
Language-guided video segmentation is a developing domain that focuses on segmenting and tracking specific objects in videos using natural language descriptions. Current datasets for referring to video objects usually emphasise prominent objects and rely on language expressions with many static attributes. These attributes allow for identifying the target object in just one frame. However, these datasets overlook the significance of motion in language-guided video object segmentation.
Researchers have introduced MeVIS, a new large-scale dataset called Motion Expression Video Segmentation (MeViS), to aid our investigation. The MeViS dataset comprises 2,006 videos with 8,171 objects, and 28,570 motion expressions are provided to refer to these objects. The above images display the expressions in MeViS that primarily focus on motion attributes, and the referred target object cannot be identified by examining a single frame solely. For instance, the first example features three parrots with similar appearances, and the target object is identified as “The bird flying away.” This object can only be recognized by capturing its motion throughout the video.
A few steps ensure that the MeVIS dataset emphasizes the temporal motions of the videos.
First, video content is selected carefully that contains multiple objects that coexist with motion and excludes videos with isolated objects that static attributes can easily describe.
Second, language expressions are prioritized that do not contain static clues, such as category names or object colors, in cases where target objects can be unambiguously described by motion words alone.
In addition to proposing the MeViS dataset, researchers also present a baseline approach, named Language-guided Motion Perception and Matching (LMPM), to address the challenges posed by this dataset. Their approach involves the generation of language-conditioned queries to identify potential target objects within the video. These objects are then represented using object embeddings, which are more robust and computationally efficient compared to object feature maps. The researchers apply Motion Perception to these object embeddings to capture the temporal context and establish a holistic understanding of the video’s motion dynamics. This enables their model to grasp both momentary and prolonged motions present in the video.
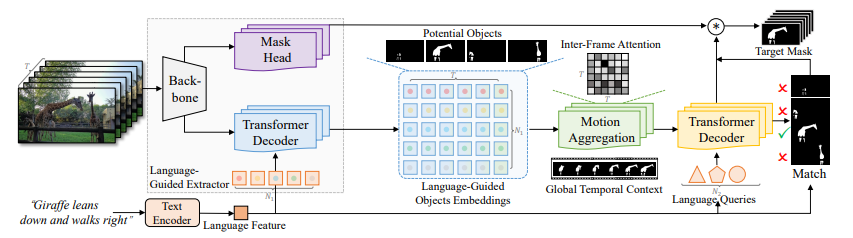
The above image displays the architecture of LMLP. They use a Transformer decoder to interpret language from combined object embeddings affected by motion. This helps predict object movements. Then, they compare language features with projected object movements to find the target object(s) mentioned in the expressions. This innovative method merges language understanding and motion assessment to handle the complex dataset task effectively.
This research has provided a foundation for developing more advanced language-guided video segmentation algorithms. It has opened up avenues in more challenging directions, such as:
- Exploring new techniques for better motion understanding and modeling in visual and linguistic modalities.
- Creating more efficient models that reduce the number of redundant detected objects.
- Designing effective cross-modal fusion methods to leverage the complementary information between language and visual signals.
- Developing advanced models that can handle complex scenes with various objects and expressions.
Addressing these challenges requires research to propel the current state-of-the-art in the field of language-guided video segmentation forward.
Check out the Paper, Github, and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 29k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, please follow us on Twitter
![]()
Janhavi Lande, is an Engineering Physics graduate from IIT Guwahati, class of 2023. She is an upcoming data scientist and has been working in the world of ml/ai research for the past two years. She is most fascinated by this ever changing world and its constant demand of humans to keep up with it. In her pastime she enjoys traveling, reading and writing poems.






{kind=link}