 NEWSLETTER
NEWSLETTER
Introducción
BERT, abreviatura de Representaciones de codificador bidireccional de Transformers, es un sistema que aprovecha el modelo de transformador y el entrenamiento previo no supervisado para el procesamiento del lenguaje natural. Al estar previamente capacitado, BERT aprende de antemano a través de dos tareas no supervisadas: modelado de lenguaje enmascarado y predicción de oraciones. Esto permite adaptar BERT para tareas específicas sin tener que empezar desde cero. Básicamente, BERT es un sistema previamente entrenado que utiliza un modelo único para comprender el lenguaje, simplificando su aplicación a diversas tareas. Entendamos el mecanismo de atención de BERT y su funcionamiento en este artículo.
Lea también: ¿Qué es BERT? ¡Haga clic aquí!
Objetivos de aprendizaje
- Comprender el mecanismo de atención en BERT
- ¿Cómo se realiza la tokenización en BERT?
- ¿Cómo se calculan los pesos de atención en BERT?
- Implementación en Python de un modelo BERT
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Mecanismo de atención en BERT
Comencemos por comprender qué significa atención en los términos más simples. La atención es una de las formas en que el modelo intenta darle más peso a aquellas características de entrada que son más importantes para una oración.
Consideremos los siguientes ejemplos para comprender cómo funciona fundamentalmente la atención.
Ejemplo 1
En la oración anterior, es posible que el modelo BERT quiera darle más importancia a la palabra “gato” y al verbo “saltó” que a “bolsa”, ya que conocerlos será más crítico para la predicción de la siguiente palabra “cayó” que saber dónde. el gato saltó.
Ejemplo 2
Considere la siguiente oración –

Para predecir la palabra “espagueti”, el mecanismo de atención permite dar más peso al verbo “comer” que a la cualidad “sosa” de los espaguetis.
Ejemplo 3
De manera similar, para un tarea de traducción como el siguiente:
Oración de entrada: Cómo estuvo su día
frase objetivo: Como has pasado el dia
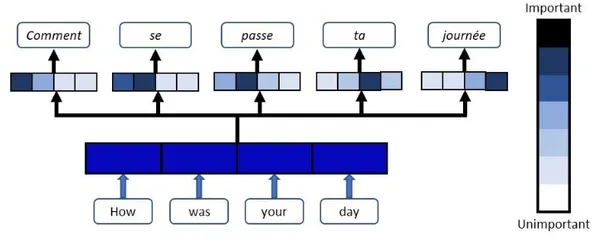
Para cada palabra en la frase de salida, el mecanismo de atención asignará las palabras significativas y pertinentes de la oración de entrada y les dará un peso mayor a estas palabras de entrada. En la imagen de arriba, observe cómo la palabra francesa “Comentario” asigna la ponderación más alta (representada en azul oscuro) a la palabra “Cómo” y, para la palabra “journee”, la palabra de entrada “día” recibe la ponderación más alta. Así es como el mecanismo de atención ayuda a lograr una mayor precisión de salida al otorgar más importancia a las palabras que son más críticas para la predicción relevante.
La pregunta que me viene a la mente es cómo el modelo asigna estos diferentes pesos a las diferentes palabras de entrada. Veamos en la siguiente sección cómo los pesos de atención habilitan este mecanismo exactamente.
Pesos de atención para representaciones compuestas
BERT utiliza pesos de atención para procesar secuencias. Considere una secuencia X que comprende tres vectores, cada uno con cuatro elementos. La función de atención transforma X en una nueva secuencia Y con la misma longitud. Cada vector Y es un promedio ponderado de los vectores X, con pesos denominados pesos de atención. Estos pesos aplicados a las incrustaciones de palabras de X producen incrustaciones compuestas en Y.
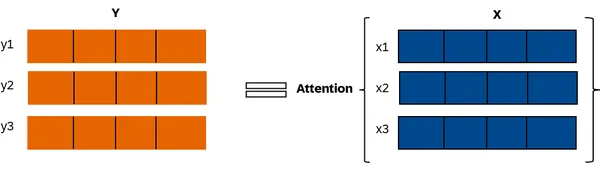
El cálculo de cada vector en Y se basa en diferentes pesos de atención asignados a x1, x2 y x3, dependiendo de la atención requerida para cada característica de entrada al generar el vector correspondiente en Y. Matemáticamente hablando, se vería como se muestra:
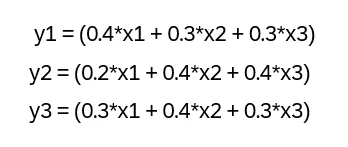
En las ecuaciones anteriores, los valores 0,4, 0,3 y 0,2 no son más que los diferentes pesos de atención asignados a x1, x2 y x3 para calcular las incorporaciones compuestas y1, y2 e y3. Como puede verse, los pesos de atención asignados a x1, x2 y x3 para calcular las incrustaciones compuestas son completamente diferentes para y1, y2 e y3.
