 NEWSLETTER
NEWSLETTER
Esta publicación de blog está coescrita con Qaish Kanchwala de The Weather Company.
A medida que las industrias comienzan a adoptar procesos que dependen de las tecnologías de aprendizaje automático (ML), es fundamental establecer operaciones de aprendizaje automático (MLOps) que se escalen para respaldar el crecimiento y la utilización de esta tecnología. Los profesionales de MLOps tienen muchas opciones para establecer una plataforma MLOps; una de ellas son las plataformas integradas basadas en la nube que se escalan con los equipos de ciencia de datos. AWS ofrece una pila completa de servicios para establecer una plataforma MLOps en la nube que se pueda personalizar según sus necesidades y, al mismo tiempo, aprovechar todos los beneficios de realizar ML en la nube.
En esta publicación, compartimos la historia de cómo The Weather Company (TWCo) mejoró su plataforma MLOps utilizando servicios como amazon SageMaker, AWS CloudFormation y amazon CloudWatch. Los científicos de datos e ingenieros de ML de TWCo aprovecharon la automatización, el seguimiento detallado de experimentos, la capacitación integrada y los canales de implementación para ayudar a escalar MLOps de manera efectiva. TWCo redujo el tiempo de administración de la infraestructura en un 90 % y, al mismo tiempo, redujo el tiempo de implementación del modelo en un 20 %.
La necesidad de MLOps en TWCo
TWCo se esfuerza por ayudar a los consumidores y las empresas a tomar decisiones informadas y más seguras en función del clima. Si bien la organización ha utilizado el aprendizaje automático en su proceso de pronóstico del tiempo durante décadas para ayudar a traducir miles de millones de puntos de datos meteorológicos en pronósticos y perspectivas prácticas, se esfuerza continuamente por innovar e incorporar tecnología de vanguardia también de otras maneras. El equipo de ciencia de datos de TWCo buscaba crear modelos de aprendizaje automático predictivos y respetuosos con la privacidad que mostraran cómo las condiciones climáticas afectan ciertos síntomas de salud y crearan segmentos de usuarios para mejorar la experiencia del usuario.
TWCo buscaba escalar sus operaciones de ML con más transparencia y menos complejidad para permitir flujos de trabajo de ML más manejables a medida que su equipo de ciencia de datos crecía. Hubo desafíos notables al ejecutar flujos de trabajo de ML en la nube. El entorno de nube existente de TWCo carecía de transparencia para trabajos de ML, monitoreo y un almacén de características, lo que dificultaba la colaboración de los usuarios. Los gerentes carecían de la visibilidad necesaria para el monitoreo continuo de los flujos de trabajo de ML. Para abordar estos puntos críticos, TWCo trabajó con AWS Machine Learning Solutions Lab (MLSL) para migrar estos flujos de trabajo de ML a amazon SageMaker y la nube de AWS. El equipo de MLSL colaboró con TWCo para diseñar una plataforma MLOps para satisfacer las necesidades de su equipo de ciencia de datos, teniendo en cuenta el crecimiento presente y futuro.
Algunos ejemplos de objetivos comerciales establecidos por TWCo para esta colaboración son:
- Consiga una reacción más rápida al mercado y ciclos de desarrollo de ML más rápidos
- Acelere la migración de TWCo de sus cargas de trabajo de ML a SageMaker
- Mejorar la experiencia del usuario final mediante la adopción de servicios de gestión
- Reducir el tiempo que los ingenieros dedican al mantenimiento y conservación de la infraestructura de ML subyacente
Se establecieron objetivos funcionales para medir el impacto de los usuarios de la plataforma MLOps, entre ellos:
- Mejorar la eficiencia del equipo de ciencia de datos en las tareas de entrenamiento de modelos
- Reducir la cantidad de pasos necesarios para implementar nuevos modelos
- Reducir el tiempo de ejecución de la canalización del modelo de extremo a extremo
Descripción general de la solución
La solución utiliza los siguientes servicios de AWS:
- AWS CloudFormation: servicio de infraestructura como código (IaC) para aprovisionar la mayoría de las plantillas y activos.
- AWS CloudTrail: supervisa y registra la actividad de la cuenta en toda la infraestructura de AWS.
- amazon CloudWatch: recopila y visualiza registros en tiempo real que proporcionan la base para la automatización.
- AWS CodeBuild: servicio de integración continua totalmente administrado para compilar código fuente, ejecutar pruebas y producir software listo para implementar. Se utiliza para implementar código de inferencia y entrenamiento.
- AWS CodeCommit: repositorio de control de origen administrado que almacena el código de infraestructura MLOps y el código IaC.
