
Graph neural networks (GNN) is a rapidly advancing field in machine learning, specifically designed to analyze graphically structured data representing entities and their relationships. These networks have been widely used in social network analysis, recommender systems, and molecular data interpretation applications. A subset of GNNs, attention-based graph neural networks (AT-GNN), employs attention mechanisms to improve predictive accuracy and interpretability by emphasizing the most relevant relationships in the data. However, its computational complexity poses significant challenges, particularly in efficiently using GPUs for training and inference.
One of the important problems in AT-GNN training is the inefficiency caused by fragmented GPU operations. The calculation involves multiple complex steps, such as calculating attention scores, normalizing these scores, and adding feature data, which require frequent kernel launches and data movement. Existing frameworks must adapt to the heterogeneous nature of real-world graph structures, resulting in workload imbalance and reduced scalability. The problem is further exacerbated by supernodes (nodes with unusually large neighbors) that overload memory resources and undermine performance.
Existing GNN frameworks, such as PyTorch Geometric (PyG) and Deep Graph Library (DGL), attempt to optimize operations using core fusion and thread scheduling. Techniques such as Seastar and dgNN have improved sparse operations and overall GNN workloads. However, these methods rely on fixed parallel strategies that cannot dynamically adapt to the unique computational needs of AT-GNNs. For example, they need help with using mismatched threads and taking full advantage of the benefits of core merging when faced with graph structures containing supernodes or irregular computational patterns.
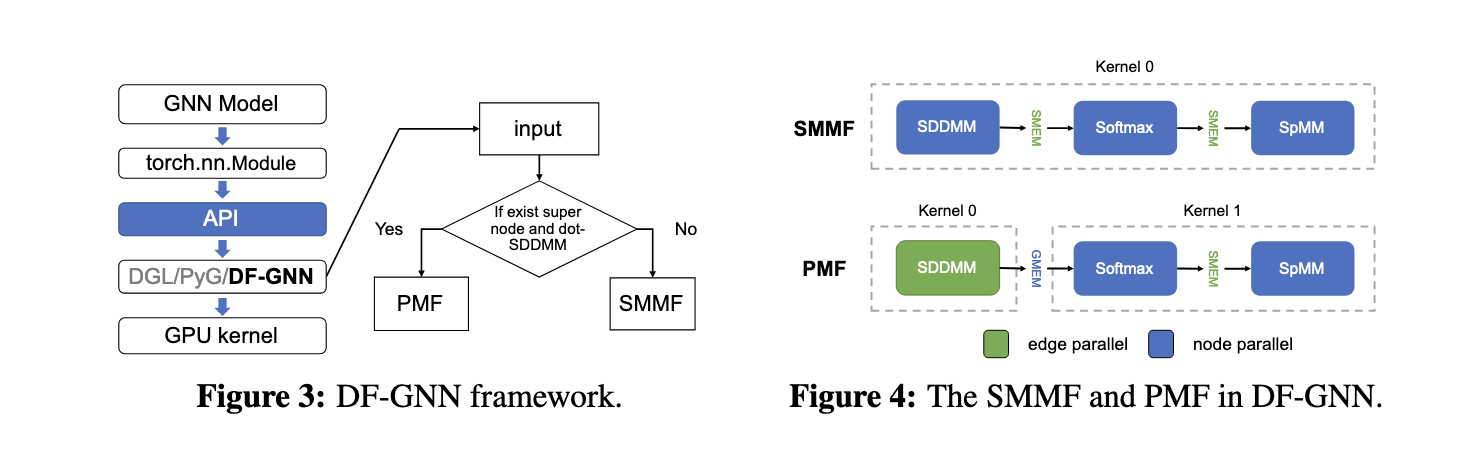
The research team from Shanghai Jiao Tong University and amazon Web Services proposed DF-GNN, a dynamic fusion framework explicitly designed to optimize the execution of AT-GNN on GPUs. Integrated with the PyTorch framework, DF-GNN features an innovative two-level thread scheduling mechanism that allows dynamic adjustments to thread distribution. This flexibility ensures that operations such as Softmax normalization and sparse matrix multiplications are executed with optimal thread utilization, significantly improving performance. DF-GNN addresses the inefficiencies associated with static core fusion techniques by allowing different scheduling strategies for each operation.
