 NEWSLETTER
NEWSLETTER
Los principales avances recientes en múltiples subcampos de la investigación del aprendizaje automático (ML), como la visión por computadora y el procesamiento del lenguaje natural, han sido posibles gracias a un enfoque común compartido que aprovecha conjuntos de datos grandes y diversos y modelos expresivos que pueden absorber todos los datos de manera efectiva. Aunque ha habido varios intentos Para aplicar este enfoque a la robótica, los robots aún no han aprovechado los modelos de alta capacidad ni otros subcampos.
Varios factores contribuyen a este desafío. Primero, está la falta de datos robóticos diversos y a gran escala, lo que limita la capacidad de un modelo para absorber un amplio conjunto de experiencias robóticas. La recopilación de datos es particularmente costosa y desafiante para la robótica porque la curación de conjuntos de datos requiere mucha ingeniería. autónomo operacióno demostraciones recopilados mediante teleoperaciones humanas. Un segundo factor es la falta de modelos expresivos, escalables y lo suficientemente rápidos para la inferencia en tiempo real que puedan aprender de dichos conjuntos de datos y generalizar de manera efectiva.
Para hacer frente a estos desafíos, proponemos la Transformador robótico 1 (RT-1), un modelo multitarea que tokeniza Las acciones de entrada y salida del robot (p. ej., imágenes de cámara, instrucciones de tareas y comandos de motor) para permitir una inferencia eficiente en tiempo de ejecución, lo que hace factible el control en tiempo real. Este modelo está entrenado en un conjunto de datos de robótica del mundo real a gran escala de 130k episodios que cubren más de 700 tareas, recopilados utilizando una flota de 13 robots de Robots cotidianos (EDR) durante 17 meses. Demostramos que RT-1 puede exhibir una generalización de tiro cero significativamente mejorada para nuevas tareas, entornos y objetos en comparación con técnicas anteriores. Además, evaluamos y eliminamos cuidadosamente muchas de las opciones de diseño en el modelo y el conjunto de entrenamiento, analizando los efectos de la tokenización, la representación de acciones y la composición del conjunto de datos. Por último, estamos abriendo el código fuente código RT-1y espero que proporcione un recurso valioso para futuras investigaciones sobre la ampliación del aprendizaje de robots.
 |
| RT-1 absorbe grandes cantidades de datos, incluidas trayectorias de robots con múltiples tareas, objetos y entornos, lo que resulta en un mejor rendimiento y generalización. |
Transformador de robótica (RT-1)
RT-1 está construido sobre un arquitectura del transformador que toma un breve historial de imágenes de la cámara de un robot junto con descripciones de tareas expresadas en lenguaje natural como entradas y salidas directas de acciones tokenizadas.
La arquitectura de RT-1 es similar a la de un modelo de secuencia de solo decodificador contemporáneo entrenado contra un modelo categórico estándar. entropía cruzada objetivo con enmascaramiento causal. Sus características clave incluyen: tokenización de imágenes, tokenización de acciones y compresión de tokens, que se describen a continuación.
Tokenización de imágenes: Pasamos imágenes a través de un modelo EfficientNet-B3 que está pre-entrenado en ImageNet, y luego aplane el mapa de características espaciales de 9×9×512 resultante a 81 tokens. El tokenizador de imágenes está condicionado a instrucciones de tareas en lenguaje natural y utiliza capas de película inicializado a la identidad para extraer características de imagen relevantes para la tarea desde el principio.
Tokenización de acciones: Las dimensiones de acción del robot son 7 variables para el movimiento del brazo (x, y, z, balanceo, cabeceo, guiñada, apertura de la pinza), 3 variables para el movimiento de la base (x, y, guiñada) y una variable discreta adicional para cambiar entre tres modos : brazo controlador, base controladora o finalización del episodio. Cada dimensión de acción se discretiza en 256 contenedores.
Compresión de fichas: El modelo selecciona de forma adaptativa combinaciones suaves de tokens de imágenes que se pueden comprimir en función de su impacto en el aprendizaje con el módulo de atención basada en elementos TokenLearner, lo que da como resultado una aceleración de la inferencia de más de 2,4 veces.
