 NEWSLETTER
NEWSLETTER
Mathematical reasoning is the backbone of artificial intelligence and is very important in arithmetic, geometric and competitive level problems. Recently, LLMs have become very useful tools for reasoning, showing the ability to produce detailed step-by-step reasoning and present coherent explanations of complex tasks. However, due to such success, it is increasingly difficult to support these models with the necessary computational resources, making them difficult to implement in restricted environments.
An immediate challenge for researchers is to reduce the computational and memory needs of LLMs without deteriorating performance. Mathematical reasoning poses a very challenging task to maintain the need for precision and logical consistency, without which many techniques can compromise those goals. Extending the models to realistic uses is severely affected by these limitations.
Current approaches toward this challenge are pruning, knowledge distillation, and quantification. Quantization, the process of converting model weights and activations to low-bit formats, has shown promise in reducing memory consumption while improving computational efficiency. However, its impact on tasks requiring stepwise reasoning is not well understood, especially in mathematical domains. Most existing methods cannot capture the nuances of the trade-offs between efficiency and fidelity of reasoning.
A group of researchers from Hong Kong Polytechnic University, Southern University of Science and technology, Tsinghua University, Wuhan University and the University of Hong Kong developed a systematic framework for the effects of quantification on mathematical reasoning. . They used several quantification techniques, such as GPTQ and SmoothQuant, to combine and evaluate the impact of both techniques on reasoning. The team focused on the MATH benchmark, which requires step-by-step problem solving, and analyzed the performance degradation caused by these methods under different levels of precision.
The researchers used a methodology that involved training models with structured tokens and annotations. These included special markers to define the reasoning steps, ensuring that the model could retain the intermediate steps even under quantization. To reduce architectural changes to the models while applying fine-tuning techniques similar to LoRA, this adapted approach balances the trade-off of efficiency and accuracy in the implementation and the quantized model. Therefore, it provides logical coherence to the models. Similarly, the step-level correction of the PRM800K data set has been considered training data to allow for a granular set of reasoning steps that the model would learn to reproduce.
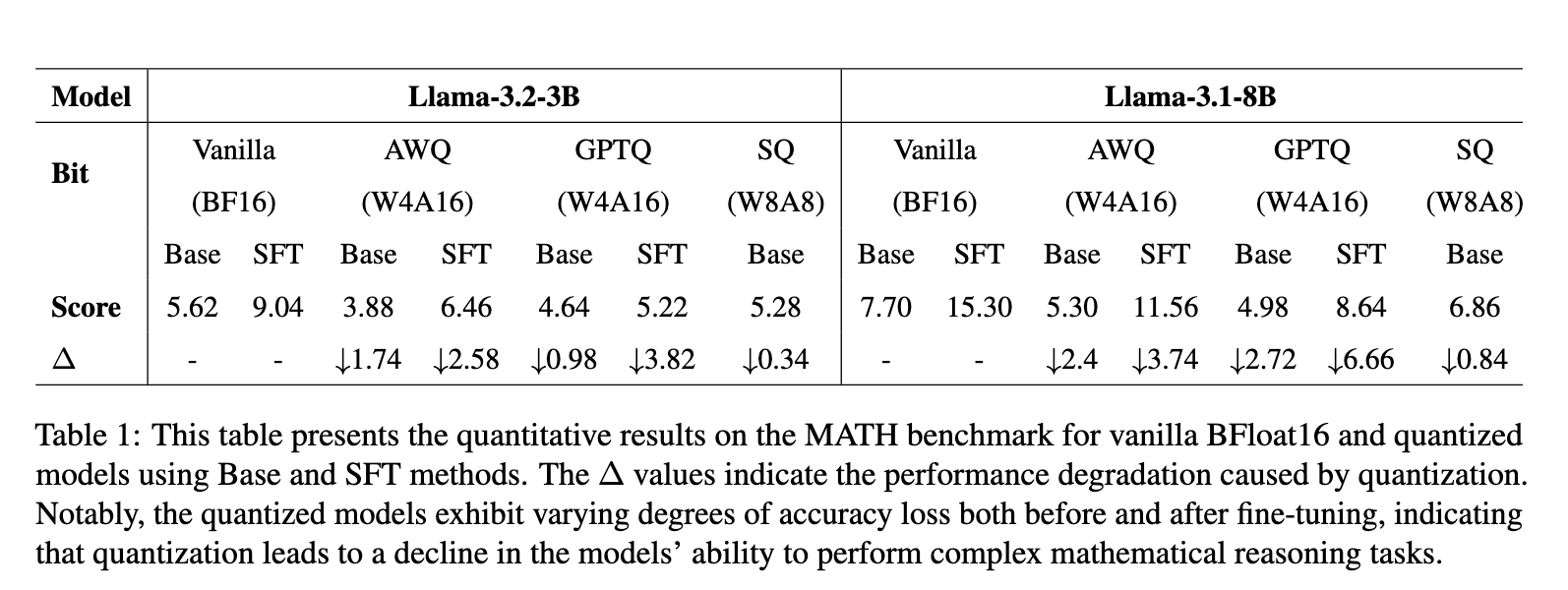
A thorough performance analysis revealed critical shortcomings of the quantized models. Quantization greatly affected compute-intensive tasks, with large performance degradations in different configurations. For example, the Llama-3.2-3B model lost accuracy, with scores dropping from 5.62 with full accuracy to 3.88 with GPTQ quantization and 4.64 with SmoothQuant. The Llama-3.1-8B model had smaller performance losses, with scores dropping from 15.30 in overall accuracy to 11.56 with GPTQ and 13.56 with SmoothQuant. SmoothQuant showed the highest robustness of all methods tested, performing better than GPTQ and AWQ. The results highlighted some of the challenges in low-bit formats, particularly maintaining numerical calculation accuracy and logical consistency.
