 NEWSLETTER
NEWSLETTER
Introduction
XLNet is an autoregressive pretraining method proposed in the article “XLNet: Generalized Autoregressive Pretraining for Language Understanding”. XLNet uses an innovative approach to training. Unlike previous models like BERT, which use masked language modeling (MLM), where certain words are masked and predicted based on context, XLNet employs permutation language modeling (PLM). This means that it is trained with all possible permutations of the input sequence, allowing it to capture bidirectional context without masking. XLNet has several use cases, some of which are explored in this article.
Learning objectives
- Understand how XLNet differs from traditional autoregressive models and its adoption of permutation language modeling (PLM).
- Familiarize yourself with the XLNet architecture, including input embeddings, Transformer blocks, and self-attention mechanisms.
- Understand the two-stream language modeling approach in XLNet to capture bi-directional context effectively.
- Explore XLNet's application domains, including natural language understanding tasks and other applications such as question answering and text generation.
- Learn practical implementation through code demonstrations for tasks such as answering multiple-choice questions and classifying text.
What is XLNet?
In traditional autoregressive language models such as GPT (Generative Pre-Trained Transformer), each token in the input sequence is predicted based on the tokens preceding it. However, this sequential nature limits the model's ability to capture bidirectional dependencies effectively.
PLM addresses this limitation by training the model to predict a token given its context, not just its left context as in autoregressive models, but all possible permutations of its context.
XLNet Architecture
XLNet comprises input embeddings, multiple self-attending Transformer blocks, position-aware feedforward networks, layer normalization, and residual connections. Its multi-headed self-attention differs in that it allows each token to attend to itself, improving contextual understanding compared to other models.
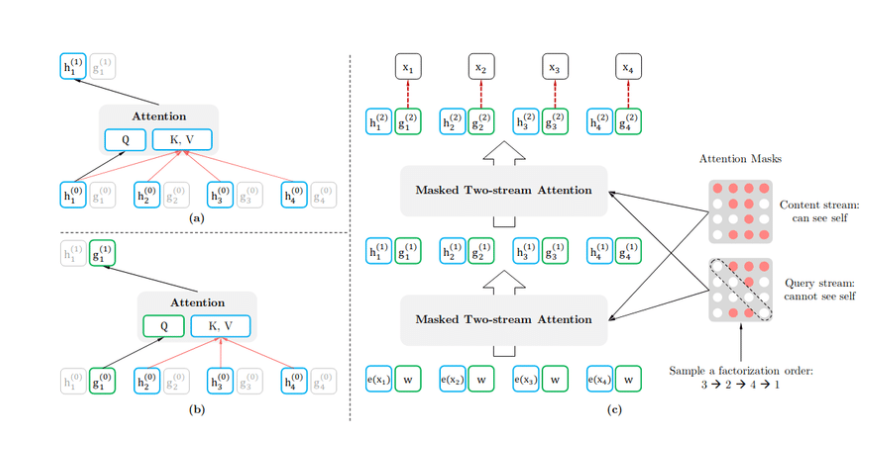
Two-stream language modeling
In XLNet, a dual-stream approach is used during pre-training. It involves learning two separate probability distributions over tokens in a sequence, each conditional on a different permutation of the input tokens. An autoregressive flow predicts each token based on the tokens preceding it in a fixed order. In contrast, the other flow is bidirectional, allowing tokens to serve preceding and following tokens. This approach helps XLNet capture bidirectional context effectively during pre-training, improving performance in subsequent natural language processing tasks.
Content flow: Encode the real words and their contexts.
Query flow: It encodes the context information necessary to predict the next word without seeing it.
These streams allow the model to gather contextual information while avoiding trivial predictions based on the word.
XLNet and BERT
XLNet and BERT are advanced language models that significantly impact natural language processing. BERT (Bidirectional Encoder Representations from Transformers) uses a masked language modeling approach, masking some tokens in a sequence and training the model to predict these masked tokens based on the context provided by the unmasked tokens. This two-way context allows BERT to understand the meaning of words based on the surrounding words. BERT's bidirectional training captures rich contextual information, making it very effective for various NLP tasks such as question answering and sentiment analysis.
XLNet, on the other hand, enhances BERT's capabilities by integrating autoregressive and auto-encoding approaches. It introduces permutation language modeling, which considers all possible permutations of word order in a sequence during training. This method allows XLNet to capture bidirectional context without relying on the masking technique, thus preserving the dependency between words.
