 NEWSLETTER
NEWSLETTER
Tras el innovador impacto de Deepseek R1, Deepseek ai continúa empujando los límites de la innovación con su última oferta: Smallpond. Este marco de procesamiento de datos liviano combina la potencia de DuckDB para SQL Analytics y 3FS para el almacenamiento distribuido de alto rendimiento, diseñado para manejar eficientemente los conjuntos de datos a escala de petabyte. Smallpond promete simplificar el procesamiento de datos para aplicaciones de IA y Big Data, eliminando la necesidad de servicios de larga duración e infraestructura compleja, marcando otro salto significativo del equipo de Deepseek. En este artículo, exploraremos las características, componentes y aplicaciones del marco de pequeños de Deepseek ai, y también aprenderemos cómo usarlo.
Objetivos de aprendizaje
- Aprenda qué es DeepSeek Smallpond y cómo se extiende DuckDB para el procesamiento de datos distribuidos.
- Comprenda cómo instalar Smallpond, configurar grupos de rayos y configurar un entorno informático.
- Aprenda a ingerir, procesar y particionar datos utilizando la API de Smallpond.
- Identifique casos de uso prácticos como capacitación de IA, análisis financiero y procesamiento de registros.
- Pese las ventajas y los desafíos del uso de Smallpond para análisis distribuidos.
Este artículo fue publicado como parte del Blogathon de ciencias de datos.
¿Qué es Deepseek Sbowpond?
Smallpond es un marco de procesamiento de datos liviano y de código abierto desarrollado por Deepseek ai, diseñado para extender las capacidades de DuckDB, una base de datos analítica de alto rendimiento y en proceso, en entornos distribuidos.
Al integrar DuckDB con el sistema de archivos Fire-Flyer (3FS), Smallpond ofrece una solución escalable para manejar conjuntos de datos a escala de petabyte sin la sobrecarga de marcos tradicionales de big data como Apache Spark.
Lanzado el 28 de febrero de 2025, como parte de la Semana de Open Source de Deepseek, SmallPond se dirige a ingenieros de datos y científicos que necesitan herramientas eficientes, simples y de alto rendimiento para análisis distribuidos.
Obtenga más información: Deepseek liberaciones 3FS y marco de pequeños
Características clave de Smallpond
- Rendimiento alto: Aprovecha el motor SQL nativo de DuckDB y el rendimiento de 3FS múltiple por minuto por minuto.
- Escalabilidad: Procesa datos a escala de petabyte en nodos distribuidos con partición manual.
- Sencillez: No hay servicios de larga duración o dependencias complejas: desplegar y usar con una configuración mínima.
- Flexibilidad: Admite Python (3.8–3.12) y se integra con Ray para el procesamiento paralelo.
- Código abierto: MIT licenciado, fomentando las contribuciones y la personalización de la comunidad.
Componentes centrales de Deepseek Sboinpond
Ahora comprendamos los componentes centrales del marco pequeño de Deepseek.
Duckdb
DuckDB es una base de datos OLAP SQL integrada y en proceso optimizada para cargas de trabajo analíticas. Se destaca en la ejecución de consultas complejas en grandes conjuntos de datos con una latencia mínima, por lo que es ideal para análisis de nodos únicos. Smallpond extiende las capacidades de DuckDB a los sistemas distribuidos, conservando sus beneficios de rendimiento.
3FS (sistema de archivos de flyer de fuego)
3FS es un sistema de archivos distribuido diseñado por Deepseek para ai y cargas de trabajo informáticas de alto rendimiento (HPC). Aprovecha las redes modernas de SSDS y RDMA para ofrecer un almacenamiento de bajo rendimiento de alto nivel (por ejemplo, 6.6 TIB/s de rendimiento de lectura en un clúster de 180 nodos). A diferencia de los sistemas de archivos tradicionales, 3FS prioriza las lecturas aleatorias sobre el almacenamiento en caché, alineándose con las necesidades de capacitación y análisis de IA.
Integración de DuckDB y 3FS en Smallpond
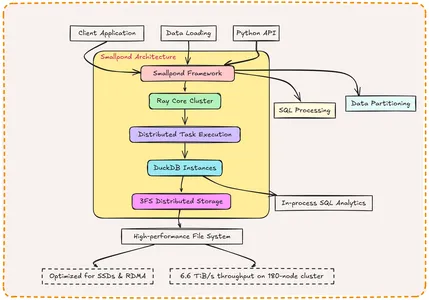
Smallpond usa DuckDB como motor de cómputo y 3FS como columna vertebral de almacenamiento. Los datos se almacenan en formato Parquet en 3FS, divididos manualmente por los usuarios y se procesan en paralelo a través de nodos utilizando instancias de DuckDB coordinadas por Ray. Esta integración combina la eficiencia de consulta de DuckDB con el almacenamiento escalable de 3FS, lo que permite un análisis distribuido sin interrupciones.
