 NEWSLETTER
NEWSLETTER
In the current technological landscape, 3D vision has emerged as a star on the rise, capturing the spotlight due to its rapid growth and evolution. This surge in interest can be largely attributed to the soaring demand for autonomous driving, enhanced navigation systems, advanced 3D scene comprehension, and the burgeoning field of robotics. To extend its application scenarios, numerous efforts have been made to incorporate 3D point clouds with data from other modalities, allowing for improved 3D understanding, text-to-3D generation, and 3D question answering.
Researchers have introduced Point-Bind, a revolutionary 3D multi-modality model designed to seamlessly integrate point clouds with various data sources such as 2D images, language, audio, and video. Guided by the principles of ImageBind, this model constructs a unified embedding space that bridges the gap between 3D data and multi-modalities. This breakthrough enables a multitude of exciting applications, including but not limited to any-to-3D generation, 3D embedding arithmetic, and comprehensive 3D open-world understanding.
In the above image we can see the overall pipeline of Point-Bind. Researchers first collect 3D-image-audio-text data pairs for contrastive learning, which aligns 3D modality with others guided ImageBind. With a joint embedding space, Point-Bind can be utilized for 3D cross-modal retrieval, any-to-3D generation, 3D zero-shot understanding, and developing a 3D large language model, Point-LLM.
The main contributions of Point Blind in this study include:
- Aligning 3D with ImageBind: Within a joint embedding space, Point-Bind firstly aligns 3D point clouds with multi-modalities guided by ImageBind, including 2D images, video, language, audio, etc.
- Any-to-3D Generation: Based on existing textto-3D generative models, Point-Bind enables 3D shape synthesis conditioned on any modalities, i.e text/image/audio/point-to-mesh generation.
- 3D Embedding-space Arithmetic: We observe that 3D features from Point-Bind can be added with other modalities to incorporate their semantics, achieving composed cross-modal retrieval.
- 3D Zero-shot Understanding: Point-Bind attains state-of-the-art performance for 3D zero-shot classification. Also, our approach supports audio-referred 3D open-world understanding, besides text reference.
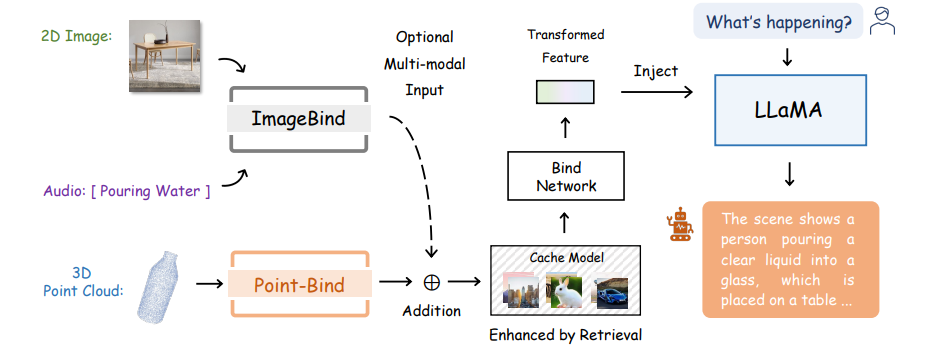
Researchers leverage Point-Bind to develop 3D large language models (LLMs), termed as Point-LLM, which fine-tunes LLaMA to achieve 3D question answering and multi-modal reasoning. The overall pipeline of Point-LLM can be seen in the above image.
The main contributions of Point LLM include:
- Point-LLM for 3D Question Answering: Using PointBind, we introduce Point-LLM, the first 3D LLM that responds to instructions with 3D point cloud conditions, supporting both English and Chinese.
- Data- and Parameter-efficiency: We only utilize public vision-language data for tuning without any 3D instruction data, and adopt parameter-efficient finetuning techniques, saving extensive resources.
- 3D and Multi-modal Reasoning: Via the joint embedding space, Point-LLM can generate descriptive responses by reasoning a combination of 3D and multimodal input, e.g., a point cloud with an image/audio.
The future work will focus on aligning multi-modality with more diverse 3D data, such as indoor and outdoor scenes, which allows for wider application scenarios.
Check out the Paper and Github link. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Janhavi Lande, is an Engineering Physics graduate from IIT Guwahati, class of 2023. She is an upcoming data scientist and has been working in the world of ml/ai research for the past two years. She is most fascinated by this ever changing world and its constant demand of humans to keep up with it. In her pastime she enjoys traveling, reading and writing poems.
 Check out Hostinger AI Website Builder (Sponsored)
Check out Hostinger AI Website Builder (Sponsored) 





{kind=link}