 NEWSLETTER
NEWSLETTER
Como defensor del desarrollador, es difícil mantenerse al día con los mensajes del foro de usuarios y comprender el panorama general de lo que los usuarios están diciendo. Hay mucho contenido valioso, pero ¿cómo puede detectar rápidamente las conversaciones clave? ¡En este tutorial, te mostraré un hack de IA para realizar la agrupación semántica simplemente al solicitar LLM!
TL; DR Esta publicación de blog trata sobre cómo pasar de (Data Science + Code) → (ai Solts + LLMS) para los mismos resultados, ¡solo más rápido y con menos esfuerzo! . Está organizado de la siguiente manera:
- Fuentes de inspiración y datos
- Explorando los datos con paneles
- LLM solicitando producir grupos KNN
- Experimentar con incrustaciones personalizadas
- Agrupación en múltiples servidores de discordia
Fuentes de inspiración y datos
Primero, daré accesorios para el documento de diciembre de 2024 Clio (Claude ideas y observaciones)una plataforma de preservación de la privacidad que utiliza asistentes de IA para analizar y los patrones de uso agregados de superficie en millones de conversaciones. Leer este artículo me inspiró a probar esto.
Datos. Usé solo públicamente disponible Discordia Mensajes, específicamente “hilos de foro”, donde los usuarios solicitan ayuda tecnológica. Además, agregué y anononizé contenido para este blog. Por hilo, formateé los datos en formato de giro de conversación, con roles de usuario identificados como “usuario”, haciendo la pregunta o “asistente”, cualquier persona que responda la pregunta inicial del usuario. También agregué un puntaje de sentimiento binario simple y codificado (0 para “no feliz” y 1 para “feliz”) basado en si el usuario dijo gracias en cualquier momento en su hilo. Para los proveedores de vectordb usé Zilliz/Milvus, Chroma y Qdrant.
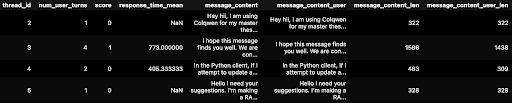
El primer paso fue convertir los datos en un marco de datos de Pandas. A continuación se muestra un extracto. Puede ver para Thread_id = 2, un usuario solo hizo 1 pregunta. Pero para Thread_id = 3, un usuario hizo 4 preguntas diferentes en el mismo hilo (otras 2 preguntas en las marcas de tiempo más abajo, no se muestran a continuación).
Agregué una función ingenua de puntuación del sentimiento 0 | 1.
def calc_score(df):
# Define the target words
target_words = ("thanks", "thank you", "thx", "", "", "")
# Helper function to check if any target word is in the concatenated message content
def contains_target_words(messages):
concatenated_content = " ".join(messages).lower()
return any(word in concatenated_content for word in target_words)
# Group by 'thread_id' and calculate score for each group
thread_scores = (
df(df('role_name') == 'user')
.groupby('thread_id')('message_content')
.apply(lambda messages: int(contains_target_words(messages)))
)
# Map the calculated scores back to the original DataFrame
df('score') = df('thread_id').map(thread_scores)
return df
...
if __name__ == "__main__":
# Load parameters from YAML file
config_path = "config.yaml"
params = load_params(config_path)
input_data_folder = params('input_data_folder')
processed_data_dir = params('processed_data_dir')
threads_data_file = os.path.join(processed_data_dir, "thread_summary.csv")
# Read data from Discord Forum JSON files into a pandas df.
clean_data_df = process_json_files(
input_data_folder,
processed_data_dir)
# Calculate score based on specific words in message content
clean_data_df = calc_score(clean_data_df)
# Generate reports and plots
plot_all_metrics(processed_data_dir)
# Concat thread messages & save as CSV for prompting.
thread_summary_df, avg_message_len, avg_message_len_user = \
concat_thread_messages_df(clean_data_df, threads_data_file)
assert thread_summary_df.shape(0) == clean_data_df.thread_id.nunique()
Explorando los datos con paneles
De los datos procesados anteriores, construí paneles tradicionales:
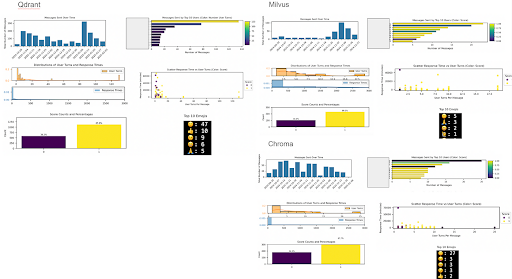
- Volúmenes de mensajes: Picos únicos en proveedores como Qdrant y Milvus (posiblemente debido a eventos de marketing).
