
Large language models (LLMs) have revolutionized the field of artificial intelligence by performing a wide range of tasks in different domains. These models are expected to work seamlessly in multiple languages, solving complex problems while ensuring security. However, the challenge lies in maintaining security without compromising performance, especially in multilingual environments. As ai technologies become ubiquitous globally, it is essential to address security concerns that arise when models trained predominantly in English are deployed in multiple languages and cultural contexts.
The central issue revolves around balancing performance and security in LLMs. Security issues arise when models produce biased or harmful results, particularly in languages with limited training data. Typically, methods to address this involve fitting models on mixed data sets, combining general-purpose and security tasks. However, these approaches can lead to undesirable trade-offs. In many cases, increasing security measures in LLMs can negatively impact their ability to perform well on general tasks. Therefore, the challenge is to develop an approach that improves both security and performance in multilingual LLMs without requiring massive amounts of task-specific data.
Current methods used to balance these objectives often rely on data blending techniques. This involves creating a single model by training it on multiple data sets from various tasks and languages. While these methods help achieve a certain level of multitasking ability, they can lead to security issues that are not properly addressed in languages other than English. Additionally, the complexity of managing numerous tasks simultaneously often reduces the model's ability to perform well on any of them. The lack of specialized attention to each task and language limits the model's ability to address security and overall performance effectively.
