBASE ARN>
Provide the OpenSearch Service collection ARN you created in Amazon Bedrock from the previous step.
Chat with your asset health assistant
After you complete the end-to-end deployment, you can access the app via localhost on port 8501, which opens a browser window with the web interface. If you deployed the app on an EC2 instance, allow port 8501 access via the security group inbound rule. You can navigate to different tabs for various use cases.
Explore use case 1
To explore the first use case, choose Data Insight and Chart. Begin by uploading your time series data. If you don’t have an existing time series data file to use, you can upload the following ai-in-industrial-operations/blob/main/data/monitron_record.csv” target=”_blank” rel=”noopener”>sample CSV file with anonymous Amazon Monitron project data. If you already have an Amazon Monitron project, refer to Generate actionable insights for predictive maintenance management with Amazon Monitron and Amazon Kinesis to stream your Amazon Monitron data to Amazon S3 and use your data with this application.
When the upload is complete, enter a query to initiate a conversation with your data. The left sidebar offers a range of example questions for your convenience. The following screenshots illustrate the response and Python code generated by the FM when inputting a question such as “Tell me the unique number of sensors for each site shown as Warning or Alarm respectively?” (a hard-level question) or “For sensors shown temperature signal as NOT Healthy, can you calculate the time duration in days for each sensor shown abnormal vibration signal?” (a challenge-level question). The app will answer your question, and will also show the Python script of data analysis it performed to generate such results.


If you’re satisfied with the answer, you can mark it as Helpful, saving the NLQ and Claude-generated Python code to an OpenSearch Service index.

Explore use case 2