- Participación del usuario: Los principales gráficos de barras de los usuarios y diagramas de dispersión del tiempo de respuesta frente al número de giros de los usuarios muestran que, en general, más giros del usuario significan una mayor satisfacción. Pero, la satisfacción no se ve correlacionada con el tiempo de respuesta. Los puntos oscuros de dispersión parecen aleatorios con respecto al eje y (tiempo de respuesta). ¿Quizás los usuarios no están en producción, sus preguntas no son muy urgentes? Existen atípicos, como Qdrant y Chroma, que pueden tener anomalías impulsadas por BOT.
- Tendencias de satisfacción: Alrededor del 70% de los usuarios parecen felices de tener alguna interacción. Nota de datos: asegúrese de verificar los emojis por proveedor, a veces los usuarios responden usando emojis en lugar de palabras. Ejemplo Qdrant y Chroma.
LLM solicitando producir grupos KNN
Para solicitar, el siguiente paso fue agregar datos por Thread_id. Para LLMS, necesita los textos concatenados juntos. Separo mensajes de usuario de mensajes completos de subprocesos para ver si uno u otro produciría mejores grupos. Terminé usando solo mensajes de usuario.
Con un archivo CSV para solicitar, ¡está listo para comenzar a usar un LLM para hacer ciencia de datos!
!pip install -q google.generativeai
import os
import google.generativeai as genai
# Get API key from local system
api_key=os.environ.get("GOOGLE_API_KEY")
# Configure API key
genai.configure(api_key=api_key)
# List all the model names
for m in genai.list_models():
if 'generateContent' in m.supported_generation_methods:
print(m.name)
# Try different models and prompts
GEMINI_MODEL_FOR_SUMMARIES = "gemini-2.0-pro-exp-02-05"
model = genai.GenerativeModel(GEMINI_MODEL_FOR_SUMMARIES)
# Combine the prompt and CSV data.
full_input = prompt + "\n\nCSV Data:\n" + csv_data
# Inference call to Gemini LLM
response = model.generate_content(full_input)
# Save response.text as .json file...
# Check token counts and compare to model limit: 2 million tokens
print(response.usage_metadata)

Lamentablemente, la API de Géminis siguió cortando el response.text. Tuve mejor suerte usando Para estudiar directamente.

Mis 5 indicaciones para <a target="_blank" href="https://ai.google.dev/gemini-api/docs/models/gemini”>Géminis Flash & Pro (La temperatura establecida en 0) están debajo.
Aviso#1: Obtenga resúmenes de hilo:
Dado este archivo .csv, por fila, agregue 3 columnas:
– Thread_summary = 205 caracteres o menos resumen de la columna de la fila 'Message_Content'
– user_thread_summary = 126 caracteres o menos resumen de la columna de la fila 'Message_content_user'
-Thread_topic = 3–5 Word Categoría de Super Alto nivel
Asegúrese de que los resúmenes capturen el contenido principal sin perder demasiados detalles. Haga resúmenes de hilo de usuario directamente al punto, capture el contenido principal sin perder demasiados detalles, omita el texto de introducción. Si un resumen más corto es lo suficientemente bueno, prefiera el resumen más corto. Asegúrese de que el tema sea lo suficientemente general como para que haya menos de 20 temas de alto nivel para todos los datos. Prefiere menos temas. Salidas de salida JSON: Thread_id, Thread_summary, user_thread_summary, thread_topic.