To overcome these limitations, Cohere ai researchers have introduced an innovative approach based on model fusion. Instead of relying on the traditional method of combining data, where a single model is trained on multiple tasks and languages, the researchers propose merging separate models that have been independently tuned for specific tasks and languages. This method allows for better specialization within each model before merging them into a unified system. By doing so, the models retain their unique capabilities and offer improvements in security and overall performance in multiple languages.
The fusion process is carried out through multiple techniques. The main method introduced by the researchers is spherical linear interpolation (SLERP), which allows smooth transitions between different models by combining their weights along a spherical trajectory. This technique ensures that the unique properties of each model are preserved, allowing the merged model to handle various tasks without compromising security or performance. Another method, TIES (Task Interference Elimination Strategy), focuses on resolving conflicts between models tuned for specific tasks by adjusting model parameters to better align. Fusion techniques also include linear fusion and DARE-TIES, which further improve the robustness of the final model by addressing interference issues and ensuring that model parameters contribute positively to performance.
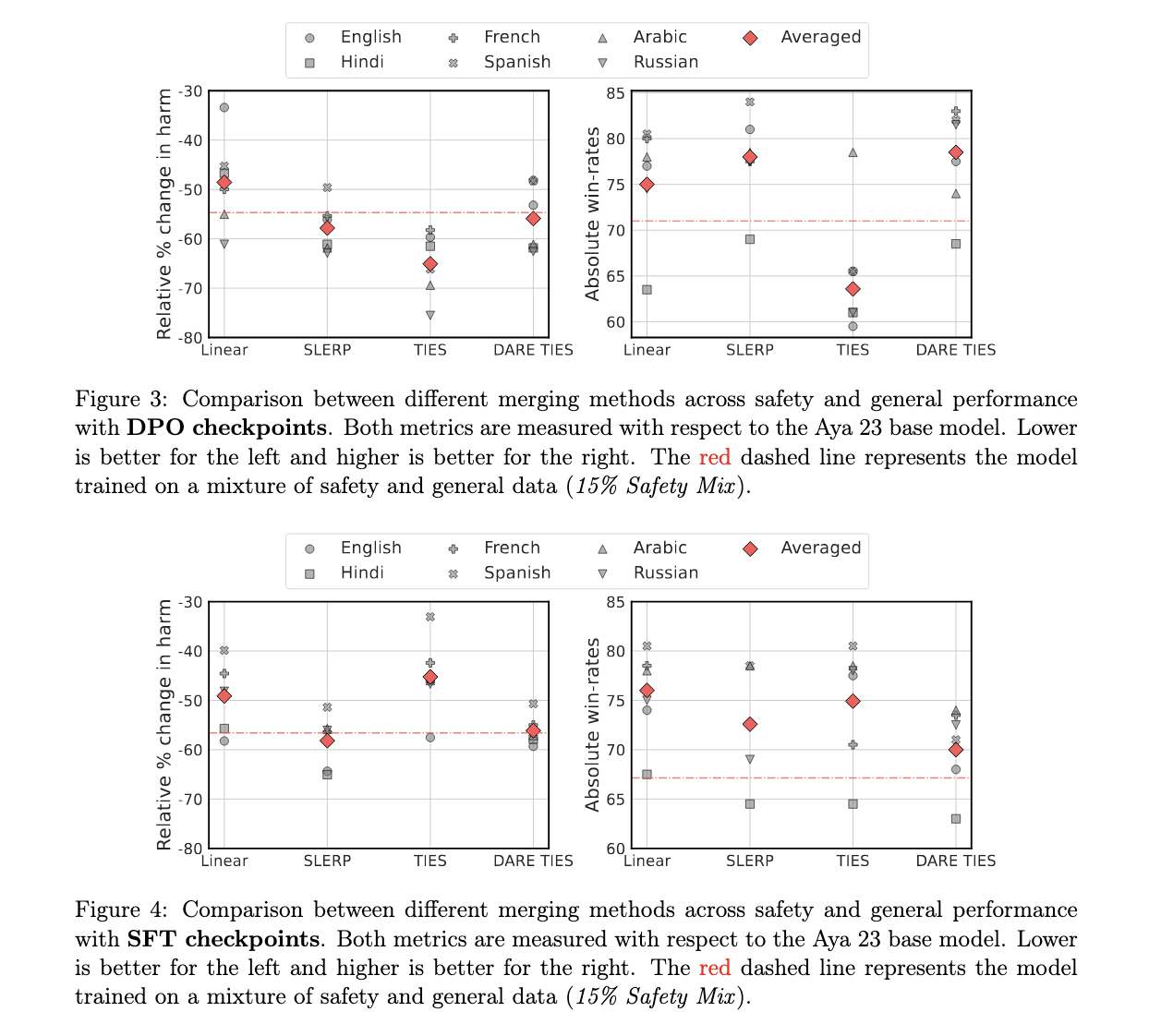
The results of this research show clear improvements in both overall performance and safety. For example, SLERP fusion achieved an impressive 7% improvement in overall performance and a 3.1% reduction in harmful results compared to traditional data merging methods. On the other hand, the TIES merger produced a notable 10.4% reduction in harmful results, although it slightly reduced overall performance by 7.4%. These numbers indicate that model fusion significantly outperforms data fusion when balancing security and performance. Additionally, when the models were fine-tuned for individual languages and merged, the researchers observed up to a 6.6% reduction in harmful outcomes and a 3.8% improvement in overall benchmarks, further demonstrating the effectiveness of language-specific model fusion on training multilingual models.
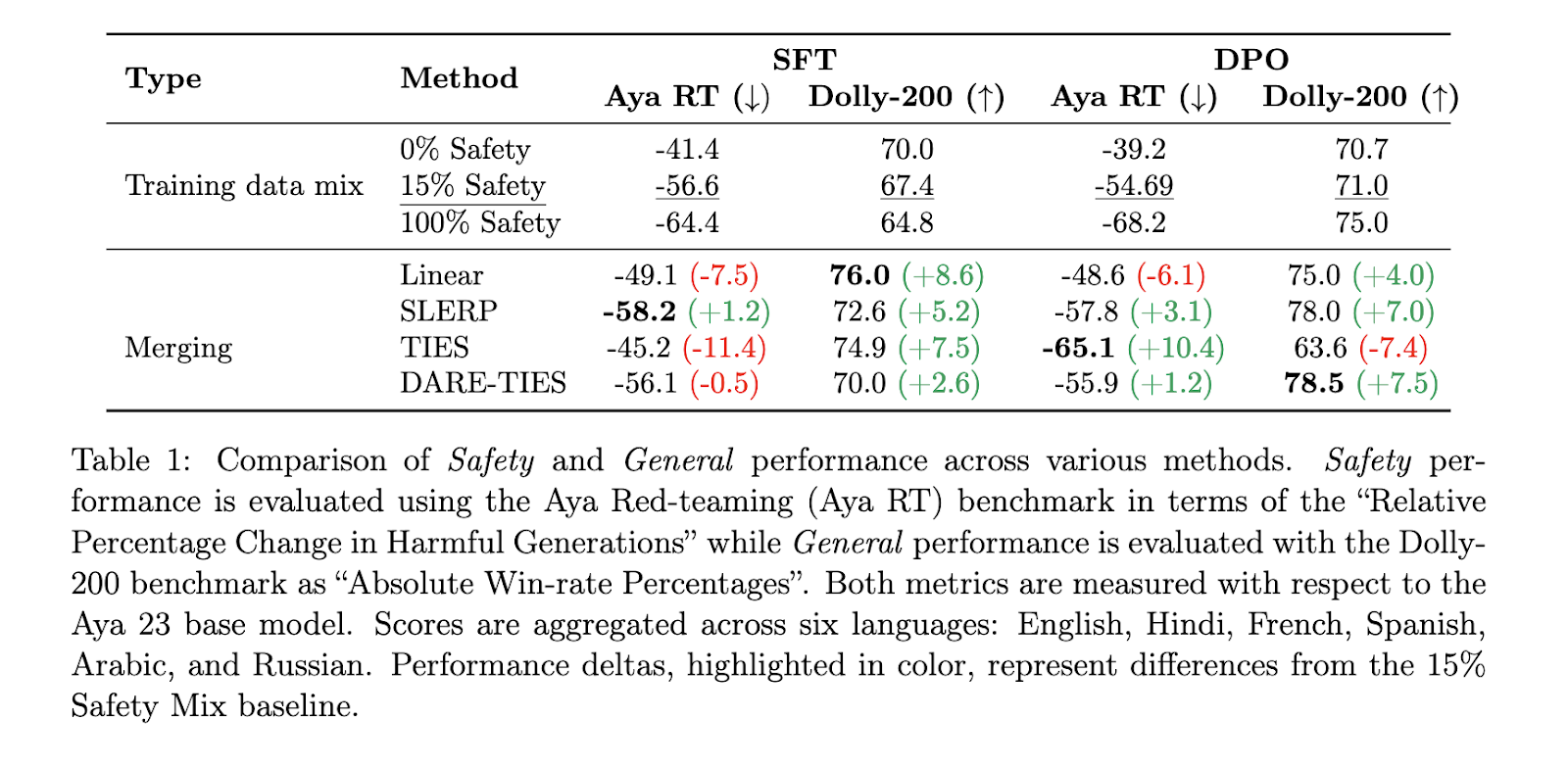