Comenzando con Sbowpond
Ahora, aprendamos a instalar y usar Smallpond.
Paso 1: Instalación
Smallpond está basado en Python e instalable a través de PIP disponible solo para Linux Distros. Asegúrese de que se instale Python 3.8–3.11, junto con un clúster 3FS compatible (o sistema de archivos local para las pruebas).
# Install Smallpond with dependecies
pip install smallpond
# Optional: Install development dependencies (e.g., for testing)
pip install "smallpond(dev)"
# Install Ray Clusters
pip install 'ray(default)'Para 3FS, clon y construya desde el repositorio de GitHub:
git clone https://github.com/deepseek-ai/3fs
cd 3fs
git submodule update --init --recursive
./patches/apply.sh
# Install dependencies (Ubuntu 20.04/22.04 example)
sudo apt install cmake libuv1-dev liblz4-dev libboost-all-dev
# Build 3FS (refer to 3FS docs for detailed instructions)Paso 2: Configuración del entorno
Inicialice una instancia de rayos para grupos de rayos si usa 3FS, siga los códigos a continuación:
#intialize ray accordingly
ray start --head --num-cpus= --num-gpus=Ejecutar el código anterior producirá una salida similar a la imagen a continuación:
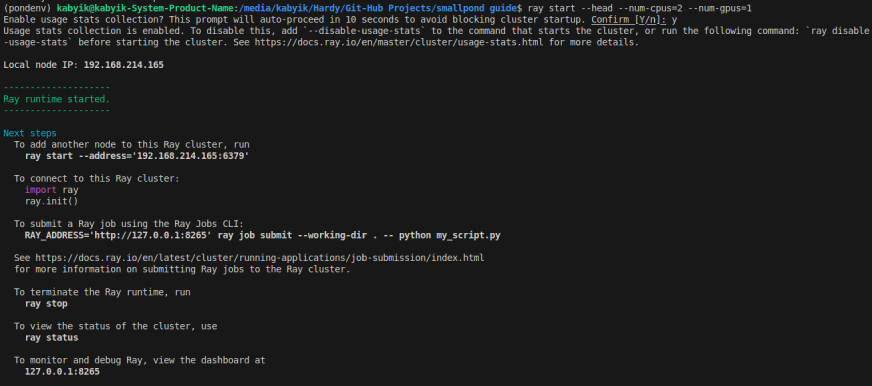
Ahora podemos inicializar a Ray con 3FS usando la dirección que obtuvimos como se muestra arriba. Para inicializar el rayo en Smallpond, configure un clúster de cómputo (por ejemplo, AWS EC2, en las instalaciones) con 3F implementados en nodos equipados con SSD o para pruebas locales (Linux/Ubuntu), use una ruta del sistema de archivos.
import smallpond
# Initialize Smallpond session (local filesystem for testing)
sp = smallpond.init(data_root="Path/to/local/Storage",ray_address="192.168.214.165:6379")# Enter your own ray address
# For 3FS cluster (update with your 3FS endpoint and ray address)
sp = smallpond.init(data_root="3fs://cluster_endpoint",ray_address="192.168.214.165:6379")# Enter your own ray address
Paso 3: Ingestión y preparación de datos
Formatos de datos compatibles
Smallpond admite principalmente archivos de parquet, optimizados para el almacenamiento columnar y la compatibilidad de DuckDB. Otros formatos (por ejemplo, CSV) pueden ser compatibles con las capacidades nativas de DuckDB.
Lectura y escritura de datos
Cargue y guarde datos utilizando la API de alto nivel de Smallpond.
# Read Parquet file
df = sp.read_parquet("data/input.prices.parquet")
# Process data (example: filter rows)
df = df.map("price > 100") # SQL-like syntax
# Write results back to Parquet
df.write_parquet("data/output/filtered.prices.parquet")Estrategias de partición de datos
La partición manual es clave para la escalabilidad de Smallpond. Elija una estrategia basada en sus datos y carga de trabajo:
- Por recuento de archivos: Dividirse en un número fijo de archivos.