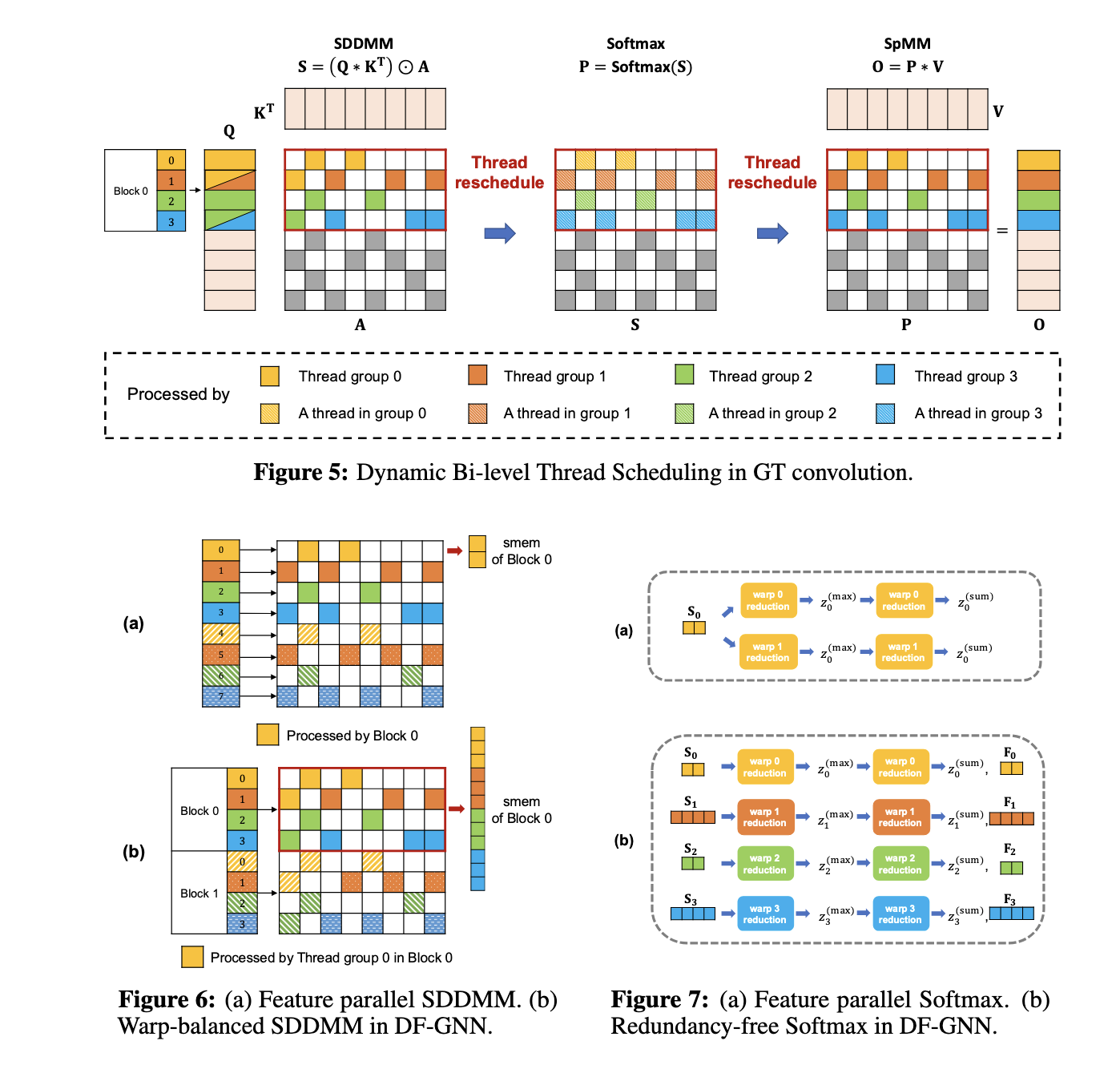
DF-GNN employs two main fusion strategies: Shared Memory Maximization Fusion (SMMF) and Parallelism Maximization Fusion (PMF). SMMF consolidates operations into a single kernel, optimizing memory usage by storing intermediate results in shared memory, thereby reducing data movement. In contrast, PMF focuses on graphs with supernodes, where edge-parallel strategies outperform node-parallel strategies. Additionally, the framework introduces custom optimizations such as warp-balanced scheduling for edge calculations, redundancy-free Softmax to eliminate repeated calculations, and vectorized memory access to minimize global memory overhead. These features ensure efficient processing of forward and backward calculations, making it easy to accelerate end-to-end training.
