 NEWSLETTER
NEWSLETTER
The development of Transformer models has significantly advanced artificial intelligence, offering remarkable performance in various tasks. However, these advances often come with high computational requirements, presenting challenges in terms of scalability and efficiency. Sparsely activated Mixture of Experts (MoE) architectures provide a promising solution, enabling increased model capacity without commensurate computational costs. However, traditional TopK+Softmax routing in MoE models faces notable limitations. The discrete and non-differentiable nature of TopK routing makes scalability and optimization difficult, while ensuring balanced expert utilization remains a persistent problem, leading to inefficiencies and suboptimal performance.
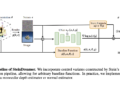
Researchers at Tsinghua University have proposed ReMoE (ReLU-based mixing of experts), a new architecture that addresses these limitations. ReMoE replaces conventional TopK+Softmax routing with a ReLU-based mechanism, enabling a fully differentiable routing process. This design simplifies the architecture and integrates seamlessly with existing MoE systems.
ReMoE employs ReLU activation functions to dynamically determine the active state of experts. Unlike TopK routing, which activates only top-k experts based on a discrete probability distribution, ReLU routing seamlessly transitions between active and inactive states. The sparsity of activated experts is controlled by adaptive L1 regularization, ensuring efficient computation while maintaining high performance. This differentiable design also allows for dynamic resource allocation between tokens and layers, adapting to the complexity of individual inputs.
Technical details and benefits
The innovation of ReMoE lies in its routing mechanism. By replacing TopK's discontinuous operation with a continuous ReLU-based approach, ReMoE eliminates abrupt changes in expert activation, ensuring smoother gradient updates and improved stability during training. Additionally, ReMoE's dynamic routing mechanism allows the number of active experts to be adjusted based on token complexity, promoting efficient resource utilization.
To address imbalances where some experts might remain underutilized, ReMoE incorporates an adaptive load balancing strategy into its L1 regularization. This refinement ensures a fairer distribution of token allocations among experts, improving the overall capacity and performance of the model. The scalability of the architecture is evident in its ability to handle larger numbers of experts and finer levels of granularity compared to traditional MoE models.
Performance information and experimental results
Extensive experiments demonstrate that ReMoE consistently outperforms conventional MoE architectures. The researchers tested ReMoE using the LLaMA architecture, training models of different sizes (parameters from 182M to 978M) with different numbers of experts (from 4 to 128). Key findings include:
- Improved performance: ReMoE achieves better validation loss and accuracy of downstream tasks compared to TopK-routed MoE models.
- Scalability: The performance gap between ReMoE and conventional MoE widens with an increasing number of experts, demonstrating the scalability of ReMoE.
- Efficient resource allocation: ReMoE dynamically allocates computational resources to more complex tokens, optimizing performance while maintaining efficiency.
For example, on downstream tasks such as ARC, BoolQ, and LAMBADA, ReMoE demonstrated measurable accuracy improvements compared to dense, TopK-routed MoE models. Training and inference performance analyzes revealed that ReMoE's differentiable design introduces minimal computational overhead, making it suitable for practical applications.
Conclusion
ReMoE marks a thoughtful advance in expert combination architectures by addressing the limitations of TopK+Softmax routing. The ReLU-based routing mechanism, combined with adaptive regularization techniques, ensures that ReMoE is efficient and adaptive. This innovation highlights the potential to revisit fundamental design choices to achieve better scalability and performance. By offering a practical, resource-aware approach, ReMoE provides a valuable tool for advancing ai systems to meet growing computational demands.
Verify he Paper and GitHub page. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on <a target="_blank" href="https://twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. Don't forget to join our SubReddit over 60,000 ml.
Trending: LG ai Research launches EXAONE 3.5 – three frontier-level bilingual open-source ai models that deliver unmatched instruction following and broad context understanding for global leadership in generative ai excellence….
Sana Hassan, a consulting intern at Marktechpost and a dual degree student at IIT Madras, is passionate about applying technology and artificial intelligence to address real-world challenges. With a strong interest in solving practical problems, he brings a new perspective to the intersection of ai and real-life solutions.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>




{kind=link}