Additionally, XLNet employs a two-stream attention mechanism to better handle context and word prediction. As a result, XLNet achieves superior performance on many benchmark NLP tasks by leveraging a more complete understanding of language context compared to BERT's fixed bidirectional approach.
XLNet Use Cases
Natural Language Understanding (NLU):
XLNet can be used for tasks such as sentiment analysis, text classification, named entity recognition, and language modeling. Its ability to capture bidirectional context and relationships within text makes it suitable for various NLU tasks.
Answer to questions:
You can tune XLNet for question answering tasks, where you read a passage of text and answer questions related to it. It has shown competitive performance on benchmarks such as SQuAD (Stanford Question Answering Dataset).
Text generation:
Due to its autoregressive nature and its ability to capture bidirectional context, XLNet can generate coherent and contextually relevant text. This makes it useful for tasks such as dialogue generation, summarization, and machine translation.
Translator machine:
XLNet can be tuned for machine translation tasks, translating text from one language to another. Although it is not designed specifically for translation, its powerful language representation capabilities make it suitable for this task when fine-tuned with translation data sets.
Recover of information:
Users can use it to understand and retrieve relevant information from large volumes of text, making it valuable for applications such as search engines, document retrieval, and information extraction.
How to use XLNet for FAQ?
This code demonstrates how to use the XLNet model to answer multiple choice questions.
from transformers import AutoTokenizer, XLNetForMultipleChoice
import torchtokenizer = AutoTokenizer.from_pretrained("xlnet/xlnet-base-cased")
model = XLNetForMultipleChoice.from_pretrained("xlnet/xlnet-base-cased")
# New prompt and choices
prompt = "What is the capital of France?"
choice0 = "Paris"
choice1 = "London"
# Encode prompt and choices
encoding = tokenizer((prompt, prompt), (choice0, choice1), return_tensors="pt", padding=True)
# Check if model is loaded (safety precaution)
if model is not None:
outputs = model(**{k: v.unsqueeze(0) for k, v in encoding.items()})
# Extract logits (assuming the model is loaded)
if outputs is not None:
logits = outputs.logits
# Predicted class with highest logit (assuming logits are available)
if logits is not None:
predicted_class = torch.argmax(logits, dim=-1).item() # Get the class with the highest score

# Print chosen answer based on predicted class
chosen_answer = choice0 if predicted_class == 0 else choice1
print(f"Predicted Answer: {chosen_answer}")
else:
print("Model outputs not available (potentially due to an untrained model).")
else:
print("Model not loaded successfully.")After defining a message and options, you encode them using the tokenizer and pass them through the model to obtain predictions. The predicted response is then determined based on the highest logit. In theory, fine-tuning this pre-trained model on a decent-sized prompts and options dataset should produce good results.
XLNet for text classification
Demonstration of Python code for text classification using XLNet
from transformers import XLNetTokenizer, TFXLNetForSequenceClassification
import tensorflow as tf
import warnings
# Ignore all warnings
warnings.filterwarnings("ignore")
# Define labels (modify as needed)
labels = ("Positive", "Negative")
# Load tokenizer and pre-trained model
tokenizer = XLNetTokenizer.from_pretrained('xlnet-base-cased')
model = TFXLNetForSequenceClassification.from_pretrained('xlnet-base-cased', num_labels=len(labels))
# Sample text data
text_data = ("This movie was amazing!", "I hated this restaurant.")
# Preprocess text (tokenization)
encoded_data = tokenizer(text_data, padding="max_length", truncation=True, return_tensors="tf")
# Perform classification
outputs = model(encoded_data)
predictions = tf.nn.softmax(outputs.logits, axis=-1)
# Print predictions
for i, text in enumerate(text_data):
predicted_label = labels(tf.argmax(predictions(i)).numpy())
print(f"Text: {text}\nPredicted Label: {predicted_label}")
The tokenizer preprocesses the provided sample text data for classification, ensuring that it is tokenized and populated appropriately. The model then performs a classification of the encoded data and generates results. These outputs are subjected to a sigmoid/softmax function (based on the number of classes) to derive predicted probabilities for each label.
Conclusion
In summary, XLNet offers an innovative approach to language understanding through permutation language modeling (PLM). By training on all possible permutations of input sequences, XLNet efficiently captures bidirectional context without the need for masking, thereby overcoming the limitations of traditional autoregressive models such as BERT.






{kind=link}