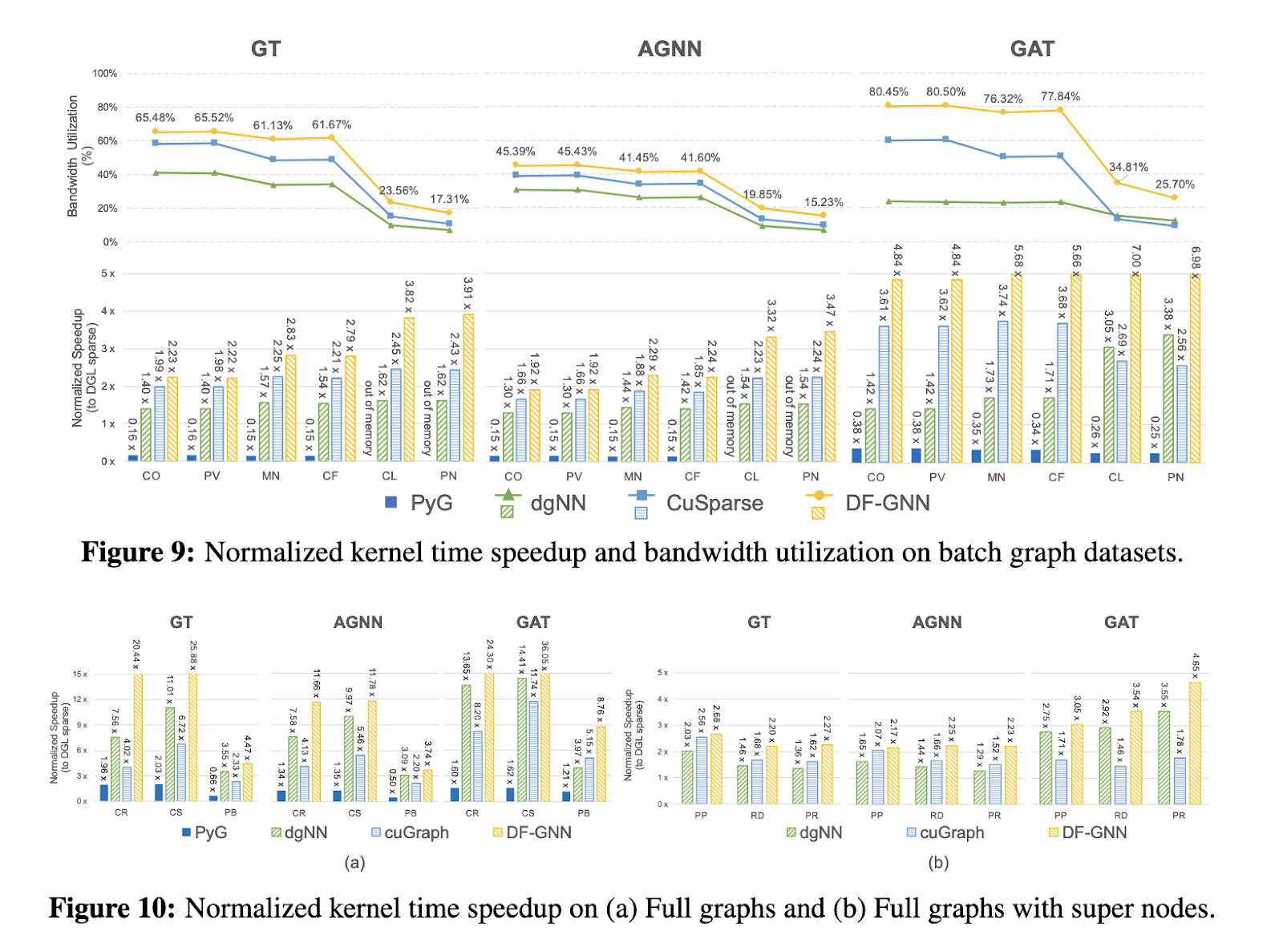
Extensive evaluations demonstrate the notable performance improvements of DF-GNN. On full graph datasets such as Cora and Citeseer, DF-GNN achieved an average speedup of 16.3x compared to the sparse DGL library, with maximum improvements of up to 7x in kernel operations. On batch graph data sets, including high-grade graphs like PATTERN, it provided an average speedup of 3.7xsurpassing competitors such as cuGraph and dgNN, which managed only 2.4x and 1.7xrespectively. Furthermore, DF-GNN exhibited superior adaptability on loaded datasets from supernodes such as Reddit and Protein, achieving an average 2.8x Speed up while maintaining solid memory utilization. The framework's bandwidth utilization remained consistently high, ensuring optimal performance across all graphics sizes and structures.
Beyond kernel-level improvements, DF-GNN also accelerates end-to-end training workflows. On batch graph data sets, it achieved an average speedup of 1.84x for complete training periods, with individual improvements in forward passes reaching 3.2x. The acceleration extended to 2.6x on full graph datasets, highlighting the efficiency of DF-GNN in handling diverse workloads. These results underline the framework's ability to dynamically adapt to different computational scenarios, making it a versatile tool for large-scale GNN applications.
By addressing the inherent inefficiencies of AT-GNN training on GPUs, DF-GNN presents a complete solution that dynamically adapts to different computing and graphics characteristics. By addressing critical bottlenecks such as memory utilization and thread scheduling, this framework sets a new benchmark in GNN optimization. Its integration with PyTorch and support for diverse data sets ensure broad applicability, paving the way for faster and more efficient graph-based learning systems.
Verify he Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on <a target="_blank" href="https://twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. If you like our work, you will love our information sheet.. Don't forget to join our SubReddit over 55,000ml.
Nikhil is an internal consultant at Marktechpost. He is pursuing an integrated double degree in Materials at the Indian Institute of technology Kharagpur. Nikhil is an ai/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in materials science, he is exploring new advances and creating opportunities to contribute.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}