To explore the second use case, choose the Captured Image Summary tab in the Streamlit app. You can upload an image of your industrial asset, and the application will generate a 200-word summary of its technical specification and operation condition based on the image information. The following screenshot shows the summary generated from an image of a belt motor drive. To test this feature, if you lack a suitable image, you can use the following ai-in-industrial-operations/blob/main/data/Hydraulic_elevator_motor_label.jpg” target=”_blank” rel=”noopener”>example image.
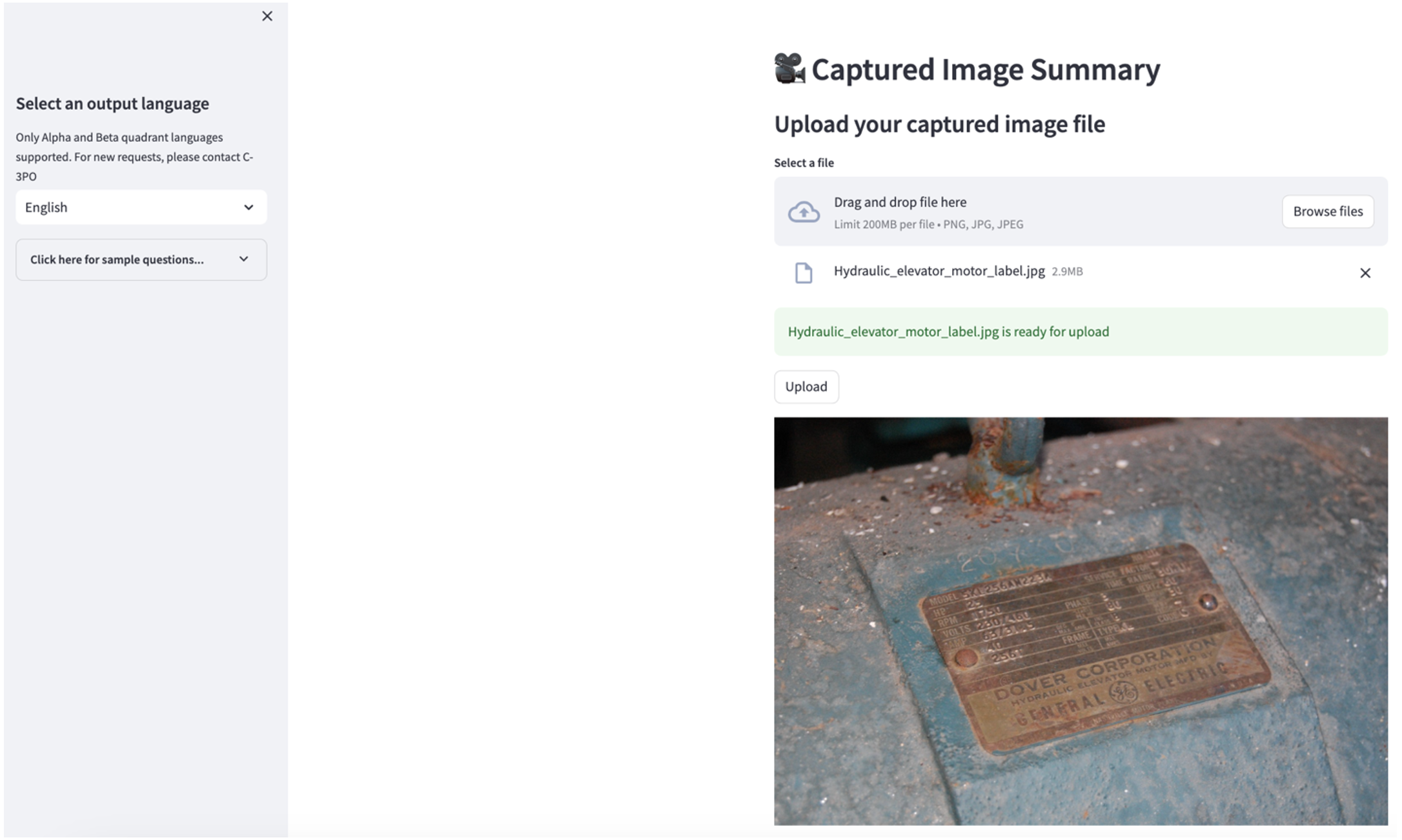
Hydraulic elevator motor label” by Clarence Risher is licensed under CC BY-SA 2.0.

Explore use case 3
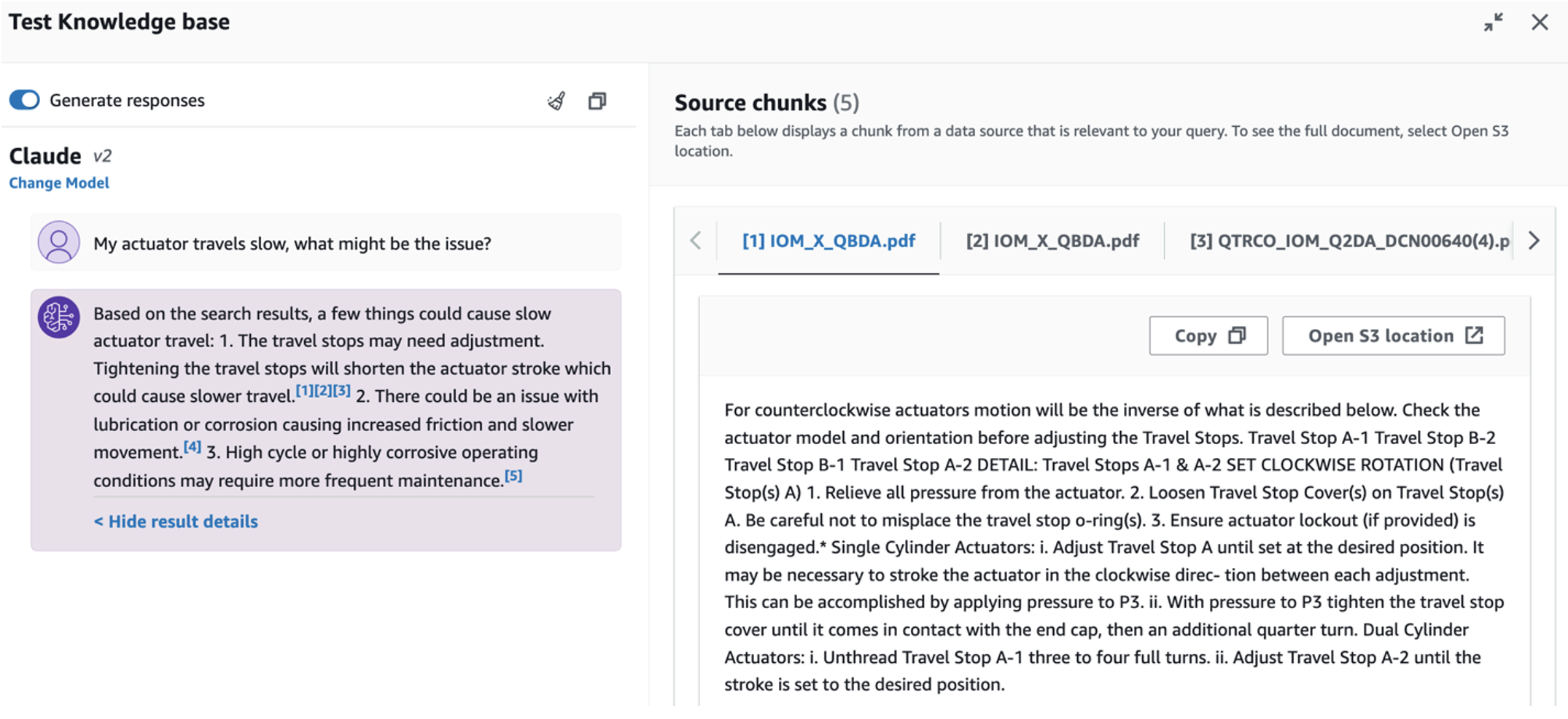
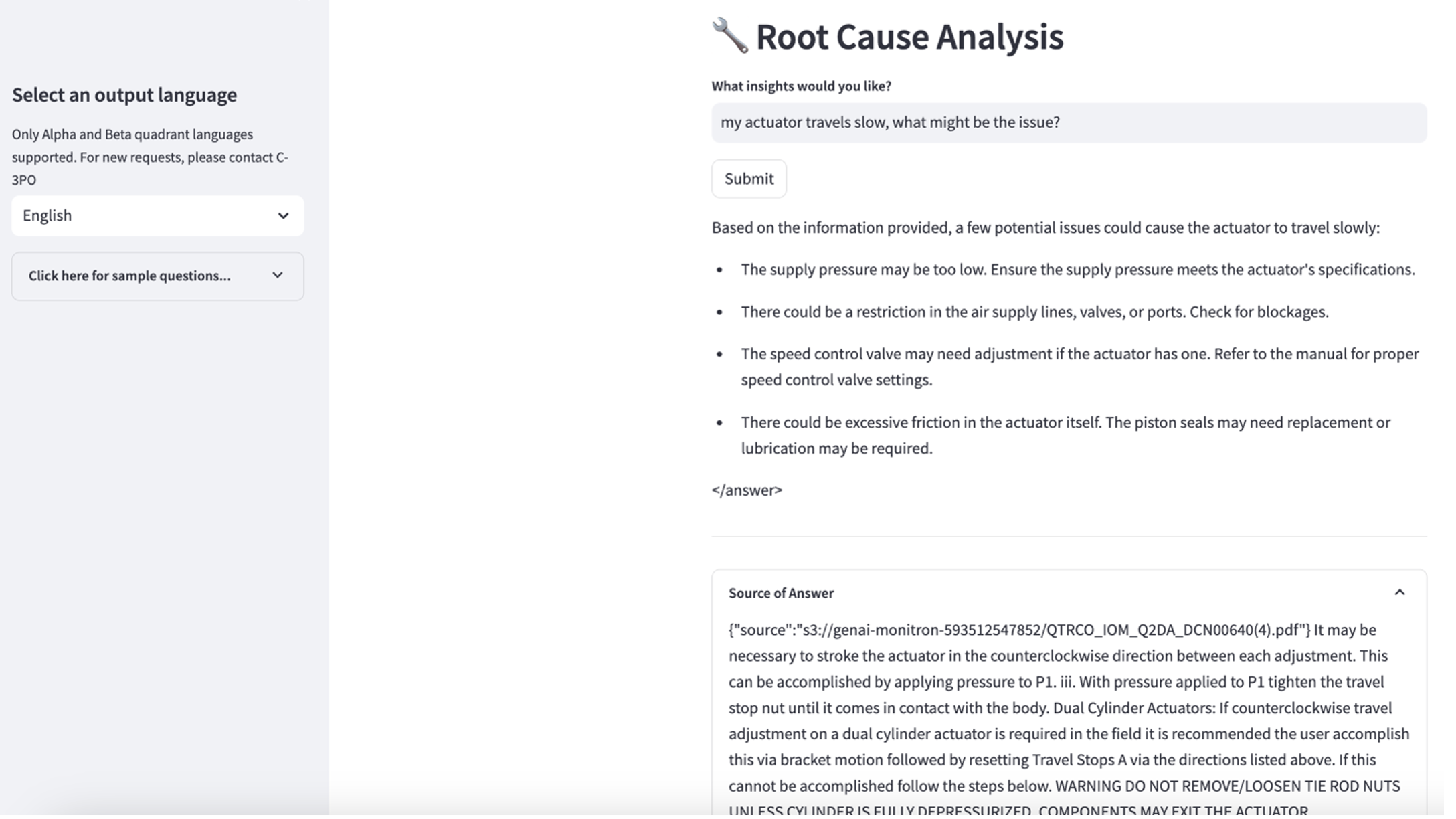
To explore the third use case, choose the Root cause diagnosis tab. Input a query related to your broken industrial asset, such as, “My actuator travels slow, what might be the issue?” As depicted in the following screenshot, the application delivers a response with the source document excerpt used to generate the answer.