La atención es fundamental para comprender el contexto de la oración, ya que permite al modelo comprender cómo se relacionan las diferentes palabras entre sí, además de comprender las palabras individuales. Por ejemplo, cuando un modelo de lenguaje intenta predecir la siguiente palabra en la siguiente oración
“El gato inquieto era ___”
El modelo debe comprender la noción compuesta de gato inquieto además de comprender los conceptos de gato inquieto o de gato individualmente; por ejemplo, el gato inquieto a menudo salta, por lo que saltar podría ser la siguiente palabra adecuada en la oración.
Claves y vectores de consulta para adquirir pesos de atención
A estas alturas sabemos que los pesos de atención ayudan a brindarnos representaciones compuestas de nuestras palabras de entrada mediante el cálculo de un promedio ponderado de las entradas con la ayuda de los pesos. Sin embargo, la siguiente pregunta que surge es de dónde provienen estos pesos de atención. Los pesos de atención provienen esencialmente de dos vectores conocidos con el nombre de vectores clave y de consulta.
BERT mide la atención entre pares de palabras mediante una función que asigna una puntuación a cada par de palabras en función de su relación. Utiliza vectores clave y de consulta como incrustaciones de palabras para evaluar la compatibilidad. La puntuación de compatibilidad se calcula tomando el producto escalar del vector de consulta de una palabra y el vector clave de la otra. Por ejemplo, calcula la puntuación entre 'saltar' y 'gato' utilizando el producto escalar del vector de consulta (q1) de 'saltar' y el vector clave (k2) de 'gato' – q1*k2.
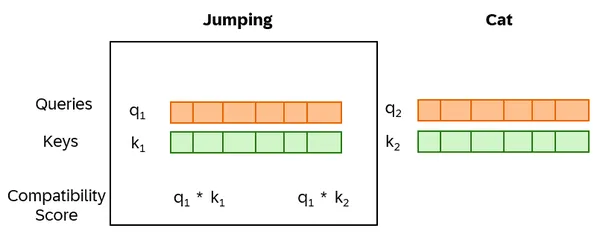
Para convertir las puntuaciones de compatibilidad en pesos de atención válidos, es necesario normalizarlas. BERT hace esto aplicando la función softmax a estas puntuaciones, asegurándose de que sean positivas y totales de uno. Los valores resultantes son los pesos de atención finales para cada palabra. En particular, los vectores clave y de consulta se calculan dinámicamente a partir de la salida de la capa anterior, lo que permite a BERT ajustar su mecanismo de atención según el contexto específico.
Jefes de atención en BERT
BERT aprende múltiples mecanismos de atención que se conocen como cabezas. Estos jefes trabajan juntos al mismo tiempo al mismo tiempo. Tener varias cabezas ayuda a BERT a comprender mejor las relaciones entre las palabras que si solo tuviera una cabeza.
BERT divide sus parámetros de consulta, clave y valor en N formas. Cada uno de estos N pares pasa de forma independiente a través de un cabezal independiente y realiza cálculos de atención. Los resultados de estos pares luego se combinan para generar una puntuación de Atención final. Es por eso que se denomina “atención de múltiples cabezas”, lo que proporciona a BERT una capacidad mejorada para capturar múltiples relaciones y matices para cada palabra.
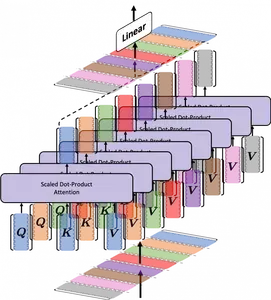
BERT también acumula múltiples capas de atención. Cada capa toma el resultado de la capa anterior y le presta atención. Al hacer esto muchas veces, BERT puede crear representaciones muy detalladas a medida que profundiza en el modelo.
Dependiendo del modelo BERT específico, hay 12 o 24 capas de atención y cada capa tiene 12 o 16 cabezas de atención. Esto significa que un solo modelo BERT puede tener hasta 384 mecanismos de atención diferentes porque los pesos no se comparten entre capas.
