 NEWSLETTER
NEWSLETTER
Large language models are promoting a new wave of digital agents to handle sophisticated web tasks. These agents are expected to interpret the user's instructions, navigate the interfaces and execute complex commands in constantly changing environments. The difficulty is not to understand language but translate that understanding into precise and sequenced actions while adapting to dynamic contexts. The success of Horizon Long's tasks, such as reserving trips or recovering specific web data, depends on managing a sequence of steps that evolves with each action. Despite the important progress in language capabilities, creating agents that can plan and adapt effectively at each step remains an unsolved problem.
Composing general objectives in processable steps is an important problem in the construction of such agents. When a user requests “Follow the main taxpayer of this Github project”, the agent must interpret the command and determine how to navigate to the taxpayer section, identify the relevant person and start the following action. This task becomes even more complex in dynamic environments where the content can change between executions. Without a clear planning and updating strategy, agents can make inconsistent decisions or fail completely. The shortage of training data that shows how to plan and execute long tasks correctly adds another layer of difficulty.
Previously, the researchers tried to address these problems with models that were based on strategies of a single agent or the learning reinforcement to guide the actions. The single agent systems like React tried to merge the reasoning and execution, but often hesitated since the model was overwhelmed by thinking and acting at the same time. Reinforcement learning approaches were promising, but proved to be unstable and highly sensitive to the specific tuning of the environment. The collection of training data for these methods required an extensive interaction with environments, which makes it slow and not very practical at the scale. These methods also fought to maintain the consistency of performance when the tasks changed the average process.