Use case 1: Design details
In this section, we discuss the design details of the application workflow for the first use case.
Custom prompt building
The user’s natural language query comes with different difficult levels: easy, hard, and challenge.
Straightforward questions may include the following requests:
- Select unique values
- Count total numbers
- Sort values
For these questions, PandasAI can directly interact with the FM to generate Python scripts for processing.
Hard questions require basic aggregation operation or time series analysis, such as the following:
- Select value first and group results hierarchically
- Perform statistics after initial record selection
- Timestamp count (for example, min and max)
For hard questions, a prompt template with detailed step-by-step instructions assists FMs in providing accurate responses.
Challenge-level questions need advanced math calculation and time series processing, such as the following:
- Calculate anomaly duration for each sensor
- Calculate anomaly sensors for site on a monthly basis
- Compare sensor readings under normal operation and abnormal conditions
For these questions, you can use multi-shots in a custom prompt to enhance response accuracy. Such multi-shots show examples of advanced time series processing and math calculation, and will provide context for the FM to perform relevant inference on similar analysis. Dynamically inserting the most relevant examples from an NLQ question bank into the prompt can be a challenge. One solution is to construct embeddings from existing NLQ question samples and save these embeddings in a vector store like OpenSearch Service. When a question is sent to the Streamlit app, the question will be vectorized by BedrockEmbeddings. The top N most-relevant embeddings to that question are retrieved using opensearch_vector_search.similarity_search and inserted into the prompt template as a multi-shot prompt.
The following diagram illustrates this workflow.
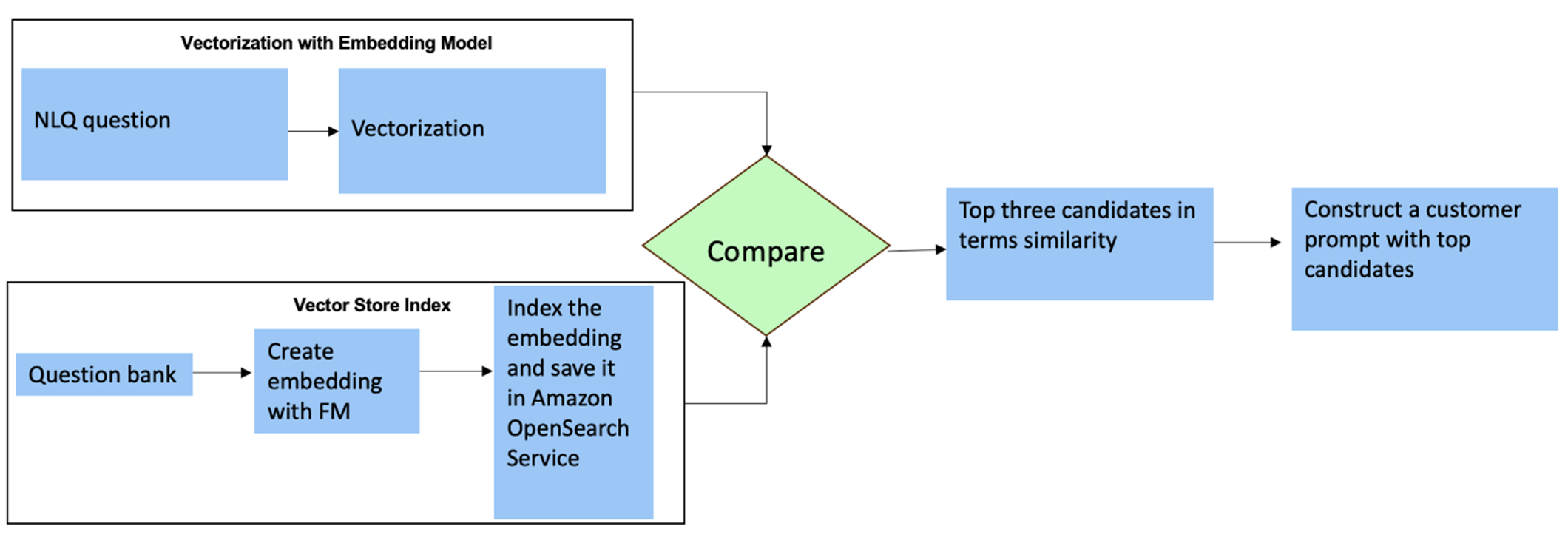
The embedding layer is constructed using three key tools:
- Embeddings model – We use Amazon Titan Embeddings available through Amazon Bedrock (amazon.titan-embed-text-v1) to generate numerical representations of textual documents.