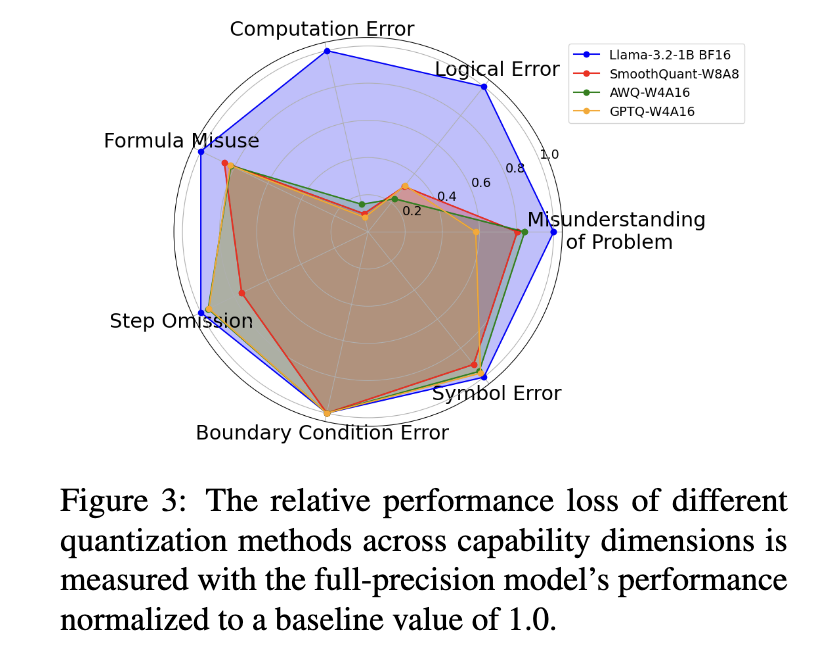
An in-depth error analysis classified the problems into calculation errors, logical errors, and step omissions. Calculation errors were the most common, often arising from low-bit precision overflow, which disrupted the accuracy of multi-step calculations. Step omissions were also common, especially in models with reduced activation precision, which failed to retain intermediate reasoning steps. Interestingly, some quantized models outperformed their full-precision counterparts on specific reasoning tasks, highlighting the nuanced effects of quantization.
The results of this study clearly illustrate the trade-offs between computational efficiency and reasoning accuracy in quantified LLMs. Although techniques like SmoothQuant help mitigate some of the performance degradation, the challenges of maintaining high-fidelity reasoning remain significant. Researchers have provided valuable insights into optimizing LLMs for resource-constrained environments by introducing structured annotations and tuning methods. These findings are critical for implementing LLM in practical applications, offering a path to balance efficiency with reasoning capabilities.
In summary, this study addresses the critical gap in understanding the effect of quantification on mathematical reasoning. The methodologies and frameworks proposed here indicate some of the shortcomings of existing quantification techniques and provide viable strategies to overcome them. These advances open paths toward more efficient and capable ai systems, narrowing the gap between theoretical potential and real-world applicability.
Verify he Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on <a target="_blank" href="https://x.com/intent/follow?screen_name=marktechpost” target=”_blank” rel=”noreferrer noopener”>twitter and join our Telegram channel and LinkedIn Grabove. Don't forget to join our SubReddit over 60,000 ml.
UPCOMING FREE ai WEBINAR (JANUARY 15, 2025): <a target="_blank" href="https://info.gretel.ai/boost-llm-accuracy-with-sd-and-evaluation-intelligence?utm_source=marktechpost&utm_medium=newsletter&utm_campaign=202501_gretel_galileo_webinar”>Increase LLM Accuracy with Synthetic Data and Assessment Intelligence–<a target="_blank" href="https://info.gretel.ai/boost-llm-accuracy-with-sd-and-evaluation-intelligence?utm_source=marktechpost&utm_medium=newsletter&utm_campaign=202501_gretel_galileo_webinar”>Join this webinar to learn practical information to improve LLM model performance and accuracy while protecting data privacy..
Nikhil is an internal consultant at Marktechpost. He is pursuing an integrated double degree in Materials at the Indian Institute of technology Kharagpur. Nikhil is an ai/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in materials science, he is exploring new advances and creating opportunities to contribute.






{kind=link}