
Understanding and managing large-scale software repositories is a recurring problem in contemporary software development. Although current tools shine at summarizing small code entities, such as functions, they struggle to scale to repository-level artifacts, such as files and packages. These more abstract summaries are vital to understanding the intent and behavior of entire codebases, particularly in enterprise applications where technical summaries must be aligned with business objectives. According to several reports, this gap creates inefficiencies, as developers spend more than 50% of their time understanding existing code. These inefficiencies negatively impact productivity and slow down the development and maintenance of systems such as Business Support Systems (BSS) in the telecommunications industry.
Traditional summarization methods, including rule-based and template-based approaches, do not meet the requirements of large-scale code bases. While advances in machine learning such as neural machine translation and transformer-based models have improved summarization for small code units, they often rely on data sets such as CodeSearchNet and CodeXGLUE that focus on code. at the system level. This narrow focus limits its effectiveness in domain-specific and business context applications. Code-specific large language models (LLMs), such as CodeLlama and StarCoder, improve performance, but cannot align summaries with broader business intent. Meanwhile, closed-source LLMs, including GPT, offer superior accuracy but raise privacy concerns, making them unsuitable for proprietary enterprise software. These limitations leave a significant gap in repository-level summarization, especially for large-scale applications that require understanding technical details and domain-specific nuances.
TCS Research researchers propose a novel hierarchical framework for summarizing code at the repository level, designed specifically for enterprise applications. This strategy aims to overcome the limitations of current practices through LLM-based local privacy preservation and domain-specific relevance basis. The process includes breaking down large code artifacts into manageable units such as functions, variables, and constructors using abstract syntax tree (AST) parsing. Individual segments are summarized separately and their summaries are then combined into file-level and package-level summaries.
A distinctive aspect of this framework is the incorporation of domain-specific and problem-context knowledge through personalized prompts. By embedding the summarization process into the telecom industry's business objectives and operating environment, the technique ensures that summaries identify the higher-level intent and utility of code artifacts. The technique ensures not only that summaries are comprehensive but also goal-directed in accordance with the purposes of enterprise systems such as BSS, where understanding the purpose of the code is as important as its technical nature.
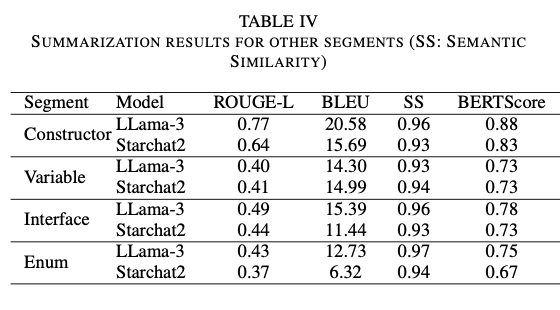
The approach employs AST analysis to identify logical segments of source files, including functions, enums, and variables, which are individually summarized with custom prompts. Functions, for example, are described by examining their inputs, outputs, workflows, side effects, and overall purpose, while variables and enums are described in terms of their function within the larger application. These segment-level summaries are aggregated into file-level summaries, which describe the purpose and function of the file within the repository. Additionally, file-level summaries are aggregated into package-level summaries, which provide a complete picture of the structure and functionality of the repository. To keep the summaries accurate and relevant, the structure includes descriptions of specific domains, including those about telecommunications and the BSS operating environment. This foundation allows briefs to capture not only the technical aspects of the code but also the alignment of the code with overall business objectives, making them well suited for use in enterprise environments.

The researchers evaluated the framework using a publicly available GitHub repository designed to simulate the characteristics of a telecom BSS. The hierarchical structure of the summarization process ensured comprehensive coverage of all code segments, resolving omission issues seen with traditional methods. By systematically summarizing the individual components, the approach captured all relevant details, ensuring a complete and accurate representation of the repository. Basing the summaries on domain-specific knowledge and problem context significantly improved their quality, improving domain relevance by more than 7% and completeness by 13%, all while maintaining conciseness and cohesion. Performance tests with metrics such as ROUGE-L, BLEU, and BERTScore showed significant improvements over baseline approaches, reflecting the correctness and context-sensitivity of the summaries. In addition, professional evaluations from the telecommunications sector validated the informative nature and relevance of the summaries produced, affirming their correspondence with business objectives and technical specifications. This holistic approach was especially effective in producing aligned and insightful briefs that meet the particular requirements of enterprise software development.
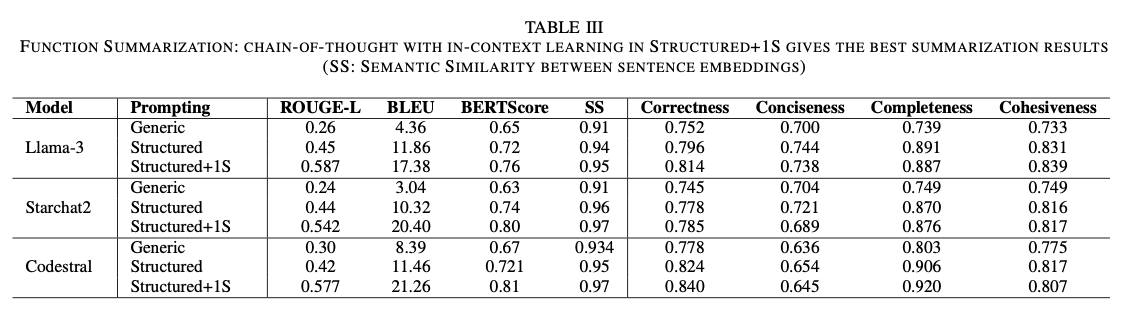

This hierarchical repository-level code summarization framework represents a significant advance in the understanding and maintenance of enterprise applications. By breaking down intricate code bases into understandable units and including domain expertise, the process ensures accurate, relevant, and business-focused briefs. It can effectively overcome the shortcomings of current techniques, allowing developers to improve productivity and simplify maintenance procedures. The technique promises expanded applicability in other domains such as healthcare and finance, with possible future extensions encompassing multimodal functionality to further improve code understanding.
Verify he Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on <a target="_blank" href="https://x.com/intent/follow?screen_name=marktechpost” target=”_blank” rel=”noreferrer noopener”>twitter and join our Telegram channel and LinkedIn Grabove. Don't forget to join our SubReddit over 70,000 ml.
<a target="_blank" href="https://nebius.com/blog/posts/studio-embeddings-vision-and-language-models?utm_medium=newsletter&utm_source=marktechpost&utm_campaign=embedding-post-ai-studio” target=”_blank” rel=”noreferrer noopener”> (Recommended Reading) Nebius ai Studio Expands with Vision Models, New Language Models, Embeddings, and LoRA (Promoted)
Aswin AK is a Consulting Intern at MarkTechPost. He is pursuing his dual degree from the Indian Institute of technology Kharagpur. He is passionate about data science and machine learning, and brings a strong academic background and practical experience solving real-life interdisciplinary challenges.






{kind=link}