Aviso#2: Obtener estadísticas de clúster:
Dado este archivo de mensajes CSV, use column = 'user_thread_summary' para realizar la agrupación semántica de todas las filas. Use técnica = Silhouette, con método de enlace = Ward y Distance_Metric = Cosine Simility. Solo dame las estadísticas para el análisis de silueta del método por ahora.
Aviso#3: Realizar la agrupación inicial:
Dado este archivo de mensajes CSV, use columna = 'user_thread_summary' para realizar la agrupación semántica de todas las filas en clústeres n = 6 utilizando el método Silhouette. Use columna = “Thread_topic” para resumir cada tema de clúster en 1–3 palabras. Salida JSON con columnas: thread_id, nivel0_cluster_id, nivel0_cluster_topic.
Puntaje de silueta mide cuán similar es un objeto a su propio grupo (cohesión) versus otros grupos (separación). Los puntajes varían de -1 a 1. Una puntuación de silueta promedio más alta generalmente indica grupos mejor definidos con buena separación. Para más detalles, consulte el documentación de puntaje de silueta de scikit-learn.
Aplicándolo a los datos de Chroma. A continuación, muestro resultados de la pronta#2, como una trama de puntajes de silueta. Elegí N = 6 clústeres como un compromiso entre la puntuación alta y menos grupos. La mayoría de las LLM en estos días para el análisis de datos toman la entrada como CSV y salida JSON.
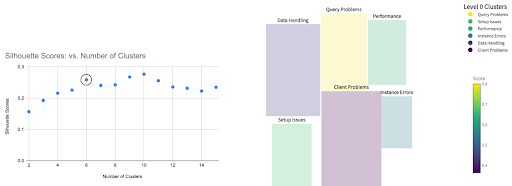
De la trama anterior, ¡puedes ver que finalmente nos estamos metiendo en la carne de lo que dicen los usuarios!
Aviso#4: Obtener estadísticas jerárquicas del clúster:
Dado este archivo de mensajes CSV, use la columna = 'Thread_summary_user' para realizar la agrupación semántica de todas las filas en la agrupación jerárquica (aglomerativa) con 2 niveles. Use el puntaje de silueta. ¿Cuál es el número óptimo de los siguientes clústeres de nivel 0 y nivel1? ¿Cuántos hilos por clúster de nivel1? Solo dame las estadísticas por ahora, haremos la agrupación real más tarde.
Aviso#5: Realizar agrupación jerárquica:
Acepte esta agrupación con 2 niveles. Agregue temas de clúster que resuman la columna de texto “Thread_topic”. Los temas de clúster deben ser lo más cortos posible sin perder demasiados detalles en el significado del clúster.
– Temas de clúster de nivel 0 ~ 1–3 palabras.
– Temas de clúster nivel1 ~ 2–5 palabras.
Salida JSON con columnas: thread_id, nivel0_cluster_id, nivel0_cluster_topic, nivel1_cluster_id, nivel1_cluster_topic.
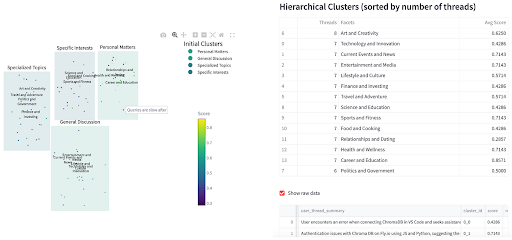
También solicité que genere un código a paso a luz para visualizar los clústeres (ya que no soy un experto en JS ). Los resultados para los mismos datos de croma se muestran a continuación.

Encontré esto muy perspicaz. Para Chroma, la agrupación reveló que, si bien los usuarios estaban contentos con temas como la consulta, la distancia y el rendimiento, no estaban contentos con las áreas como datos, cliente e implementación.