UC Berkeley researchers, the University of Tokyo and ICSI introduced a new system of plans and acts. Companies like Apple, Nvidia, Microsoft and Intel supported the job. This framework divides the planning and execution of the task into two modules: a planner and an executor. The planner has the task of creating a structured plan based on the user's application, essentially describes what steps should be taken. The executor then translates each step into specific actions of the environment. When separating these responsibilities, the system allows the planner to focus on the strategy while the executor manages the execution, improving the reliability of both components. This modular design marks a significant change of the previous approaches.
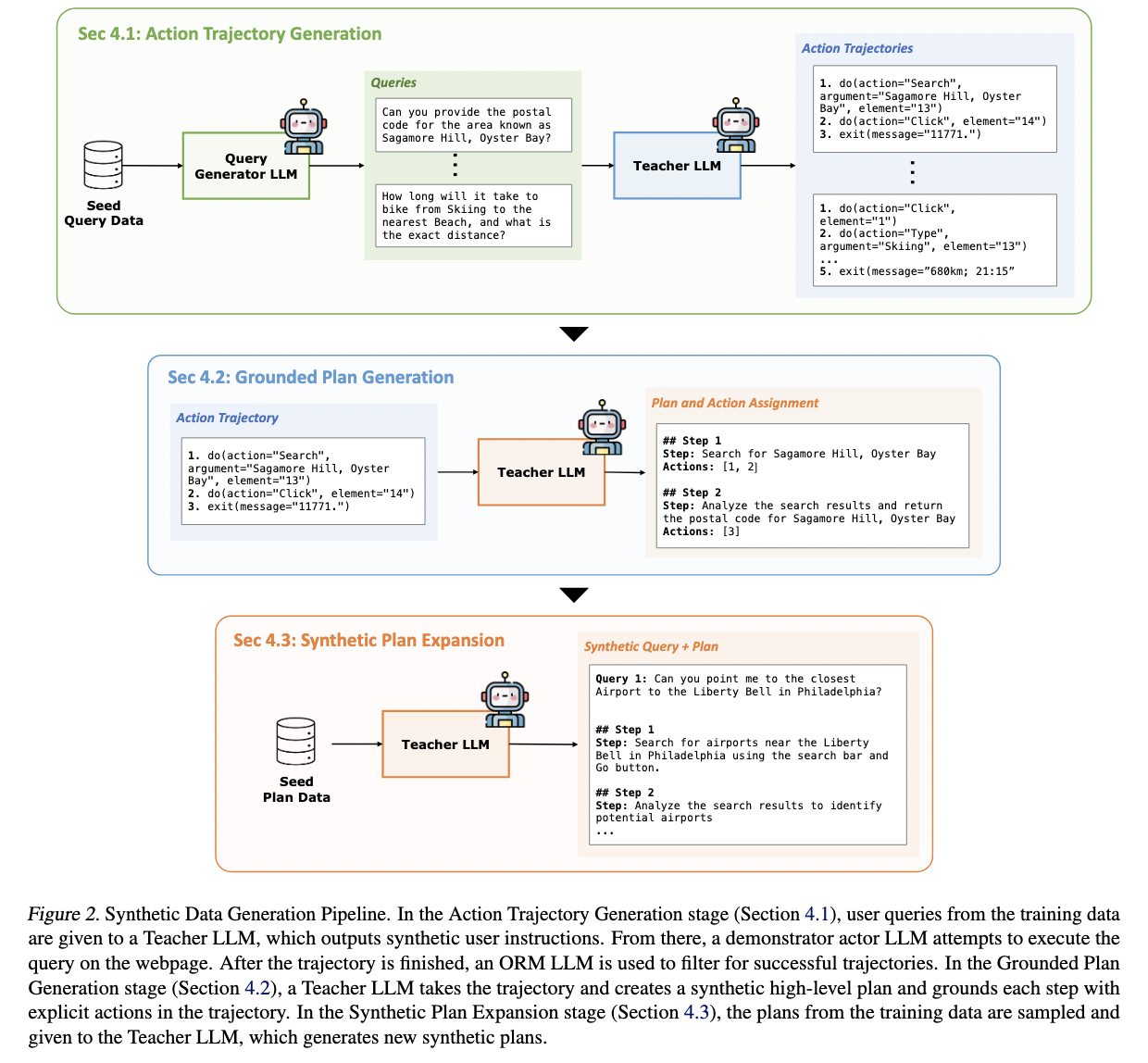
The methodology behind Plan-And-Act is detailed and focuses largely on scalable training. Since the planning data noted by humans are limited, the researchers introduced a synthetic data generation pipe. They began collecting action trajectories of simulated agents: click sequences, entries and responses. Large language models then analyzed these trajectories to rebuild high -level plans based on real results. For example, a plan could specify the superior taxpayer, while the actions related to it include clicking on the “Taxpayers” tab and analyze the resulting HTML. The team expanded its data set with 10,000 additional synthetic plans and then generated 5,000 more specific plans based on failure analysis. This synthetic training method saved time and produced high quality data that reflected the real execution needs.
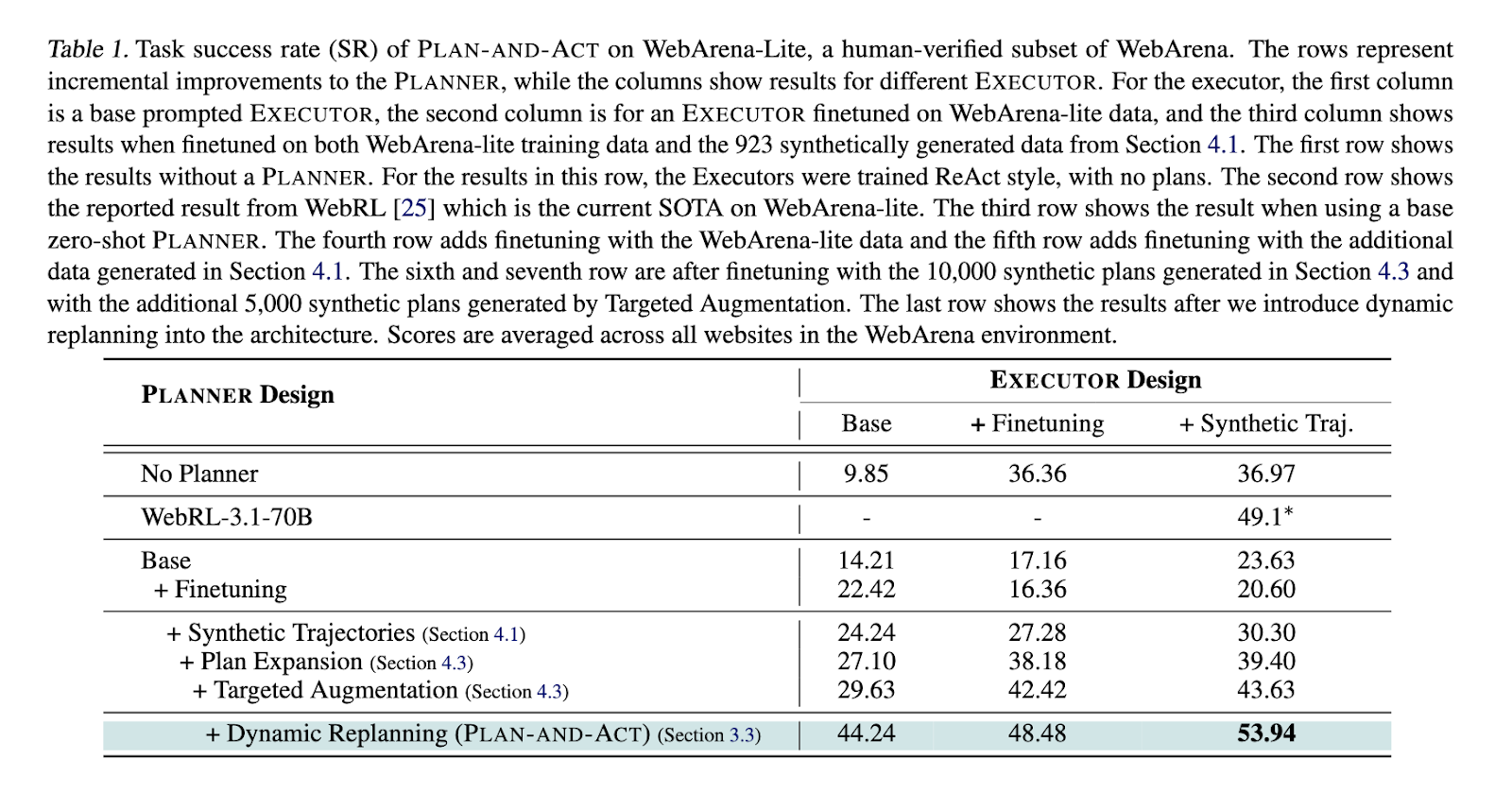