- AWS CodePipeline: servicio de entrega continua totalmente administrado que ayuda a automatizar la publicación de pipelines.
- amazon SageMaker: plataforma de ML completamente administrada para realizar flujos de trabajo de ML a partir de la exploración de datos, el entrenamiento y la implementación de modelos.
- Catálogo de servicios de AWS: administra de forma centralizada los recursos de la nube, como las plantillas IaC utilizadas para proyectos MLOps.
- amazon Simple Storage Service (amazon S3): almacenamiento de objetos en la nube para almacenar datos para capacitación y pruebas.
El siguiente diagrama ilustra la arquitectura de la solución.
Esta arquitectura consta de dos canales principales:
- Canal de formación – El canal de entrenamiento está diseñado para funcionar con características y etiquetas almacenadas como un archivo con formato CSV en amazon S3. Incluye varios componentes, incluidos Preprocess, Train y Evaluate. Después de entrenar el modelo, sus artefactos asociados se registran en amazon SageMaker Model Registry a través del componente Register Model. La parte Data Quality Check del canal crea estadísticas de referencia para la tarea de monitoreo en el canal de inferencia.
- Canalización de inferencia – El canal de inferencia se encarga de las tareas de inferencia y supervisión por lotes a pedido. En este canal, se incorporan los pasos de SageMaker On-Demand Data Quality Monitor para detectar cualquier desviación en comparación con los datos de entrada. Los resultados de la supervisión se almacenan en amazon S3 y se publican como una métrica de CloudWatch., y se puede utilizar para configurar una alarma. La alarma se utiliza más tarde para invocar un entrenamiento, enviar correos electrónicos automáticos o cualquier otra acción deseada.
La arquitectura MLOps propuesta incluye flexibilidad para admitir distintos casos de uso, así como la colaboración entre distintas personas del equipo, como científicos de datos e ingenieros de ML. La arquitectura reduce la fricción entre equipos multifuncionales que trasladan modelos a producción.
La experimentación con modelos de ML es uno de los subcomponentes de la arquitectura MLOps. Mejora la productividad de los científicos de datos y los procesos de desarrollo de modelos. Los ejemplos de experimentación con modelos en servicios de SageMaker relacionados con MLOps requieren funciones como amazon SageMaker Pipelines, amazon SageMaker Feature Store y SageMaker Model Registry mediante el uso de las bibliotecas SageMaker SDK y AWS Boto3.
Al configurar pipelines, se crean recursos que son necesarios durante todo el ciclo de vida del pipeline. Además, cada pipeline puede generar sus propios recursos.
Los recursos de configuración de la tubería son:
- Proceso de formación:
- Canalización de SageMaker
- Grupo de modelos del Registro de modelos de SageMaker
- Espacio de nombres de CloudWatch
- Canalización de inferencia:
Los recursos de ejecución del pipeline son:
Debes eliminar estos recursos cuando las canalizaciones caduquen o ya no sean necesarias.
Plantilla de proyecto de SageMaker
En esta sección, analizamos el aprovisionamiento manual de pipelines a través de un notebook de ejemplo y el aprovisionamiento automático de pipelines de SageMaker mediante el uso de un producto de Service Catalog y un proyecto de SageMaker.
Al utilizar amazon SageMaker Projects y su poderoso enfoque basado en plantillas, las organizaciones establecen una infraestructura estandarizada y escalable para el desarrollo de ML, lo que permite a los equipos concentrarse en construir e iterar modelos de ML, reduciendo el tiempo perdido en configuraciones y administración complejas.
El siguiente diagrama muestra los componentes necesarios de una plantilla de proyecto de SageMaker. Utilice Service Catalog para registrar una plantilla de proyecto de SageMaker CloudFormation en la cartera de Service Catalog de su organización.