- Vector store – For our vector store, we use OpenSearch Service via the LangChain framework, streamlining the storage of embeddings generated from NLQ examples in this notebook.
- Index – The OpenSearch Service index plays a pivotal role in comparing input embeddings to document embeddings and facilitating the retrieval of relevant documents. Because the Python example codes were saved as a JSON file, they were indexed in OpenSearch Service as vectors via an OpenSearchVevtorSearch.fromtexts API call.
Continuous collection of human-audited examples via Streamlit
At the outset of app development, we began with only 23 saved examples in the OpenSearch Service index as embeddings. As the app goes live in the field, users start inputting their NLQs via the app. However, due to the limited examples available in the template, some NLQs may not find similar prompts. To continuously enrich these embeddings and offer more relevant user prompts, you can use the Streamlit app for gathering human-audited examples.
Within the app, the following function serves this purpose. When end-users find the output helpful and select Helpful, the application follows these steps:
- Use the callback method from PandasAI to collect the Python script.
- Reformat the Python script, input question, and CSV metadata into a string.
- Check whether this NLQ example already exists in the current OpenSearch Service index using opensearch_vector_search.similarity_search_with_score.
- If there’s no similar example, this NLQ is added to the OpenSearch Service index using opensearch_vector_search.add_texts.
In the event that a user selects Not Helpful, no action is taken. This iterative process makes sure that the system continually improves by incorporating user-contributed examples.
def addtext_opensearch(input_question, generated_chat_code, df_column_metadata, opensearch_vector_search,similarity_threshold,kexamples, indexname):
#######build the input_question and generated code the same format as existing opensearch index##########
reconstructed_json = {}
reconstructed_json("question")=input_question
reconstructed_json("python_code")=str(generated_chat_code)
reconstructed_json("column_info")=df_column_metadata
json_str=""
for key,value in reconstructed_json.items():
json_str += key + ':' + value
reconstructed_raw_text =()
reconstructed_raw_text.append(json_str)
results = opensearch_vector_search.similarity_search_with_score(str(reconstructed_raw_text(0)), k=kexamples) # our search query # return 3 most relevant docs
if (dumpd(results(0)(1))<similarity_threshold): ###No similar embedding exist, then add text to embedding
response = opensearch_vector_search.add_texts(texts=reconstructed_raw_text, engine="faiss", index_name=indexname)
else:
response = "A similar embedding is already exist, no action."
return response
By incorporating human auditing, the quantity of examples in OpenSearch Service available for prompt embedding grows as the app gains usage. This expanded embedding dataset results in enhanced search accuracy over time. Specifically, for challenging NLQs, the FM’s response accuracy reaches approximately 90% when dynamically inserting similar examples to construct custom prompts for each NLQ question. This represents a notable 28% increase compared to scenarios without multi-shot prompts.
Use case 2: Design details
On the Streamlit app’s Captured Image Summary tab, you can directly upload an image file. This initiates the Amazon Rekognition API (detect_text API), extracting text from the image label detailing machine specifications. Subsequently, the extracted text data is sent to the Amazon Bedrock Claude model as the context of a prompt, resulting in a 200-word summary.
From a user experience perspective, enabling streaming functionality for a text summarization task is paramount, allowing users to read the FM-generated summary in smaller chunks rather than waiting for the entire output. Amazon Bedrock facilitates streaming via its API (bedrock_runtime.invoke_model_with_response_stream).
Use case 3: Design details
In this scenario, we’ve developed a chatbot application focused on root cause analysis, employing the RAG approach. This chatbot draws from multiple documents related to bearing equipment to facilitate root cause analysis. This RAG-based root cause analysis chatbot uses knowledge bases for generating vector text representations, or embeddings. Knowledge Bases for Amazon Bedrock is a fully managed capability that helps you implement the entire RAG workflow, from ingestion to retrieval and prompt augmentation, without having to build custom integrations to data sources or manage data flows and RAG implementation details.