Performance improvements were particularly notable in some languages, with Russian showing the largest reduction in harmful generations (up to 15%) using TIES fusion. Meanwhile, Spanish showed a 10% improvement in overall performance with the SLERP and TIES methods. However, not all languages benefit equally. The English models, for example, showed a decrease in safety performance when merged, highlighting the variability in results based on the underlying training data and fusion strategy.
The research provides a comprehensive framework for creating safer and more effective multilingual LLMs. By fusing models tuned for security and performance across specific tasks and languages, Cohere ai researchers demonstrated a more efficient and scalable method for improving LLMs. The approach reduces the need for massive amounts of training data and allows for better alignment of safety protocols across languages, which is critically important in today's ai landscape.
In conclusion, model fusion represents a promising step forward in addressing the balance between performance and security challenges in LLMs, particularly in multilingual environments. This method significantly improves the ability of LLMs to deliver high-quality, secure results, especially when applied to low-resource languages. As ai evolves, techniques such as model fusion could become essential tools to ensure that ai systems are robust and secure in diverse linguistic and cultural contexts.
look at the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. If you like our work, you will love our information sheet.. Don't forget to join our SubReddit over 50,000ml.
(Next live webinar: October 29, 2024) Best platform to deliver optimized models: Predibase inference engine (promoted)
Nikhil is an internal consultant at Marktechpost. He is pursuing an integrated double degree in Materials at the Indian Institute of technology Kharagpur. Nikhil is an ai/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in materials science, he is exploring new advances and creating opportunities to contribute.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>





{kind=link}