 NEWSLETTER
NEWSLETTER
Diffusion models generate images progressively refining the noise in structured representations. However, the computational cost associated with these models remains a key challenge, particularly when operating directly in high -dimension pixels data. Researchers have been investigating ways to optimize representations of latent space to improve efficiency without compromising image quality.
A critical problem in diffusion models is the quality and structure of latent space. Traditional approaches, such as variational self -conditions (VAE), have been used as tokenizers to regulate latent space, ensuring that the representations learned are soft and structured. However, they often fight them to achieve high loyalty at the pixel level due to the limitations imposed by regularization. Self -chirers (AES), which do not use variational restrictions, can reconstruct images with greater fidelity, but often lead to a tangled space that hinders the training and performance of diffusion models. Addressing these challenges requires a tokenizer that provides a structured latent space while maintaining high reconstruction precision.
Previous research efforts have tried to address these problems using various techniques. VAE impose a Kullback-Leibbler (KL) restriction to foster soft latent distributions, while they are aligned with representation refine latent structures for a better generation quality. Some methods use Gaussian mixing models (GMM) to structure latent space or align latent representations with previously trained models to improve performance. Despite these advances, existing approaches still find limitations of computational overloads and scalability, which requires more effective tokenization strategies.
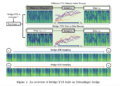
A research team from the Carnegie Mellon University, the University of Hong Kong, the University of Beijing and AMD introduced a novel tokenizer, Tokenizer of masked self -chire (maetok)To address these challenges. Maetok uses masked modeling within a self -chire frame to develop a more structured latent space while guaranteeing a high fidelity of reconstruction. The researchers designed Maetok to take advantage of the principles of masked self -employers (MAE), optimizing the balance between the quality of generation and computational efficiency.
The methodology behind Maetok implies training a self -chirer with an architecture based on the vision transformer (Vit), incorporating both a encoder and a decoder. The encoder receives an input image divided into patches and processes them together with a set of learning tokens learning. During training, a part of the entrance tokens is randomly masked, which forces the model to infer the missing data of the remaining visible regions. This mechanism improves the ability of the model to learn discriminative and semantically rich representations. In addition, an auxiliary shallow decoders predict the masked characteristics, further refining the quality of the latent space. Unlike traditional VAEs, Maetok eliminates the need for variational limitations, simplifying training while improving efficiency.
Expressive experimental evaluations were carried out to evaluate the effectiveness of Maetok. The model demonstrated an avant -garde performance at the reference points of the Imagenet generation, while significantly reducing computational requirements. Specifically, Maetok only used 128 latent chips While achieving a Generative distance of frechet start (GFID) of 1.69 for 512 × 512 Resolution images. The training was 76 times fasterAnd the inference performance was 31 times higher than conventional methods. The results showed that a latent space with fewer Gaussian mixing modes produced a lower loss of diffusion, which led to a better generative performance. The model was trained in XL with 675m parameters and surpassed the latest generation models, including those trained with VAE.
This research highlights the importance of structuring latent space effectively in diffusion models. In integrating masked modeling, the researchers achieved an optimal balance between the loyalty of the reconstruction and quality of representation, which shows that the structure of the latent space is a crucial factor in generative performance. The findings provide a solid basis for new advances in the synthesis of images based on diffusion, offering an approach that improves scalability and efficiency without sacrificing the quality of the output.
Verify he Paper and Github page. All credit for this investigation goes to the researchers of this project. Besides, don't forget to follow us <a target="_blank" href="https://x.com/intent/follow?screen_name=marktechpost” target=”_blank” rel=”noreferrer noopener”>twitter and join our Telegram channel and LINKEDIN GRsplash. Do not forget to join our 75K+ ml of submen.
<a target="_blank" href="https://x.com/i/communities/1670488129348960258″ target=”_blank” rel=”noreferrer noopener”>Unique our automatic learning community on twitter/<a target="_blank" href="https://x.com/i/communities/1670488129348960258″ target=”_blank” rel=”noreferrer noopener”>unknown
Nikhil is an internal consultant at Marktechpost. He is looking for a double degree integrated into materials at the Indian Institute of technology, Kharagpur. Nikhil is an ai/ML enthusiast who is always investigating applications in fields such as biomaterials and biomedical sciences. With a solid experience in material science, it is exploring new advances and creating opportunities to contribute.




{kind=link}