When you’re satisfied with the knowledge base response from Amazon Bedrock, you can integrate the root cause response from the knowledge base to the Streamlit app.
Clean up
To save costs, delete the resources you created in this post:
- Delete the knowledge base from Amazon Bedrock.
- Delete the OpenSearch Service index.
- Delete the genai-sagemaker CloudFormation stack.
- Stop the EC2 instance if you used an EC2 instance to run the Streamlit app.
Conclusion
Generative ai applications have already transformed various business processes, enhancing worker productivity and skill sets. However, the limitations of FMs in handling time series data analysis have hindered their full utilization by industrial clients. This constraint has impeded the application of generative ai to the predominant data type processed daily.
In this post, we introduced a generative ai Application solution designed to alleviate this challenge for industrial users. This application uses an open source agent, PandasAI, to strengthen an FM’s time series analysis capability. Rather than sending time series data directly to FMs, the app employs PandasAI to generate Python code for the analysis of unstructured time series data. To enhance the accuracy of Python code generation, a custom prompt generation workflow with human auditing has been implemented.
Empowered with insights into their asset health, industrial workers can fully harness the potential of generative ai across various use cases, including root cause diagnosis and part replacement planning. With Knowledge Bases for Amazon Bedrock, the RAG solution is straightforward for developers to build and manage.
The trajectory of enterprise data management and operations is unmistakably moving towards deeper integration with generative ai for comprehensive insights into operational health. This shift, spearheaded by Amazon Bedrock, is significantly amplified by the growing robustness and potential of LLMs like Amazon Bedrock Claude 3 to further elevate solutions. To learn more, visit consult the Amazon Bedrock documentation, and get hands-on with the Amazon Bedrock workshop.
About the authors
 Julia Hu is a Sr. ai/ML Solutions Architect at Amazon Web Services. She is specialized in Generative ai, Applied Data Science and IoT architecture. Currently she is part of the Amazon Q team, and an active member/mentor in Machine Learning Technical Field Community. She works with customers, ranging from start-ups to enterprises, to develop AWSome generative ai solutions. She is particularly passionate about leveraging Large Language Models for advanced data analytics and exploring practical applications that address real-world challenges.
Julia Hu is a Sr. ai/ML Solutions Architect at Amazon Web Services. She is specialized in Generative ai, Applied Data Science and IoT architecture. Currently she is part of the Amazon Q team, and an active member/mentor in Machine Learning Technical Field Community. She works with customers, ranging from start-ups to enterprises, to develop AWSome generative ai solutions. She is particularly passionate about leveraging Large Language Models for advanced data analytics and exploring practical applications that address real-world challenges.
 Sudeesh Sasidharan is a Senior Solutions Architect at AWS, within the Energy team. Sudeesh loves experimenting with new technologies and building innovative solutions that solve complex business challenges. When he is not designing solutions or tinkering with the latest technologies, you can find him on the tennis court working on his backhand.
Sudeesh Sasidharan is a Senior Solutions Architect at AWS, within the Energy team. Sudeesh loves experimenting with new technologies and building innovative solutions that solve complex business challenges. When he is not designing solutions or tinkering with the latest technologies, you can find him on the tennis court working on his backhand.
 Neil Desai is a technology executive with over 20 years of experience in artificial intelligence (ai), data science, software engineering, and enterprise architecture. At AWS, he leads a team of Worldwide ai services specialist solutions architects who help customers build innovative Generative ai-powered solutions, share best practices with customers, and drive product roadmap. In his previous roles at Vestas, Honeywell, and Quest Diagnostics, Neil has held leadership roles in developing and launching innovative products and services that have helped companies improve their operations, reduce costs, and increase revenue. He is passionate about using technology to solve real-world problems and is a strategic thinker with a proven track record of success.
Neil Desai is a technology executive with over 20 years of experience in artificial intelligence (ai), data science, software engineering, and enterprise architecture. At AWS, he leads a team of Worldwide ai services specialist solutions architects who help customers build innovative Generative ai-powered solutions, share best practices with customers, and drive product roadmap. In his previous roles at Vestas, Honeywell, and Quest Diagnostics, Neil has held leadership roles in developing and launching innovative products and services that have helped companies improve their operations, reduce costs, and increase revenue. He is passionate about using technology to solve real-world problems and is a strategic thinker with a proven track record of success.






{kind=link}