 NEWSLETTER
NEWSLETTER
Language models (LMs) show better performance with larger training data and size, but the relationship between model scale and hallucinations remains unexplored. Defining hallucinations in LMs presents challenges due to their varied manifestations. A new study from Google Deepmind focuses on hallucinations where correct answers appear verbatim in the training data. Achieving low hallucination rates requires larger models and more computational resources than previously believed. Detecting hallucinations becomes increasingly difficult as LM sizes increase. Knowledge graphs (KGs) offer a promising approach to providing structured, factual training data for LMs, potentially mitigating hallucinations.
The study investigates the relationship between language model (LM) scale and hallucinations, focusing on cases where there are correct answers in the training data. Using a knowledge graph (KG)-based dataset, the researchers train increasingly larger LMs to effectively control the training content. The findings indicate that larger, longer-trained LMs hallucinate less, but achieving low hallucination rates requires significantly more resources than previously believed. The study also reveals an inverse relationship between LM scale and hallucination detectability.
Accurately defining and quantifying hallucinations in natural language settings remains challenging due to language ambiguity and unclear knowledge content in training data. Despite advances in generative capabilities, hallucinations persist as a major challenge for learning models. Research addresses the gap in understanding how hallucinations depend on model scale. Knowledge graphs offer a structured approach to training learning models, allowing for easy fact checking against the dataset and providing a quantifiable measure of hallucination.
Traditional language models (LMs) trained with natural language data often produce hallucinations and repetitive information due to semantic ambiguity. The study employs a knowledge graph (KG) approach, using structured triplets of information to provide a clearer understanding of how LMs misrepresent training data. This method allows for a more accurate assessment of hallucinations and their relationship to model scale.
The study constructs a dataset using knowledge graph triplets (subject, predicate, object), allowing for fine-grained control over the training data and quantifiable measurement of hallucinations. Language models (LMs) are trained from scratch on this dataset, optimizing for autoregressive likelihood. Evaluation involves prompting the models with subject and predicate, and assessing object completion accuracy against the knowledge graph. Token tasks and head detectors assess hallucination detection performance. The methodology focuses on hallucinations where correct answers appear verbatim in the training set, exploring the relationship between the LM scale and hallucination frequency.
The research trains increasingly larger LMs to investigate scale effects on hallucination rates and detectability. The analysis reveals that larger, longer-trained LMs hallucinate less, although larger datasets may increase hallucination rates. The authors acknowledge limitations in generalizing to all hallucination types and using smaller models than state-of-the-art models. This comprehensive approach provides insights into LM hallucinations and their detectability, contributing to the field of natural language processing.
The study reveals that larger language models and extended training reduce hallucinations on fixed datasets, while larger dataset sizes elevate hallucination rates. Hallucination detectors show high accuracy, which improves with model size. Token-level detection generally outperforms other methods. There is a trade-off between fact recall and generalization ability, as extended training minimizes hallucinations on seen data but risks overfitting on unseen data. The AUC-PR serves as a reliable measure of detector performance. These findings highlight the complex relationship between model scale, dataset size, and hallucination rates, emphasizing the importance of balancing model size and training duration to mitigate hallucinations while addressing the challenges posed by larger datasets.
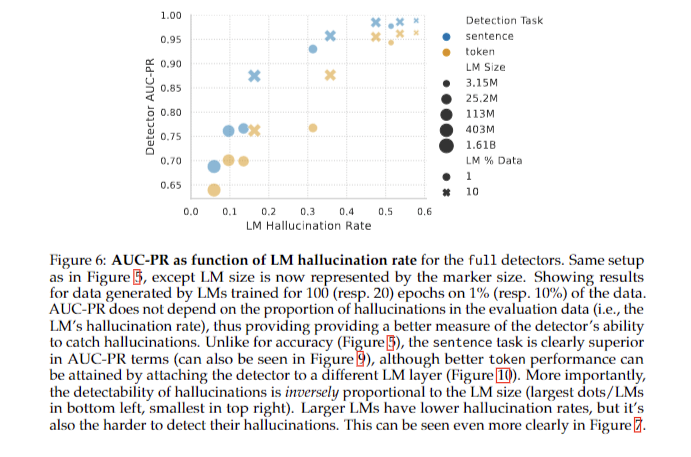
In conclusion, the study reveals that larger and longer trained language models show reduced hallucination rates, but achieving minimal hallucinations requires substantial computational resources. Larger dataset size correlates with higher hallucination rates when model size and training epochs remain constant. There is a trade-off between memorization and generalization, as extended training improves data retention but potentially hampers adaptability to new data. Paradoxically, as models become larger and hallucinate less, detection of remaining hallucinations becomes more difficult. Future research should focus on improving hallucination detection in larger models and exploring the practical implications of these findings for applications of language models.
Take a look at the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram Channel and LinkedIn GrAbove!. If you like our work, you will love our fact sheet..
Don't forget to join our Subreddit with over 48 billion users
Find upcoming ai webinars here

Shoaib Nazir is a Consulting Intern at MarktechPost and has completed his dual M.tech degree from Indian Institute of technology (IIT) Kharagpur. Being passionate about data science, he is particularly interested in the various applications of artificial intelligence in various domains. Shoaib is driven by the desire to explore the latest technological advancements and their practical implications in everyday life. His enthusiasm for innovation and solving real-world problems fuels his continuous learning and contribution to the field of ai.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>





{kind=link}