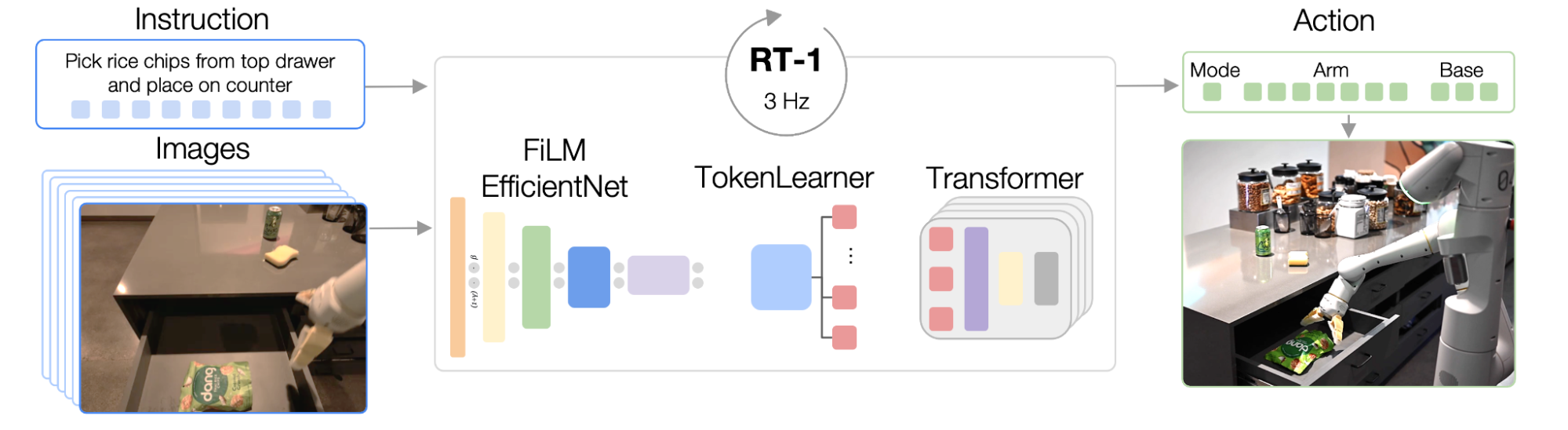 |
| Arquitectura de RT-1: el modelo toma una instrucción de texto y un conjunto de imágenes como entradas, las codifica como tokens a través de un modelo FiLM EfficientNet entrenado previamente y las comprime a través de TokenLearner. Estos luego se introducen en el Transformador, que genera fichas de acción. |
Para construir un sistema que pudiera generalizarse a nuevas tareas y mostrar solidez a diferentes distractores y entornos, recopilamos un conjunto de datos grande y diverso de trayectorias de robots. Utilizamos 13 manipuladores de robots EDR, cada uno con un brazo de 7 grados de libertad, una pinza de 2 dedos y una base móvil, para recopilar 130 000 episodios durante 17 meses. Usamos demostraciones proporcionadas por humanos a través de la teleoperación remota y anotamos cada episodio con una descripción textual de la instrucción que acaba de realizar el robot. El conjunto de habilidades de alto nivel representado en el conjunto de datos incluye recoger y colocar artículos, abrir y cerrar cajones, meter y sacar artículos de cajones, colocar artículos alargados en posición vertical, tirar objetos, tirar de servilletas y abrir frascos. El conjunto de datos resultante incluye más de 130 000 episodios que cubren más de 700 tareas utilizando muchos objetos diferentes.
Experimentos y Resultados
Para comprender mejor las capacidades de generalización de RT-1, estudiamos su rendimiento frente a tres líneas base: Gato, BC-Z y BC-Z XL (es decir, BC-Z con la misma cantidad de parámetros que RT-1), en cuatro categorías:
- Rendimiento de tareas visto: desempeño en tareas visto durante el entrenamiento
- Rendimiento de tareas no vistas: rendimiento en tareas no vistas en las que la habilidad y los objetos se veían por separado en el conjunto de entrenamiento, pero se combinaban de formas novedosas
- Robustez (distractores y fondos): actuación con distractores (hasta 9 distractores y oclusión) y actuación con cambios de fondo (nueva cocina, iluminación, escenas de fondo)
- Escenarios de largo horizonte: ejecución de instrucciones en lenguaje natural tipo SayCan en una cocina real
RT-1 supera las líneas de base por amplios márgenes en las cuatro categorías, exhibiendo impresionantes grados de generalización y solidez.
 |
| Desempeño de RT-1 vs líneas de base en escenarios de evaluación. |
Incorporación de fuentes de datos heterogéneas
Para impulsar el RT-1 aún más, lo entrenamos con datos recopilados de otro robot para probar si (1) el modelo conserva su rendimiento en las tareas originales cuando se presenta una nueva fuente de datos y (2) si el modelo ve un impulso en la generalización. con datos nuevos y diferentes, los cuales son deseables para un modelo general de aprendizaje de robots. Específicamente, usamos 209k episodios de agarre indiscriminado que fueron recopilados de forma autónoma en un brazo Kuka de base fija para la Proyecto QT-Opt. Transformamos los datos recopilados para que coincidan con las especificaciones de acción y los límites de nuestro conjunto de datos original recopilado con EDR, y etiquetamos cada episodio con la instrucción de tarea “elegir cualquier cosa” (el conjunto de datos de Kuka no tiene etiquetas de objetos). Luego, los datos de Kuka se mezclan con los datos de EDR en una proporción de 1:2 en cada lote de entrenamiento para controlar la regresión en las habilidades de EDR originales.