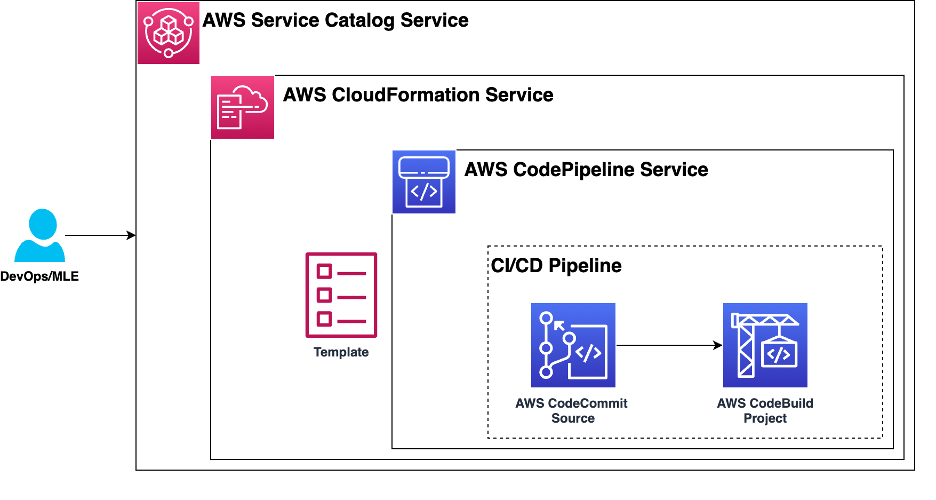
Para iniciar el flujo de trabajo de ML, la plantilla de proyecto sirve como base al definir un flujo de trabajo de integración y entrega continuas (CI/CD). Comienza recuperando el código semilla de ML de un repositorio de CodeCommit. Luego, el componente BuildProject asume el control y organiza el aprovisionamiento de los flujos de trabajo de inferencia y capacitación de SageMaker. Esta automatización ofrece una ejecución fluida y eficiente del flujo de trabajo de ML, lo que reduce la intervención manual y acelera el proceso de implementación.
Dependencias
La solución tiene las siguientes dependencias:
- SDK de amazon SageMaker – El SDK de Python para amazon SageMaker es una biblioteca de código abierto para entrenar e implementar modelos de aprendizaje automático en SageMaker. Para esta prueba de concepto, se configuraron canales utilizando este SDK.
- Kit de desarrollo de software de Boto3 – El SDK de AWS para Python (Boto3) proporciona una API de Python para los servicios de infraestructura de AWS. Usamos el SDK para Python para crear roles y aprovisionar recursos del SDK de SageMaker.
- Proyectos de SageMaker – SageMaker Projects ofrece una infraestructura y plantillas estandarizadas para MLOps para una iteración rápida en múltiples casos de uso de ML.
- Catálogo de servicios – El catálogo de servicios simplifica y acelera el proceso de aprovisionamiento de recursos a gran escala. Ofrece un portal de autoservicio, un catálogo de servicios estandarizado, gestión de versiones y ciclo de vida, y control de acceso.
Conclusión
En esta publicación, mostramos cómo TWCo usa SageMaker, CloudWatch, CodePipeline y CodeBuild para su plataforma MLOps. Con estos servicios, TWCo amplió las capacidades de su equipo de ciencia de datos y, al mismo tiempo, mejoró la forma en que los científicos de datos administran los flujos de trabajo de ML. Estos modelos de ML finalmente ayudaron a TWCo a crear experiencias predictivas y respetuosas con la privacidad que mejoraron la experiencia del usuario y explican cómo las condiciones climáticas afectan la planificación diaria o las operaciones comerciales de los consumidores. También revisamos el diseño de la arquitectura que ayuda a mantener las responsabilidades entre los diferentes usuarios modularizadas. Por lo general, los científicos de datos solo se preocupan por el aspecto científico de los flujos de trabajo de ML, mientras que los ingenieros de DevOps y ML se centran en los entornos de producción. TWCo redujo el tiempo de gestión de la infraestructura en un 90% y, al mismo tiempo, redujo el tiempo de implementación del modelo en un 20%.
Esta es solo una de las muchas formas en que AWS permite a los desarrolladores ofrecer excelentes soluciones. Le recomendamos que comience a utilizar amazon SageMaker hoy mismo.
Sobre los autores
 Qaish Kanchwala Qaish es gerente de ingeniería de aprendizaje automático y arquitecto de aprendizaje automático en The Weather Company. Ha trabajado en cada paso del ciclo de vida del aprendizaje automático y diseña sistemas para permitir casos de uso de IA. En su tiempo libre, a Qaish le gusta cocinar platos nuevos y ver películas.
Qaish Kanchwala Qaish es gerente de ingeniería de aprendizaje automático y arquitecto de aprendizaje automático en The Weather Company. Ha trabajado en cada paso del ciclo de vida del aprendizaje automático y diseña sistemas para permitir casos de uso de IA. En su tiempo libre, a Qaish le gusta cocinar platos nuevos y ver películas.
 Chezsal Kamaray es arquitecta de soluciones sénior en el sector vertical de alta tecnología de amazon Web Services. Trabaja con clientes empresariales y los ayuda a acelerar y optimizar la migración de su carga de trabajo a la nube de AWS. Le apasiona la gestión y la gobernanza en la nube y ayudar a los clientes a configurar una zona de aterrizaje orientada al éxito a largo plazo. En su tiempo libre, trabaja la madera y prueba nuevas recetas mientras escucha música.