- Por filas: Distribuir filas uniformemente.
- Por hash: Partición basada en el hash de una columna para la distribución equilibrada.
# Partition by file count
df = df.repartition(3)
# Partition by rows
df = df.repartition(3, by_row=True)
# Partition by column hash (e.g., ticker)
df = df.repartition(3, hash_by="ticker")Paso 4: Referencia de API
Descripción general de la API de alto nivel
La API de alto nivel simplifica la carga de datos, la transformación y el ahorro:
- Read_parquet (ruta) : Carga los archivos parquet.
- write_parquet (ruta) : Guarda datos procesados.
- REPARTITION (n, (by_row, hash_by)) : Datos de particiones.
- Mapa (Expr) : Aplica transformaciones.
Descripción general de la API de bajo nivel
Para uso avanzado, Smallpond integra el motor SQL de DuckDB y la distribución de tareas de Ray directamente:
- Ejecutar SQL RAW a través de parcial_sql
- Administre tareas de rayos para el paralelismo personalizado.
Descripciones de funciones detalladas
- sp.read_parquet (ruta): Lee archivos de Parquet en un DataFrame distribuido.
df = sp.read_parquet("3fs://data/input/*.parquet")- DF.MAP (EXPR): aplica transformaciones similares a SQL o Python.
# SQL-like
df = df.map("SELECT ticker, price * 1.1 AS adjusted_price FROM artificial intelligence")
# Python function
df = df.map(lambda row: {"adjusted_price": row("price") * 1.1})- DF.Partial_SQL (Query, DF): ejecuta SQL en un marcado de datos
df = sp.partial_sql("SELECT ticker, MIN(price), MAX(price) FROM artificial intelligence GROUP BY ticker", df)Puntos de referencia de rendimiento
El rendimiento de Smallpond brilla en puntos de referencia como Graysort, clasificando 110.5 TIB en 8,192 particiones en 30 minutos y 14 segundos (3.66 TIB/Min Wearnip) en un clúster de cómputo de 50 nodos con 25 nodos de almacenamiento de 3FS.
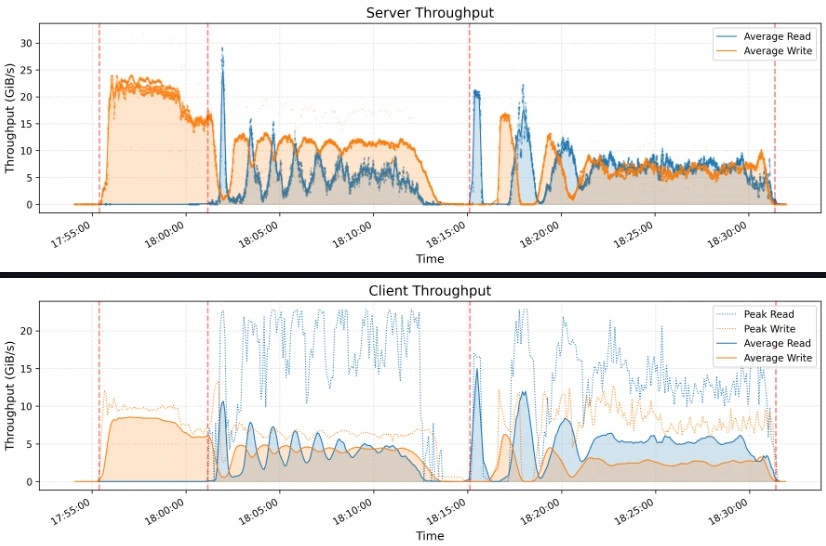
Las mejores prácticas para optimizar el rendimiento
- Partición sabiamente: Haga coincidir el tamaño de la partición con la memoria del nodo y la carga de trabajo.
- Apalancamiento 3FS: Use SSDS y RDMA para el máximo rendimiento de E/S.
- Minimizar barajando: Datos previos a la participación para reducir la sobrecarga de la red.
Consideraciones de escalabilidad
- 10TB – 1PB: Ideal para Smallpond con un clúster modesto.
- Más de 1PB: Requiere una infraestructura significativa (p. Ej., 180+ nodos).
- Gestión del clúster: Utilice los servicios de rayos administrados (por ejemplo, AnyScale) para simplificar la escala.
Aplicaciones de Smallpond
- Precrocesamiento de datos de IA: Prepare conjuntos de datos de capacitación a escala de petabyte.
- Análisis financiero: Agregue y analice los datos del mercado en los nodos distribuidos.
