 NEWSLETTER
NEWSLETTER
Large language models are one of the most significant advances in artificial intelligence. They are a great application of transformer models. LLMs have come a long way, from generating content and summarizing massive paragraphs to completing code and having human conversations. LLMs learn from large volumes of data that are fed into the AI model without supervision. They use the concept of deep learning and natural language processing to operate and learn the complexity of language. LLMs are transformer-based neural networks with various parameters on which model performance and output quality depend.
Transformer models are used primarily with textual data and have successfully replaced recurrent neural networks. A transformer is divided into two components: an encoder and a decoder. The job of an encoder is to take inputs in the form of tokens and generate a systematic sequence of hidden states. On the other hand, the decoder takes input from the hidden states and generates resulting tokens. The operation of the transformer can be represented by taking the example of translating a sentence from English to Spanish. The transformer takes the input of the English sentence in the form of tokens. It continues to iteratively predict the consecutive word in the language you want to translate to, i.e. Spanish in this case.
Transformer sampling mainly faces the limitation of having a constraint on memory bandwidth. An algorithm called Speculative Sampling (SpS) has been introduced to overcome the limitation, which speeds up transformer sampling. Sampling can simply be defined as an approach to choosing a subset of data from a larger data set to use as a representative sample for model training. Scale parameters have been shown to be important in improving model performance. In a transformer model, when the encoder generates a token, the time it takes to process is proportional to the first-order approximation of the parameter size and the memory bandwidth of the transformer.
 Read our latest AI newsletter
Read our latest AI newsletterIn speculative sampling, the transformer decoding process is sped up by allowing the production of multiple tokens from each transformer cell. The researchers behind the development of the algorithm have summarized the entire operation of speculative sampling as follows:
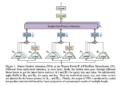
- Creating a scratch model: A small scratch of length K is produced, which is followed by calling a comparatively faster model K times, which is autoregressive.
- Using the target model: Preliminary scoring is done using the target model, which is more powerful.
- Applying a modified rejection sampling scheme: With this scheme, a subset of K draft tokens is accepted from left to right to retrieve the target model distribution.
- Multiple token generation: For a particular token or a subsequence of tokens, multiple tokens are produced each time the target model is called in case there is strong agreement between the draft distributions and the target model.
A traditional transformer model performs training and sampling using the autoregressive sampling (ArS) technique. Autoregressive sampling is a sequential procedure in which only one token is produced for each sequence in the lot. It is a memory bandwidth approach that does not use hardware accelerators such as the Graphics Processing Unit (GPU) and Tensor Processing Unit (TPU). Unlike the traditional method, speculative sampling works on the concept of producing multiple tokens each time the target model is called.
The researchers have even shared a factual study in the research paper in which a comparison has been made between speculative and autoregressive sampling. For comparison, the team used the Chinchilla Large Language Model with parameters 70B. Chinchilla is a 70B parameter model that has been trained with 1.4 trillion tokens. It has been optimally trained by scaling both the model size and the training tokens. The team performed the comparison on the 100-shot XSum and HumanEval benchmarks. The study showed that speculative sampling was able to achieve decode speedups of 2 to 2.5x in both XSum and HumanEval. It even successfully maintained sample quality without any notable alteration to architecture or parameters.
The rejection sampling scheme introduced by the team has been shown to recover the target model distribution from preliminary model samples to within hardware numerics. Upon observation and analysis, the team found that computing the logic of a small continuation of K tokens in parallel is similar in terms of latency to sampling one token from a large target model.
Long language models have progressed exponentially in the past few months, and speculative sampling looks promising. Its ability to speed up the decoding of language models is innovative and would certainly contribute greatly to the success of transformative models. One of the key features of this algorithm is that it does not require any alteration to the parameters and architecture of the target language model. It scales finely with the appropriate draft model and speeds up decoding. Therefore, speculative sampling greatly contributes to the field of artificial intelligence.
review the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 14k+ ML SubReddit, discord channel, and electronic newsletterwhere we share the latest AI research news, exciting AI projects, and more.
Tanya Malhotra is a final year student at the University of Petroleum and Power Studies, Dehradun, studying BTech in Computer Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a data science enthusiast with good analytical and critical thinking, along with a keen interest in acquiring new skills, leading groups, and managing work in an organized manner.





{kind=link}