In the tests, Plan-And-Act reached a success rate of the 53.94% task at the webarena-lite reference point, exceeding the best previous result of 49.1% of Webrl. Without any planner, a base executor only achieved 9.85%. Add a non -financial planner that increased yield to 29.63%, while the delicacy of 10,000 synthetic plans raised the results of up to 44.24%. The incorporation of dynamic replacement added a final yield gain of 10.31%. In all experiments, the data showed that most performance improvements come from improving the planner instead of the executor. Even with a base albacea, having a strong planner led to substantial increases in success rates, validating the researchers' hypothesis that the separation of planning and execution produce better tasks.
In conclusion, this document highlights how to identify the gap between the understanding of the objectives and environmental interaction can lead to more effective ai systems. When focusing on structured planning and scalable data generation, researchers proposed a method that solves a specific problem and demonstrates a framework that can be extended to broader applications. Plan-And-Act shows that effective planning, not only execution, is essential for the success of the ai agent in complex environments.
Verify he Paper. All credit for this investigation goes to the researchers of this project. In addition, feel free to follow us <a target="_blank" href="https://x.com/intent/follow?screen_name=marktechpost” target=”_blank” rel=”noreferrer noopener”>twitter And don't forget to join our 85k+ ml of submen.
Nikhil is an internal consultant at Marktechpost. He is looking for a double degree integrated into materials at the Indian Institute of technology, Kharagpur. Nikhil is an ai/ML enthusiast who is always investigating applications in fields such as biomaterials and biomedical sciences. With a solid experience in material science, it is exploring new advances and creating opportunities to contribute.






{kind=link}