 |
| Metodología de entrenamiento cuando se han recopilado datos de varios robots. |
Nuestros resultados indican que RT-1 puede adquirir nuevas habilidades al observar las experiencias de otros robots. En particular, la precisión del 22 % que se observa cuando se entrena solo con datos de EDR aumenta casi 2 veces al 39 % cuando se entrena al RT-1 tanto con datos de selección de contenedores de Kuka como con datos de EDR existentes de aulas de robots, donde recopilamos la mayor parte de los datos de RT- 1 datos Al entrenar RT-1 solo con datos de recolección de contenedores de Kuka y luego evaluarlos con la recolección de contenedores del robot EDR, vemos una precisión del 0 %. La mezcla de datos de ambos robots, por otro lado, permite a RT-1 inferir las acciones del robot EDR ante los estados observados por Kuka, sin demostraciones explícitas de bin-picking en el robot EDR, y aprovechando las experiencias recogido por Kuka. Esto presenta una oportunidad para que el trabajo futuro combine más conjuntos de datos de múltiples robots para mejorar las capacidades de los robots.
| Datos de entrenamiento | Evaluación del aula | Evaluación de bin-picking |
| Datos de bin-picking de Kuka + datos de EDR | 90% | 39% |
| Solo datos EDR | 92% | 22% |
| Kuka bin-picking solo datos | 0 | 0 |
| Evaluación de la precisión del RT-1 usando varios datos de entrenamiento. |
Tareas de SayCan a largo plazo
Las capacidades de alto rendimiento y generalización de RT-1 pueden permitir tareas de manipulación móvil a largo plazo a través de SayCan. SayCan funciona basando los modelos de lenguaje en posibilidades robóticas y aprovechando las indicaciones de pocas tomas para desglosar una tarea de largo plazo expresada en lenguaje natural en una secuencia de habilidades de bajo nivel.
Las tareas de SayCan presentan una configuración de evaluación ideal para probar varias funciones:
- El éxito de la tarea a largo plazo cae exponencialmente con la duración de la tarea, por lo que es importante un alto éxito de manipulación.
- Las tareas de manipulación móvil requieren transferencias múltiples entre la navegación y la manipulación, por lo que la solidez frente a las variaciones en las condiciones políticas iniciales (p. ej., la posición base) es esencial.
- El número de posibles instrucciones de alto nivel aumenta combinatoriamente con la amplitud de habilidades de la primitiva de manipulación.
Evaluamos SayCan con RT-1 y otras dos líneas de base (SayCan con Gato y SayCan con BC-Z) en dos cocinas reales. A continuación, “Cocina2” constituye una escena de generalización mucho más desafiante que “Cocina1”. La cocina simulada utilizada para recopilar la mayoría de los datos de capacitación se modeló a partir de Kitchen1.
SayCan con RT-1 logra una tasa de éxito de ejecución del 67 % en Kitchen1, superando a otras líneas de base. Debido a la dificultad de generalización que presenta la nueva cocina invisible, el desempeño de SayCan con Gato y SayCan con BCZ cae bien, mientras que RT-1 no muestra una caída visible.
| Tareas de SayCan en Kitchen1 | Tareas de SayCan en Kitchen2 | |||
| Planificación | Ejecución | Planificación | Ejecución | |
| Saycán original | 73 | 47 | – | – |
| SayCan con Gato | 87 | 33 | 87 | 0 |
| SayCan con BC-Z | 87 | 53 | 87 | 13 |
| SayCan con RT-1 | 87 | 67 | 87 | 67 |
El siguiente video muestra algunos ejemplos de ejecuciones PaLM-SayCan-RT1 de tareas de largo plazo en múltiples cocinas reales.
Conclusión
El transformador de robótica RT-1 es un modelo de generación de acción simple y escalable para tareas de robótica del mundo real. Tokeniza todas las entradas y salidas, y utiliza un modelo EfficientNet pre-entrenado con fusión de idiomas temprana y un token de aprendizaje para la compresión. RT-1 muestra un sólido rendimiento en cientos de tareas y amplias capacidades de generalización y robustez en entornos del mundo real.
A medida que exploramos direcciones futuras para este trabajo, esperamos escalar la cantidad de habilidades de los robots más rápido mediante el desarrollo de métodos que permitan a los no expertos entrenar al robot con la recopilación de datos dirigidos y las indicaciones del modelo. También esperamos mejorar las velocidades de reacción de los transformadores de robótica y la retención de contexto con atención y memoria escalables. Para obtener más información, consulte el papelde código abierto código RT-1y el sitio web del proyecto.
Agradecimientos
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, Julian Ibarz, Brian Ichter, Alex Irpan, Thomas Jackson, Sally Jesmonth, Nikhil Joshi, Ryan Julian , Dmitry Kalashnikov, Yuheng Kuang, Isabel Leal, Kuang-Huei Lee, Sergey Levine, Yao Lu, Utsav Malla, Deeksha Manjunath, Igor Mordatch, Ofir Nachum, Carolina Parade, Jodilyn Peralta, Emily Perez, Karl Pertsch, Jornell Quiambao, Kanishka Rao , Michael Ryoo, Grecia Salazar, Kevin Sayed, Jaspiar Singh, Sumedh Sontakke, Austin Stone, Clayton Tan, Huong Tran, Vincent Vanhoucke, Steve Vega, Quan Vuong, Fei Xia, Ted Xiao, Peng Xu, Sichun Xu, Tianhe Yu y Brianna Zitkovich.






{kind=link}