Chezsal Kamaray es arquitecta de soluciones sénior en el sector vertical de alta tecnología de amazon Web Services. Trabaja con clientes empresariales y los ayuda a acelerar y optimizar la migración de su carga de trabajo a la nube de AWS. Le apasiona la gestión y la gobernanza en la nube y ayudar a los clientes a configurar una zona de aterrizaje orientada al éxito a largo plazo. En su tiempo libre, trabaja la madera y prueba nuevas recetas mientras escucha música.
 Anila Joshi Tiene más de una década de experiencia en la creación de soluciones de IA. Como gerente de ciencias aplicadas en el Centro de innovación de IA generativa de AWS, Anila es pionera en aplicaciones innovadoras de IA que amplían los límites de lo posible y guían a los clientes para trazar estratégicamente un rumbo hacia el futuro de la IA.
Anila Joshi Tiene más de una década de experiencia en la creación de soluciones de IA. Como gerente de ciencias aplicadas en el Centro de innovación de IA generativa de AWS, Anila es pionera en aplicaciones innovadoras de IA que amplían los límites de lo posible y guían a los clientes para trazar estratégicamente un rumbo hacia el futuro de la IA.
 Kamran Razi Kamran es ingeniero de aprendizaje automático en el Centro de innovación de inteligencia artificial generativa de amazon. Con pasión por crear soluciones basadas en casos de uso, ayuda a los clientes a aprovechar todo el potencial de los servicios de inteligencia artificial y aprendizaje automático de AWS para abordar desafíos comerciales del mundo real. Con una década de experiencia como desarrollador de software, ha perfeccionado su experiencia en diversas áreas como sistemas integrados, soluciones de ciberseguridad y sistemas de control industrial. Kamran tiene un doctorado en Ingeniería eléctrica de la Queen's University.
Kamran Razi Kamran es ingeniero de aprendizaje automático en el Centro de innovación de inteligencia artificial generativa de amazon. Con pasión por crear soluciones basadas en casos de uso, ayuda a los clientes a aprovechar todo el potencial de los servicios de inteligencia artificial y aprendizaje automático de AWS para abordar desafíos comerciales del mundo real. Con una década de experiencia como desarrollador de software, ha perfeccionado su experiencia en diversas áreas como sistemas integrados, soluciones de ciberseguridad y sistemas de control industrial. Kamran tiene un doctorado en Ingeniería eléctrica de la Queen's University.
 Shuja Sohrawardy Shuja es gerente sénior en el Centro de innovación de inteligencia artificial generativa de AWS. Durante más de 20 años, Shuja ha utilizado su perspicacia en tecnología y servicios financieros para transformar las empresas de servicios financieros y enfrentar los desafíos de una industria altamente competitiva y regulada. Durante los últimos 4 años en AWS, Shuja ha utilizado su profundo conocimiento en aprendizaje automático, resiliencia y estrategias de adopción de la nube, lo que ha dado como resultado numerosos viajes de éxito de clientes. Shuja tiene una licenciatura en Ciencias de la Computación y Economía de la Universidad de Nueva York y una maestría en Gestión de Tecnología Ejecutiva de la Universidad de Columbia.
Shuja Sohrawardy Shuja es gerente sénior en el Centro de innovación de inteligencia artificial generativa de AWS. Durante más de 20 años, Shuja ha utilizado su perspicacia en tecnología y servicios financieros para transformar las empresas de servicios financieros y enfrentar los desafíos de una industria altamente competitiva y regulada. Durante los últimos 4 años en AWS, Shuja ha utilizado su profundo conocimiento en aprendizaje automático, resiliencia y estrategias de adopción de la nube, lo que ha dado como resultado numerosos viajes de éxito de clientes. Shuja tiene una licenciatura en Ciencias de la Computación y Economía de la Universidad de Nueva York y una maestría en Gestión de Tecnología Ejecutiva de la Universidad de Columbia.
 Francisco Calderón es un científico de datos en el Centro de Innovación en IA Generativa (GAIIC). Como miembro del GAIIC, ayuda a descubrir el arte de lo posible con los clientes de AWS utilizando tecnologías de IA generativa. En su tiempo libre, a Francisco le gusta tocar música y la guitarra, jugar al fútbol con sus hijas y disfrutar del tiempo con su familia.
Francisco Calderón es un científico de datos en el Centro de Innovación en IA Generativa (GAIIC). Como miembro del GAIIC, ayuda a descubrir el arte de lo posible con los clientes de AWS utilizando tecnologías de IA generativa. En su tiempo libre, a Francisco le gusta tocar música y la guitarra, jugar al fútbol con sus hijas y disfrutar del tiempo con su familia.





{kind=link}