- Procesamiento de registro: El servidor de procesos registra en paralelo para información en tiempo real.
- Entrenamiento de IA de Deepseek: Usó un pequeñopondo y 3FS para clasificar 110.5 TIB en menos de 31 minutos, lo que respalda un entrenamiento de modelos eficiente.
Ventajas y desventajas de Smallpond
| Característica | Ventajas | Desventajas |
|---|---|---|
| Escalabilidad | Maneja los datos a escala de petabyte de manera eficiente | Gastos generales de gestión de clúster |
| Actuación | Excelente rendimiento de referencia | Puede no optimizar el rendimiento de un solo nodo |
| Costo | De código abierto y rentable | Dependencia de los marcos externos |
| Usabilidad | API fácil de usar para desarrolladores de ML | Preocupaciones de seguridad relacionadas con los modelos de IA de Deepseek |
| Arquitectura | Computación distribuida con DuckDB y Ray Core | Ninguno |
Conclusión
Smallpond redefine el procesamiento de datos distribuidos combinando la destreza analítica de DuckDB con el almacenamiento de alto rendimiento de 3FS. Su simplicidad, escalabilidad y naturaleza de código abierto lo convierten en una elección convincente para los flujos de trabajo de datos modernos. Ya sea que esté preprocesando conjuntos de datos de IA o analizando terabytes de registros, Smallpond ofrece una solución liviana pero poderosa. ¡Bucee, experimente con el código y únase a la comunidad para dar forma a su futuro!
Control de llave
- Smallpond es un marco de procesamiento de datos distribuido y de código abierto que extiende las capacidades SQL de DuckDB utilizando 3F y Ray.
- Actualmente es compatible con Linux Discoss y requiere Python 3.8–3.12.
- Smallpond es ideal para el preprocesamiento de IA, el análisis financiero y las cargas de trabajo de Big Data, pero requiere una gestión de clúster cuidadosa.
- Es una alternativa rentable a Apache Spark, con una sobrecarga más baja y facilidad de implementación.
- A pesar de sus ventajas, requiere consideraciones de infraestructura, como la configuración del clúster y las preocupaciones de seguridad con los modelos de Deepseek.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se usan a discreción del autor.
Preguntas frecuentes
A. Deepseek Smallpond es un marco de procesamiento de datos liviano y de código abierto que extiende las capacidades de DuckDB a entornos distribuidos utilizando 3F para almacenamiento escalable y rayos para procesamiento paralelo.
A. Smallpond es una alternativa liviana a Spark, que ofrece análisis distribuidos de alto rendimiento sin dependencias complejas. Sin embargo, requiere división manual y configuración de infraestructura, a diferencia de la gestión de recursos incorporados de Spark.
A. Smallpond requiere Python (3.8–3.12), un sistema operativo basado en Linux y un clúster de 3FS compatible o almacenamiento local. Para las cargas de trabajo distribuidas, se recomienda un clúster de rayos con nodos equipados con SSD.
A. Smallpond admite principalmente archivos de parquet para un almacenamiento columnar optimizado, pero puede manejar otros formatos a través de las capacidades nativas de DuckDB.
R. Las mejores prácticas incluyen partición de datos manual basada en la carga de trabajo, aprovechando 3F para almacenamiento de alta velocidad y minimizando los datos que se arrastran en los nodos para reducir la sobrecarga de la red.
A. Smallpond sobresale en el procesamiento por lotes, pero puede no ser ideal para análisis en tiempo real. Para los datos de transmisión de baja latencia, los marcos alternativos como Apache Flink o Kafka Streams podrían ser más adecuados.

¡Hola! Soy Kabyik Kayal, un chico de 20 años de Kolkata. Me apasiona la ciencia de datos, el desarrollo web y la exploración de nuevas ideas. Mi viaje me ha llevado a través de 3 escuelas diferentes en Bengala Occidental y actualmente en IIT Madras, donde desarrollé una base sólida en la resolución de problemas, la ciencia de datos y la informática y la mejora continua. También me fascina la fotografía, los juegos, la música, la astronomía y el aprendizaje de diferentes idiomas. Siempre estoy ansioso por aprender y crecer, y estoy emocionado de compartir un poco de mi mundo contigo aquí. ¡Siéntete libre de explorar! Y si tiene problemas con sus tareas relacionadas con los datos, no dude en conectarse
Inicie sesión para continuar leyendo y disfrutando de contenido curado por expertos.