Implementación en Python de un modelo BERT
Paso 1. Importe las bibliotecas necesarias
Necesitaríamos importar la biblioteca de Python 'torch' para poder usar PyTorch. También necesitaríamos importar BertTokenizer y BertForSequenceClassification de la biblioteca de transformadores. La biblioteca tokenizer ayuda a habilitar la tokenización del texto, mientras que BertForSequenceClassification para la clasificación de texto.
import torch
from transformers import BertTokenizer, BertForSequenceClassificationPaso 2. Cargue el tokenizador y el modelo BERT previamente entrenado
En este paso, cargamos el modelo preentrenado “bert-base-uncased” y lo alimentamos al método from_pretrained de BertForSequenceClassification. Como aquí queremos llevar a cabo una clasificación de sentimientos simple, configuramos num_labels como 2, que representa “clase positiva” y “clase negativa”.
model_name="bert-base-uncased"
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForSequenceClassification.from_pretrained(model_name, num_labels=2)
Paso 3. Configure el dispositivo en GPU si está disponible
Este paso es solo para cambiar el dispositivo a GPU si está disponible o para quedarse con la CPU.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)
#import csvPaso 4. Definir el texto de entrada y tokenizar
En este paso definimos el texto de entrada para el que queremos realizar la clasificación. También definimos el objeto tokenizador que se encarga de convertir texto en una secuencia de tokens, que son las unidades básicas de información que los modelos de aprendizaje automático pueden comprender. El parámetro 'max_length' establece la longitud máxima de la secuencia tokenizada. Si la secuencia tokenizada excede esta longitud, el sistema la truncará. El parámetro 'relleno' dicta que la secuencia tokenizada se rellenará con ceros para alcanzar la longitud máxima si es más corta. El parámetro “truncamiento” indica si se truncará la secuencia tokenizada si excede la longitud máxima.
Dado que este parámetro está establecido en Verdadero, la secuencia se truncará si es necesario. El parámetro “return_tensors” especifica el formato en el que devolver la secuencia tokenizada. En este caso, la función devuelve la secuencia como un tensor de PyTorch. Luego mueve los 'input_ids' y 'attention_mask' de los tokens generados al dispositivo especificado. La máscara de atención, analizada anteriormente, es un tensor binario que indica a qué partes de la secuencia de entrada prestar más atención para una tarea de predicción específica.
text = "I did not really enjoyed this movie. It was fantastic!"
#Tokenize the input text
tokens = tokenizer.encode_plus(
text,
max_length=128,
padding='max_length',
truncation=True,
return_tensors="pt"
)
# Move input tensors to the device
input_ids = tokens('input_ids').to(device)
attention_mask = tokens('attention_mask').to(device)
#import csvPaso 5. Realizar predicción de sentimiento
En el siguiente paso, el modelo genera la predicción para los input_ids ycare_mask dados.
with torch.no_grad():
outputs = model(input_ids, attention_mask)
predicted_label = torch.argmax(outputs.logits, dim=1).item()
sentiment="positive" if predicted_label == 1 else 'negative'
print(f"The sentiment of the input text is {sentiment}.")
#import csvProducción
The sentiment of the input text is Positive.
Conclusión
Este artículo cubrió la atención en BERT y destacó su importancia para comprender el contexto de la oración y las relaciones entre las palabras. Exploramos las ponderaciones de atención, que brindan representaciones compuestas de palabras de entrada a través de promedios ponderados. El cálculo de estos pesos involucra vectores clave y de consulta. BERT determina la puntuación de compatibilidad entre dos palabras tomando el producto escalar de estos vectores. Este proceso, conocido como “cabezas”, es la forma en que BERT se centra en las palabras. Múltiples cabezas de atención mejoran la comprensión de BERT de las relaciones entre palabras. Finalmente, analizamos la implementación en Python de un modelo BERT previamente entrenado.
Conclusiones clave
- BERT se basa en dos avances cruciales de la PNL: la arquitectura transformadora y el entrenamiento previo no supervisado.
- Utiliza la “atención” para priorizar las características de entrada relevantes en las oraciones, lo que ayuda a comprender las relaciones entre palabras y los contextos.
- Las ponderaciones de atención calculan un promedio ponderado de entradas para representaciones compuestas. El uso de múltiples cabezas y capas de atención permite a BERT crear representaciones de palabras detalladas centrándose en las salidas de las capas anteriores.
Preguntas frecuentes
A. BERT, abreviatura de Representaciones de codificador bidireccional de Transformers, es un sistema que aprovecha el modelo de transformador y el entrenamiento previo no supervisado para el procesamiento del lenguaje natural.
R. Se somete a un entrenamiento previo, aprendiendo de antemano a través de dos tareas no supervisadas: modelado de lenguaje enmascarado y predicción de oraciones.
R. Utilice modelos BERT para una variedad de aplicaciones en PNL que incluyen, entre otras, clasificación de texto, análisis de sentimientos, respuesta a preguntas, resumen de texto, traducción automática, revisión ortográfica y gramatical, y recomendación de contenido.
R. La autoatención es un mecanismo en el modelo BERT (y otros modelos basados en transformadores) que permite que cada palabra en la secuencia de entrada interactúe con todas las demás palabras. Permite que el modelo tenga en cuenta todo el contexto de la oración, en lugar de simplemente mirar las palabras de forma aislada o dentro de un tamaño de ventana fijo.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.






{kind=link}