Experimentar con incrustaciones personalizadas
Repetí las indicaciones de agrupación anteriores, utilizando solo la incrustación numérica (“user_embedding”) en el CSV en lugar de los resúmenes de texto sin procesar (“user_text”). He explicado incrustaciones en detalle anteriormente blogs Antes, y los riesgos de los modelos de sobre fáctica en las tablas de clasificación. OpenAi tiene confiable incrustaciones que son extremadamente asequibles por API Call. A continuación se muestra un fragmento de código de ejemplo cómo crear incrustaciones.
from openai import OpenAI
EMBEDDING_MODEL = "text-embedding-3-small"
EMBEDDING_DIM = 512 # 512 or 1536 possible
# Initialize client with API key
openai_client = OpenAI(
api_key=os.environ.get("OPENAI_API_KEY"),
)
# Function to create embeddings
def get_embedding(text, embedding_model=EMBEDDING_MODEL,
embedding_dim=EMBEDDING_DIM):
response = openai_client.embeddings.create(
input=text,
model=embedding_model,
dimensions=embedding_dim
)
return response.data(0).embedding
# Function to call per pandas df row in .apply()
def generate_row_embeddings(row):
return {
'user_embedding': get_embedding(row('user_thread_summary')),
}
# Generate embeddings using pandas apply
embeddings_data = df.apply(generate_row_embeddings, axis=1)
# Add embeddings back into df as separate columns
df('user_embedding') = embeddings_data.apply(lambda x: x('user_embedding'))
display(df.head())
# Save as CSV ...

Curiosamente, tanto Perplexity Pro como Gemini 2.0 Pro a veces temas de clúster alucinados (por ejemplo, clasificar erróneamente una pregunta sobre consultas lentas como “materia personal”).
Conclusión: al realizar NLP con indicaciones, deje que el LLM genere sus propias incrustaciones: los incrustaciones generadas externamente parecen confundir el modelo.
Agrupación en múltiples servidores de discordia
Finalmente, amplié el análisis para incluir mensajes de discordia de tres proveedores de VectordB diferentes. La visualización resultante destacó problemas comunes, como Milvus y Chroma que enfrentan problemas de autenticación.
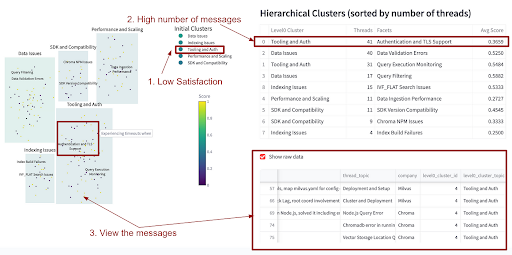
Resumen
Aquí hay un resumen de los pasos que seguí para realizar la agrupación semántica usando las indicaciones de LLM:
- Extraer hilos de discordia.
- Los datos de formateo en conversación giran con roles (“usuario”, “asistente”).
- Sentimiento de puntaje y ahorre como CSV.
- Solicite Google Gemini 2.0 Flash para resúmenes de hilos.
- PROMEDIA PERPEXITY Pro o Gemini 2.0 Pro para la agrupación basada en resúmenes de hilos utilizando el mismo CSV.
- PROMEDIA PERPLEXITY Pro o Gemini 2.0 Pro para escribir Racionalizar Código para visualizar clústeres (porque no soy un experto en JS ).
Siguiendo estos pasos, puede transformar rápidamente los datos del foro sin procesar en ideas procesables: ¡lo que solía tomar días de codificación ahora se puede hacer en solo una tarde!
Referencias
- CLIO: Perspectivas de preservación de la privacidad sobre el uso de IA del mundo real, https://arxiv.org/abs/2412.13678
- Blog antrópico sobre clio, https://www.anthropic.com/research/clio
- Servidor de discordia de cometasúltimo acceso el 7 de febrero de 2025
Servidor de discordia de Chromaúltimo acceso el 7 de febrero de 2025
Servidor Qdrant Discordúltimo acceso el 7 de febrero de 2025 - Modelos Géminis, <a target="_blank" href="https://ai.google.dev/gemini-api/docs/models/gemini”>https://ai.google.dev/gemini-api/docs/models/gemini
- Blog sobre modelos Gemini 2.0, <a target="_blank" href="https://blog.google/technology/google-deepmind/gemini-model-updates-february-2025/”>https://blog.google/technology/google-deepmind/gemini-model-updates-february-2025/
- SCIKIT-Learn Silhouette Puntuación
- Opictaaia sedó a un memal
- Racionalizar





{kind=link}